 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeBinaural Sound Event Localization and Detection based on HRTF Cues for Humanoid Robots
Jul 28, 2025This paper introduces Binaural Sound Event Localization and Detection (BiSELD), a task that aims to jointly detect and localize multiple sound events using binaural audio, inspired by the spatial hearing mechanism of humans. To support this task, we present a synthetic benchmark dataset, called the Binaural Set, which simulates realistic auditory scenes using measured head-related transfer functions (HRTFs) and diverse sound events. To effectively address the BiSELD task, we propose a new input feature representation called the Binaural Time-Frequency Feature (BTFF), which encodes interaural time difference (ITD), interaural level difference (ILD), and high-frequency spectral cues (SC) from binaural signals. BTFF is composed of eight channels, including left and right mel-spectrograms, velocity-maps, SC-maps, and ITD-/ILD-maps, designed to cover different spatial cues across frequency bands and spatial axes. A CRNN-based model, BiSELDnet, is then developed to learn both spectro-temporal patterns and HRTF-based localization cues from BTFF. Experiments on the Binaural Set show that each BTFF sub-feature enhances task performance: V-map improves detection, ITD-/ILD-maps enable accurate horizontal localization, and SC-map captures vertical spatial cues. The final system achieves a SELD error of 0.110 with 87.1% F-score and 4.4{\deg} localization error, demonstrating the effectiveness of the proposed framework in mimicking human-like auditory perception.
HRTF measurement for accurate sound localization cues
Apr 06, 2022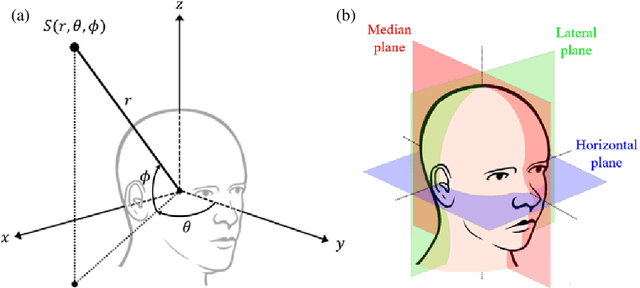
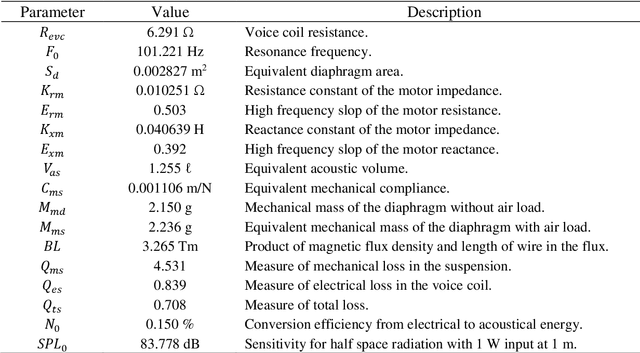
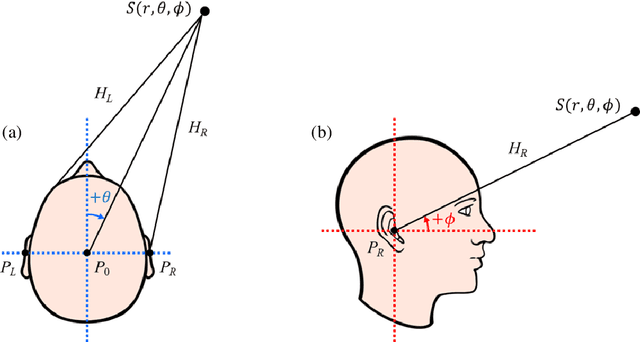
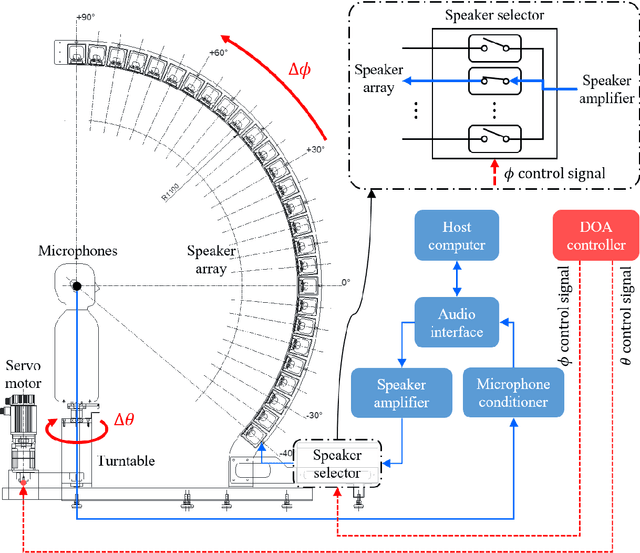
A new database of head-related transfer functions (HRTFs) for accurate sound source localization is presented through precise measurement and post-processing in terms of improved frequency bandwidth and causality of head-related impulse responses (HRIRs) for accurate spectral cue (SC) and interaural time difference (ITD), respectively. The improvement effects of the proposed methods on binaural sound localization cues were investigated. To achieve sufficient frequency bandwidth with a single source, a one-way sealed speaker module was designed to obtain wide band frequency response based on electro-acoustics, whereas most existing HRTF databases rely on a two-way vented loudspeaker that has multiple sources. The origin transfer function at the head center was obtained by the proposed measurement scheme using a 0 degree on-axis microphone to ensure accurate spectral cue pattern of HRTFs, whereas in the