 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeFrequency Dynamic Convolution: Frequency-Adaptive Pattern Recognition for Sound Event Detection
Paper and Code
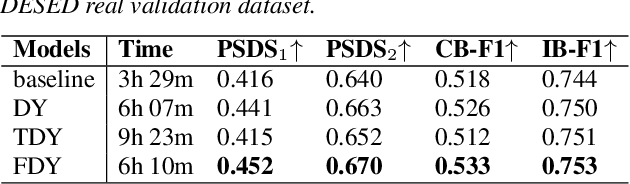
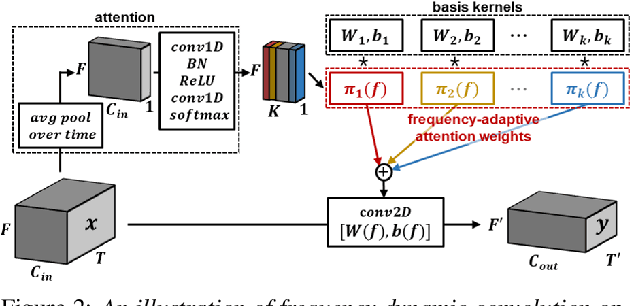
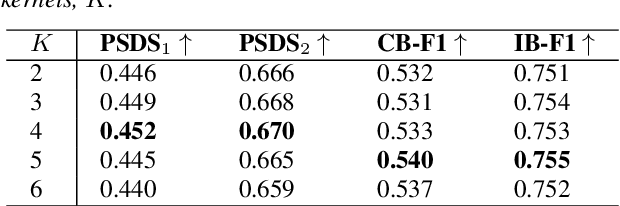
2D convolution is widely used in sound event detection (SED) to recognize 2D patterns of sound events in time-frequency domain. However, 2D convolution enforces translation-invariance on sound events along both time and frequency axis while sound events exhibit frequency-dependent patterns. In order to improve physical inconsistency in 2D convolution on SED, we propose frequency dynamic convolution which applies kernel that adapts to frequency components of input. Frequency dynamic convolution outperforms the baseline model by 6.3% in DESED dataset in terms of polyphonic sound detection score (PSDS). It also significantly outperforms dynamic convolution and temporal dynamic convolution on SED. In addition, by comparing class-wise F1 scores of baseline model and frequency dynamic convolution, we showed that frequency dynamic convolution is especially more effective for detection of non-stationary sound events. From this result, we verified that frequency dynamic convolution is superior in recognizing frequency-dependent patterns as non-stationary sound events show more intricate time-frequency patterns.