 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeCross-talk based multi-task learning for fault classification of physically coupled machine system
Feb 05, 2026Machine systems inherently generate signals in which fault conditions and various physical variables are physically coupled. Although many existing fault classification studies rely solely on direct fault labels, the aforementioned signals naturally embed additional information shaped by other physically coupled information. Herein, we leverage this coupling through a multi-task learning (MTL) framework that jointly learns fault conditions and the related physical variables. Among MTL architectures, crosstalk structures have distinct advantages because they allow for controlled information exchange between tasks through the cross-talk layer while preventing negative transfer, in contrast to shared trunk architectures that often mix incompatible features. We build on our previously introduced residual neural dimension reductor model, and extend its application to two benchmarks where physical coupling is prominent. The first benchmark is a drone fault dataset, in which machine type and maneuvering direction significantly alter the frequency components of measured signals even under the same nominal condition. By learning fault classification together with these physical attributes, the cross-talk architecture can better classify faults. The second benchmark dataset is the motor compound fault dataset. In this system, each fault component, inner race fault, outer race fault, misalignment, and unbalance is coupled to the other. For motor compound fault, we also test classification performance when we use single-channel data or multi-channel data as input to the classifier. Across both benchmarks, our residual neural dimension reductor, consistently outperformed single-task models, multi-class models that merge all label combinations, and shared trunk multi-task models.
Binaural Sound Event Localization and Detection based on HRTF Cues for Humanoid Robots
Jul 28, 2025This paper introduces Binaural Sound Event Localization and Detection (BiSELD), a task that aims to jointly detect and localize multiple sound events using binaural audio, inspired by the spatial hearing mechanism of humans. To support this task, we present a synthetic benchmark dataset, called the Binaural Set, which simulates realistic auditory scenes using measured head-related transfer functions (HRTFs) and diverse sound events. To effectively address the BiSELD task, we propose a new input feature representation called the Binaural Time-Frequency Feature (BTFF), which encodes interaural time difference (ITD), interaural level difference (ILD), and high-frequency spectral cues (SC) from binaural signals. BTFF is composed of eight channels, including left and right mel-spectrograms, velocity-maps, SC-maps, and ITD-/ILD-maps, designed to cover different spatial cues across frequency bands and spatial axes. A CRNN-based model, BiSELDnet, is then developed to learn both spectro-temporal patterns and HRTF-based localization cues from BTFF. Experiments on the Binaural Set show that each BTFF sub-feature enhances task performance: V-map improves detection, ITD-/ILD-maps enable accurate horizontal localization, and SC-map captures vertical spatial cues. The final system achieves a SELD error of 0.110 with 87.1% F-score and 4.4{\deg} localization error, demonstrating the effectiveness of the proposed framework in mimicking human-like auditory perception.
Multi-output Classification using a Cross-talk Architecture for Compound Fault Diagnosis of Motors in Partially Labeled Condition
May 29, 2025The increasing complexity of rotating machinery and the diversity of operating conditions, such as rotating speed and varying torques, have amplified the challenges in fault diagnosis in scenarios requiring domain adaptation, particularly involving compound faults. This study addresses these challenges by introducing a novel multi-output classification (MOC) framework tailored for domain adaptation in partially labeled (PL) target datasets. Unlike conventional multi-class classification (MCC) approaches, the proposed MOC framework classifies the severity levels of compound faults simultaneously. Furthermore, we explore various single-task and multi-task architectures applicable to the MOC formulation-including shared trunk and cross-talk-based designs-for compound fault diagnosis under PL conditions. Based on this investigation, we propose a novel cross-talk layer structure that enables selective information sharing across diagnostic tasks, effectively enhancing classification performance in compound fault scenarios. In addition, frequency-layer normalization was incorporated to improve domain adaptation performance on motor vibration data. Compound fault conditions were implemented using a motor-based test setup, and the proposed model was evaluated across six domain adaptation scenarios. The experimental results demonstrate its superior macro F1 performance compared to baseline models. We further showed that the proposed mode's structural advantage is more pronounced in compound fault settings through a single-fault comparison. We also found that frequency-layer normalization fits the fault diagnosis task better than conventional methods. Lastly, we discuss that this improvement primarily stems from the model's structural ability to leverage inter-fault classification task interactions, rather than from a simple increase in model parameters.