previous measurements with a 90 degree off-axis microphone, the magnitude response of the origin transfer function fluctuated and decreased with increasing frequency, causing erroneous SCs of HRTFs. To prevent discontinuity of ITD due to non-causality of ipsilateral HRTFs, obtained HRIRs were circularly shifted by time delay considering the head radius of the measurement subject. Finally, various sound localization cues such as ITD, interaural level difference (ILD), SC, and horizontal plane directivity (HPD) were derived from the presented HRTFs, and improvements on binaural sound localization cues were examined. As a result, accurate SC patterns of HRTFs were confirmed through the proposed measurement scheme using the 0 degree on-axis microphone, and continuous ITD patterns were obtained due to the non-causality compensation. Source codes and presented HRTF database are available to relevant research groups at GitHub (https://github.com/han-saram/HRTF-HATS-KAIST).
Deep learning based cough detection camera using enhanced features
Jul 28, 2021
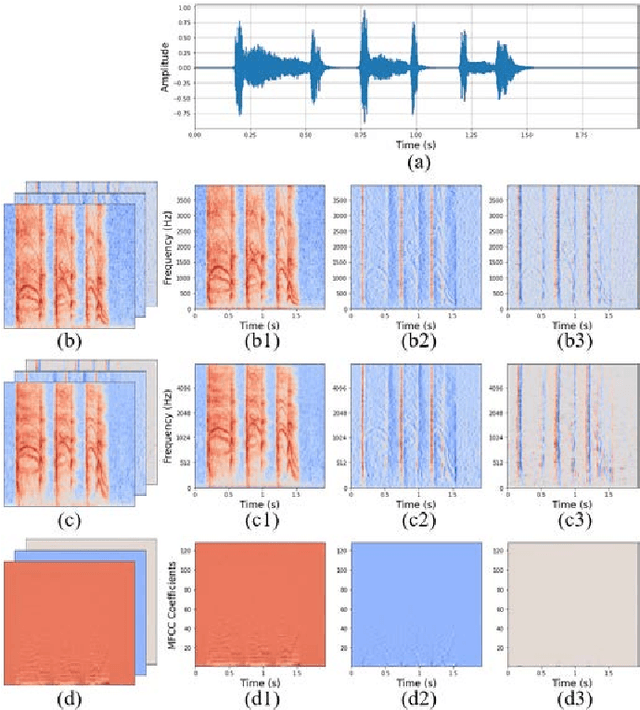

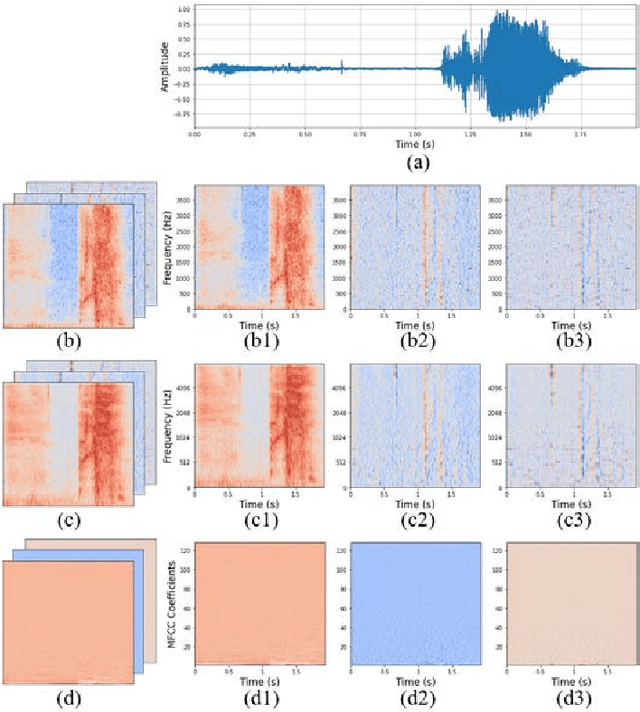
Coughing is a typical symptom of COVID-19. To detect and localize coughing sounds remotely, a convolutional neural network (CNN) based deep learning model was developed in this work and integrated with a sound camera for the visualization of the cough sounds. The cough detection model is a binary classifier of which the input is a two second acoustic feature and the output is one of two inferences (Cough or Others). Data augmentation was performed on the collected audio files to alleviate class imbalance and reflect various background noises in practical environments. For effective featuring of the cough sound, conventional features such as spectrograms, mel-scaled spectrograms, and mel-frequency cepstral coefficients (MFCC) were reinforced by utilizing their velocity (V) and acceleration (A) maps in this work. VGGNet, GoogLeNet, and ResNet were simplified to binary classifiers, and were named V-net, G-net, and R-net, respectively. To find the best combination of features and networks, training was performed for a total of 39 cases and the performance was confirmed using the test F1 score. Finally, a test F1 score of 91.9% (test accuracy of 97.2%) was achieved from G-net with the MFCC-V-A feature (named Spectroflow), an acoustic feature effective for use in cough detection. The trained cough detection model was integrated with a sound camera (i.e., one that visualizes sound sources using a beamforming microphone array). In a pilot test, the cough detection camera detected coughing sounds with an F1 score of 90.0% (accuracy of 96.0%), and the cough location in the camera image was tracked in real time.
