Get our free extension to see links to code for papers anywhere online!Free add-on: code for papers everywhere!Free add-on: See code for papers anywhere!
 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeFrequency Dependent Sound Event Detection for DCASE 2022 Challenge Task 4
Paper and Code

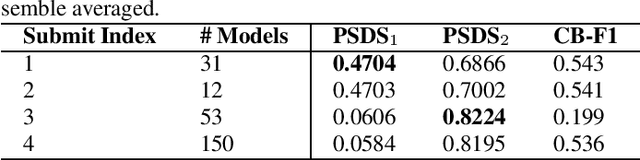
While many deep learning methods on other domains have been applied to sound event detection (SED), differences between original domains of the methods and SED have not been appropriately considered so far. As SED uses audio data with two dimensions (time and frequency) for input, thorough comprehension on these two dimensions is essential for application of methods from other domains on SED. Previous works proved that methods those address on frequency dimension are especially powerful in SED. By applying FilterAugment and frequency dynamic convolution those are frequency dependent methods proposed to enhance SED performance, our submitted models achieved best PSDS1 of 0.4704 and best PSDS2 of 0.8224.
* Technical Reprot submitted for DCASE2022 Challenge Task4
View paper on