DNN based HRIRs Identification with a Continuously Rotating Speaker Array
Apr 21, 2025Conventional static measurement of head-related impulse responses (HRIRs) is time-consuming due to the need for repositioning a speaker array for each azimuth angle. Dynamic approaches using analytical models with a continuously rotating speaker array have been proposed, but their accuracy is significantly reduced at high rotational speeds. To address this limitation, we propose a DNN-based HRIRs identification using sequence-to-sequence learning. The proposed DNN model incorporates fully connected (FC) networks to effectively capture HRIR transitions and includes reset and update gates to identify HRIRs over a whole sequence. The model updates the HRIRs vector coefficients based on the gradient of the instantaneous square error (ISE). Additionally, we introduce a learnable normalization process based on the speaker excitation signals to stabilize the gradient scale of ISE across time. A training scheme, referred to as whole-sequence updating and optimization scheme, is also introduced to prevent overfitting. We evaluated the proposed method through simulations and experiments. Simulation results using the FABIAN database show that the proposed method outperforms previous analytic models, achieving over 7 dB improvement in normalized misalignment (NM) and maintaining log spectral distortion (LSD) below 2 dB at a rotational speed of 45{\deg}/s. Experimental results with a custom-built speaker array confirm that the proposed method successfully preserved accurate sound localization cues, consistent with those from static measurement. Source code is available at https://github.com/byko0810/DNN-based-HRIRs-identification
Temporal Attention Pooling for Frequency Dynamic Convolution in Sound Event Detection
Apr 17, 2025Recent advances in deep learning, particularly frequency dynamic convolution (FDY conv), have significantly improved sound event detection (SED) by enabling frequency-adaptive feature extraction. However, FDY conv relies on temporal average pooling, which treats all temporal frames equally, limiting its ability to capture transient sound events such as alarm bells, door knocks, and speech plosives. To address this limitation, we propose temporal attention pooling frequency dynamic convolution (TFD conv) to replace temporal average pooling with temporal attention pooling (TAP). TAP adaptively weights temporal features through three complementary mechanisms: time attention pooling (TA) for emphasizing salient features, velocity attention pooling (VA) for capturing transient changes, and conventional average pooling for robustness to stationary signals. Ablation studies show that TFD conv improves average PSDS1 by 3.02% over FDY conv with only a 14.8% increase in parameter count. Classwise ANOVA and Tukey HSD analysis further demonstrate that TFD conv significantly enhances detection performance for transient-heavy events, outperforming existing FDY conv models. Notably, TFD conv achieves a maximum PSDS1 score of 0.456, surpassing previous state-of-the-art SED systems. We also explore the compatibility of TAP with other FDY conv variants, including dilated FDY conv (DFD conv), partial FDY conv (PFD conv), and multi-dilated FDY conv (MDFD conv). Among these, the integration of TAP with MDFD conv achieves the best result with a PSDS1 score of 0.459, validating the complementary strengths of temporal attention and multi-scale frequency adaptation. These findings establish TFD conv as a powerful and generalizable framework for enhancing both transient sensitivity and overall feature robustness in SED.
Multi-output Classification Framework and Frequency Layer Normalization for Compound Fault Diagnosis in Motor
Apr 15, 2025This work introduces a multi-output classification (MOC) framework designed for domain adaptation in fault diagnosis, particularly under partially labeled (PL) target domain scenarios and compound fault conditions in rotating machinery. Unlike traditional multi-class classification (MCC) methods that treat each fault combination as a distinct class, the proposed approach independently estimates the severity of each fault type, improving both interpretability and diagnostic accuracy. The model incorporates multi-kernel maximum mean discrepancy (MK-MMD) and entropy minimization (EM) losses to facilitate feature transfer from the source to the target domain. In addition, frequency layer normalization (FLN) is applied to preserve structural properties in the frequency domain, which are strongly influenced by system dynamics and are often stationary with respect to changes in rpm. Evaluations across six domain adaptation cases with PL data demonstrate that MOC outperforms baseline models in macro F1 score. Moreover, MOC consistently achieves better classification performance for individual fault types, and FLN shows superior adaptability compared to other normalization techniques.