Heavily Augmented Sound Event Detection utilizing Weak Predictions
Jul 20, 2021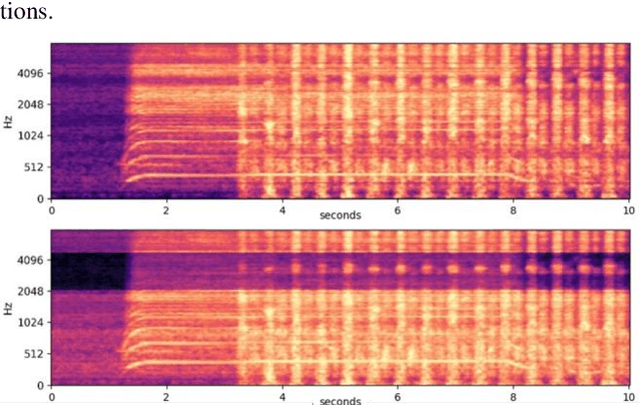
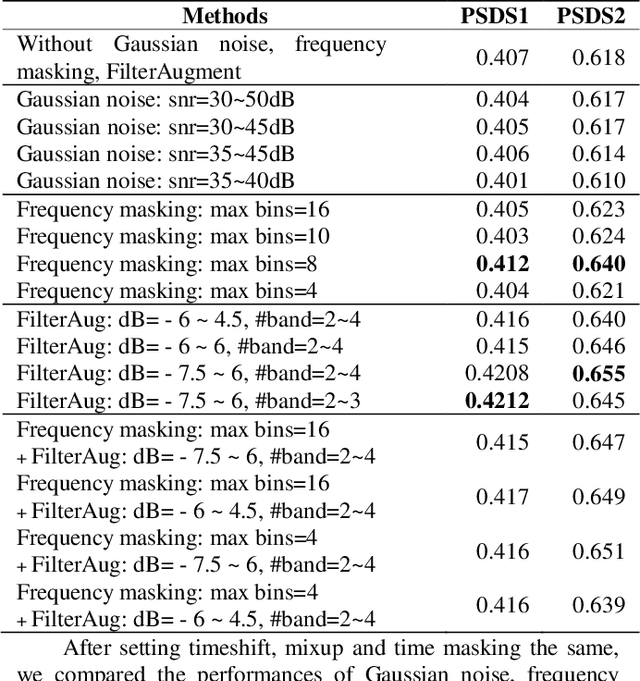
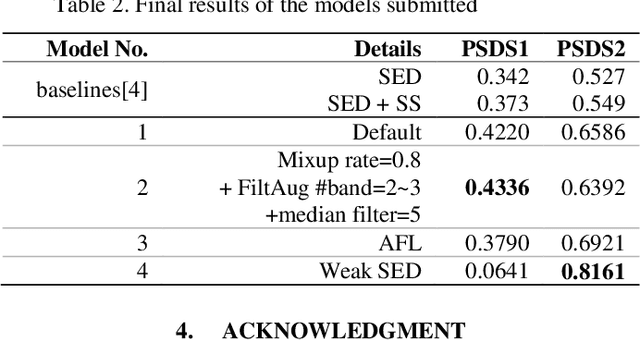
The performances of Sound Event Detection (SED) systems are greatly limited by the difficulty in generating large strongly labeled dataset. In this work, we used two main approaches to overcome the lack of strongly labeled data. First, we applied heavy data augmentation on input features. Data augmentation methods used include not only conventional methods used in speech/audio domains but also our proposed method named FilterAugment. Second, we propose two methods to utilize weak predictions to enhance weakly supervised SED performance. As a result, we obtained the best PSDS1 of 0.4336 and best PSDS2 of 0.8161 on the DESED real validation dataset. This work is submitted to DCASE 2021 Task4 and is ranked on the 3rd place. Code availa-ble: https://github.com/frednam93/FilterAugSED.