 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeDecomposed Temporal Dynamic CNN: Efficient Time-Adaptive Network for Text-Independent Speaker Verification Explained with Speaker Activation Map
Paper and Code
Mar 29, 2022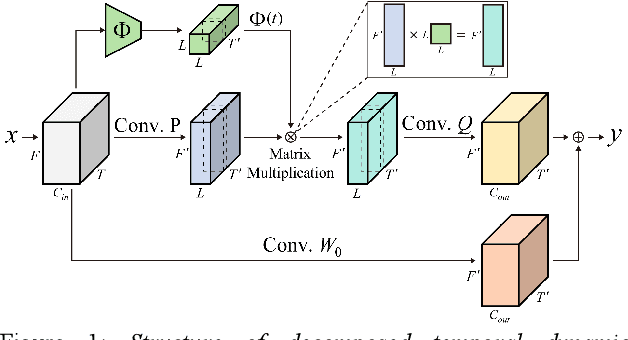

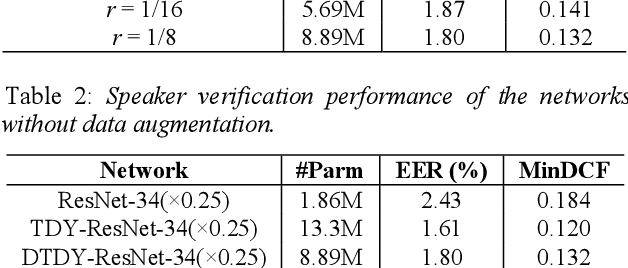
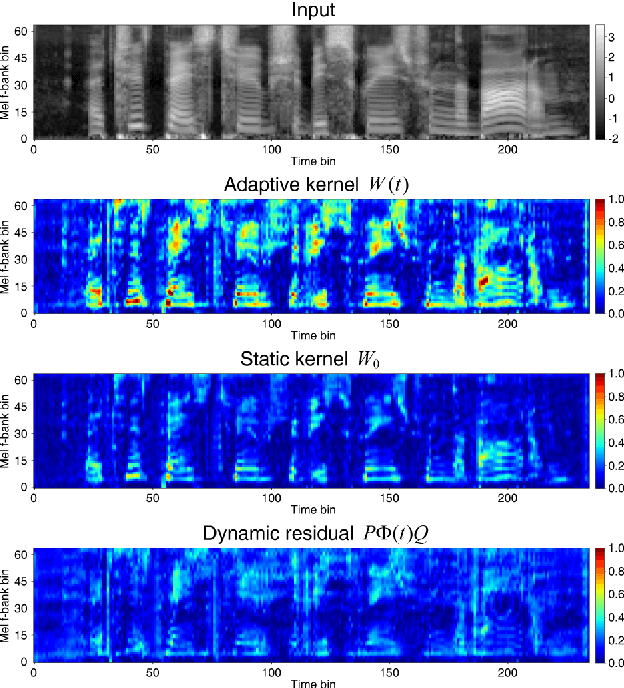
Temporal dynamic models for text-independent speaker verification extract consistent speaker information regardless of phonemes by using temporal dynamic CNN (TDY-CNN) in which kernels adapt to each time bin. However, TDY-CNN shows limitations that the model is too large and does not guarantee the diversity of adaptive kernels. To address these limitations, we propose decomposed temporal dynamic CNN (DTDY-CNN) that makes adaptive kernel by combining static kernel and dynamic residual based on matrix decomposition. The baseline model using DTDY-CNN maintained speaker verification performance while reducing the number of model parameters by 35% compared to the model using TDY-CNN. In addition, detailed behaviors of temporal dynamic models on extraction of speaker information was explained using speaker activation maps (SAM) modified from gradient-weighted class activation mapping (Grad-CAM). In DTDY-CNN, the static kernel activates voiced features of utterances, and the dynamic residual activates unvoiced high-frequency features of phonemes. DTDY-CNN effectively extracts speaker information from not only formant frequencies and harmonics but also detailed unvoiced phonemes' information, thus explaining its outstanding performance on text-independent speaker verification.