 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeHeavily Augmented Sound Event Detection utilizing Weak Predictions
Jul 20, 2021
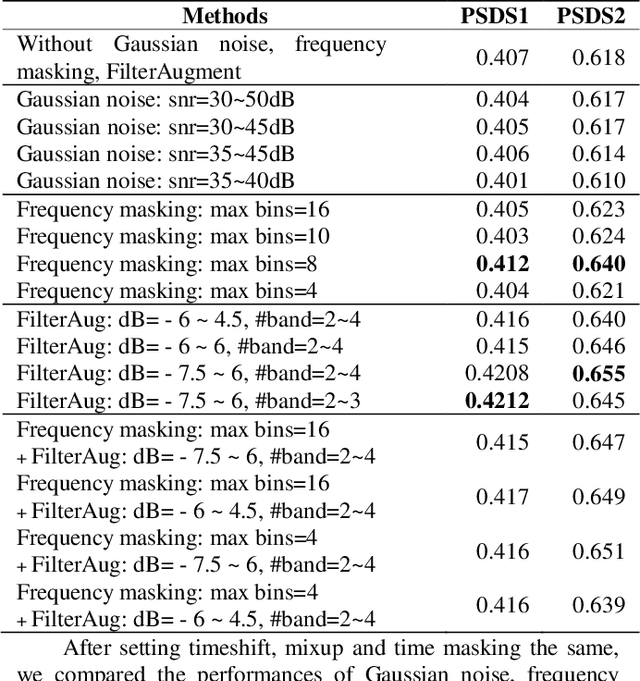
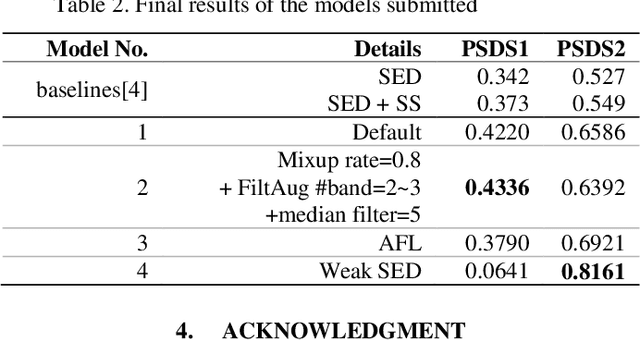
The performances of Sound Event Detection (SED) systems are greatly limited by the difficulty in generating large strongly labeled dataset. In this work, we used two main approaches to overcome the lack of strongly labeled data. First, we applied heavy data augmentation on input features. Data augmentation methods used include not only conventional methods used in speech/audio domains but also our proposed method named FilterAugment. Second, we propose two methods to utilize weak predictions to enhance weakly supervised SED performance. As a result, we obtained the best PSDS1 of 0.4336 and best PSDS2 of 0.8161 on the DESED real validation dataset. This work is submitted to DCASE 2021 Task4 and is ranked on the 3rd place. Code availa-ble: https://github.com/frednam93/FilterAugSED.