Multi-output Classification for Compound Fault Diagnosis in Motor under Partially Labeled Target Domain
Mar 15, 2025This study presents a novel multi-output classification (MOC) framework designed for domain adaptation in fault diagnosis, addressing challenges posed by partially labeled (PL) target domain dataset and coexisting faults in rotating machinery. Unlike conventional multi-class classification (MCC) approaches, the MOC framework independently classifies the severity of each fault, enhancing diagnostic accuracy. By integrating multi-kernel maximum mean discrepancy loss (MKMMD) and entropy minimization loss (EM), the proposed method improves feature transferability between source and target domains, while frequency layer normalization (FLN) effectively handles stationary vibration signals by leveraging mechanical characteristics. Experimental evaluations across six domain adaptation cases, encompassing partially labeled (PL) scenarios, demonstrate the superior performance of the MOC approach over baseline methods in terms of macro F1 score.
JiTTER: Jigsaw Temporal Transformer for Event Reconstruction for Self-Supervised Sound Event Detection
Feb 28, 2025Sound event detection (SED) has significantly benefited from self-supervised learning (SSL) approaches, particularly masked audio transformer for SED (MAT-SED), which leverages masked block prediction to reconstruct missing audio segments. However, while effective in capturing global dependencies, masked block prediction disrupts transient sound events and lacks explicit enforcement of temporal order, making it less suitable for fine-grained event boundary detection. To address these limitations, we propose JiTTER (Jigsaw Temporal Transformer for Event Reconstruction), an SSL framework designed to enhance temporal modeling in transformer-based SED. JiTTER introduces a hierarchical temporal shuffle reconstruction strategy, where audio sequences are randomly shuffled at both the block-level and frame-level, forcing the model to reconstruct the correct temporal order. This pretraining objective encourages the model to learn both global event structures and fine-grained transient details, improving its ability to detect events with sharp onset-offset characteristics. Additionally, we incorporate noise injection during block shuffle, providing a subtle perturbation mechanism that further regularizes feature learning and enhances model robustness. Experimental results on the DESED dataset demonstrate that JiTTER outperforms MAT-SED, achieving a 5.89% improvement in PSDS, highlighting the effectiveness of explicit temporal reasoning in SSL-based SED. Our findings suggest that structured temporal reconstruction tasks, rather than simple masked prediction, offer a more effective pretraining paradigm for sound event representation learning.
Towards Understanding of Frequency Dependence on Sound Event Detection
Feb 11, 2025In this work, various analysis methods are conducted on frequency-dependent methods on SED to further delve into their detailed characteristics and behaviors on SED. While SED has been rapidly advancing through the adoption of various deep learning techniques from other pattern recognition fields, these techniques are often not suitable for SED. To address this issue, two frequency-dependent SED methods were previously proposed: FilterAugment, a data augmentation randomly weighting frequency bands, and frequency dynamic convolution (FDY Conv), an architecture applying frequency adaptive convolution kernels. These methods have demonstrated superior performance in SED, and we aim to further analyze their detailed effectiveness and characteristics in SED. We compare class-wise performance to find out specific pros and cons of FilterAugment and FDY Conv. We apply Gradient-weighted Class Activation Mapping (Grad-CAM), which highlights time-frequency region that is more inferred by the model, on SED models with and without frequency masking and two types of FilterAugment to observe their detailed characteristics. We propose simpler frequency dependent convolution methods and compare them with FDY Conv to further understand which components of FDY Conv affects SED performance. Lastly, we apply PCA to show how FDY Conv adapts dynamic kernel across frequency dimensions on different sound event classes. The results and discussions demonstrate that frequency dependency plays a significant role in sound event detection and further confirms the effectiveness of frequency dependent methods on SED.
Performance Metric for Multiple Anomaly Score Distributions with Discrete Severity Levels
Aug 09, 2024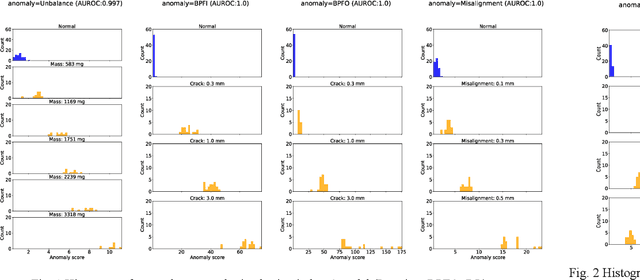
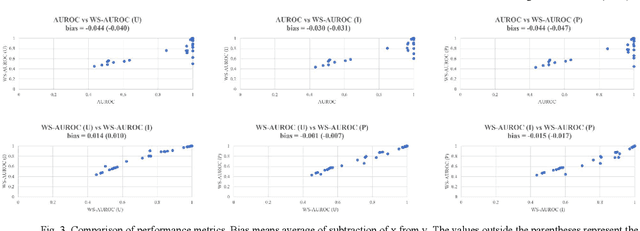
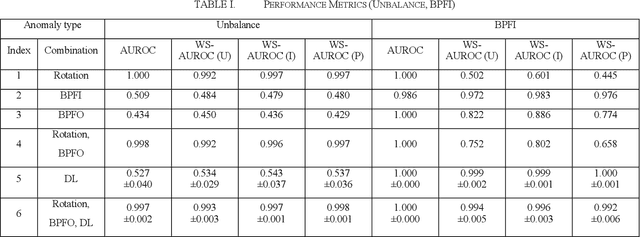
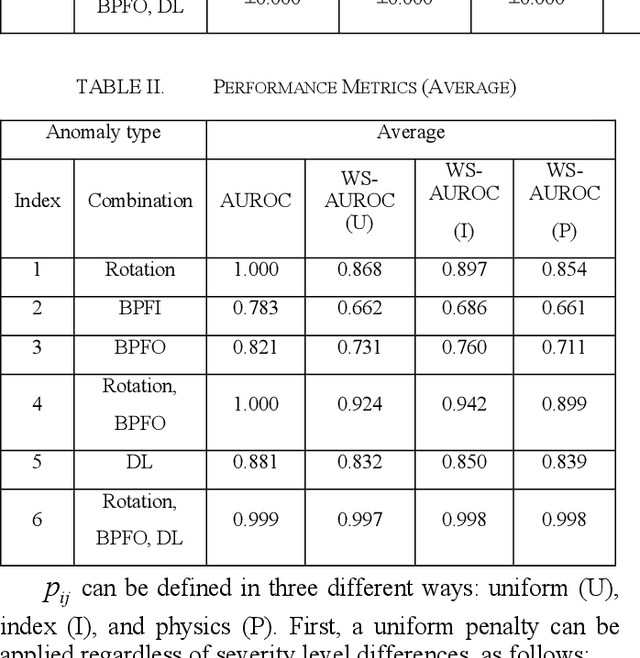
The rise of smart factories has heightened the demand for automated maintenance, and normal-data-based anomaly detection has proved particularly effective in environments where anomaly data are scarce. This method, which does not require anomaly data during training, has prompted researchers to focus not only on detecting anomalies but also on classifying severity levels by using anomaly scores. However, the existing performance metrics, such as the area under the receiver operating characteristic curve (AUROC), do not effectively reflect the performance of models in classifying severity levels based on anomaly scores. To address this limitation, we propose the weighted sum of the area under the receiver operating characteristic curve (WS-AUROC), which combines AUROC with a penalty for severity level differences. We conducted various experiments using different penalty assignment methods: uniform penalty regardless of severity level differences, penalty based on severity level index differences, and penalty based on actual physical quantities that cause anomalies. The latter method was the most sensitive. Additionally, we propose an anomaly detector that achieves clear separation of distributions and outperforms the ablation models on the WS-AUROC and AUROC metrics.