 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeExercise with Social Robots: Companion or Coach?
Mar 24, 2021

In this paper, we investigate the roles that social robots can take in physical exercise with human partners. In related work, robots or virtual intelligent agents take the role of a coach or instructor whereas in other approaches they are used as motivational aids. These are two "paradigms", so to speak, within the small but growing area of robots for social exercise. We designed an online questionnaire to test whether the preferred role in which people want to see robots would be the companion or the coach. The questionnaire asks people to imagine working out with a robot with the help of three utilized questionnaires: (1) CART-Q which is used for judging coach-athlete relationships, (2) the mind perception questionnaire and (3) the System Usability Scale (SUS). We present the methodology, some preliminary results as well as our intended future work on personal robots for coaching.
iCub: Learning Emotion Expressions using Human Reward
Mar 30, 2020

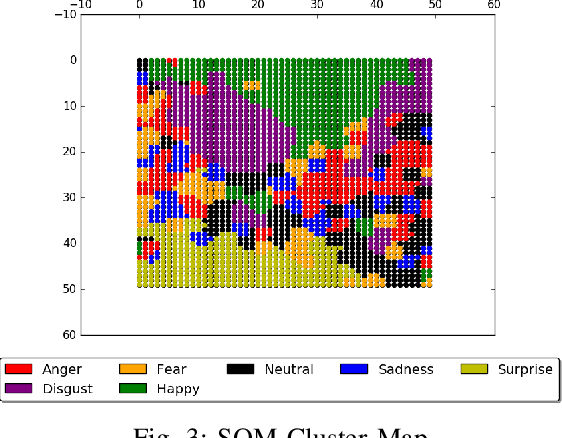

The purpose of the present study is to learn emotion expression representations for artificial agents using reward shaping mechanisms. The approach takes inspiration from the TAMER framework for training a Multilayer Perceptron (MLP) to learn to express different emotions on the iCub robot in a human-robot interaction scenario. The robot uses a combination of a Convolutional Neural Network (CNN) and a Self-Organising Map (SOM) to recognise an emotion and then learns to express the same using the MLP. The objective is to teach a robot to respond adequately to the user's perception of emotions and learn how to express different emotions.
Multilinear Grammar: Ranks and Interpretations
Aug 27, 2017
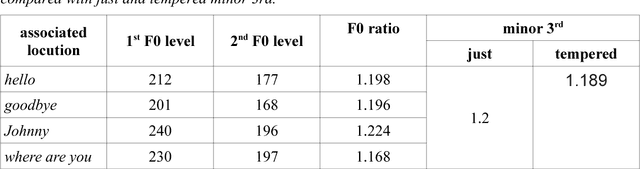
Multilinear Grammar provides a framework for integrating the many different syntagmatic structures of language into a coherent semiotically based Rank Interpretation Architecture, with default linear grammars at each rank. The architecture defines a Sui Generis Condition on ranks, from discourse through utterance and phrasal structures to the word, with its sub-ranks of morphology and phonology. Each rank has unique structures and its own semantic-pragmatic and prosodic-phonetic interpretation models. Default computational models for each rank are proposed, based on a Procedural Plausibility Condition: incremental processing in linear time with finite working memory. We suggest that the Rank Interpretation Architecture and its multilinear properties provide systematic design features of human languages, contrasting with unordered lists of key properties or single structural properties at one rank, such as recursion, which have previously been been put forward as language design features. The framework provides a realistic background for the gradual development of complexity in the phylogeny and ontogeny of language, and clarifies a range of challenges for the evaluation of realistic linguistic theories and applications. The empirical objective of the paper is to demonstrate unique multilinear properties at each rank and thereby motivate the Multilinear Grammar and Rank Interpretation Architecture framework as a coherent approach to capturing the complexity of human languages in the simplest possible way.
* 45 pages, 10 figures. In press, journal Open Linguistics (de Gruyter Open), proofread and corrected version
A Proposal for Linguistic Similarity Datasets Based on Commonality Lists
Jun 17, 2016Similarity is a core notion that is used in psychology and two branches of linguistics: theoretical and computational. The similarity datasets that come from the two fields differ in design: psychological datasets are focused around a certain topic such as fruit names, while linguistic datasets contain words from various categories. The later makes humans assign low similarity scores to the words that have nothing in common and to the words that have contrast in meaning, making similarity scores ambiguous. In this work we discuss the similarity collection procedure for a multi-category dataset that avoids score ambiguity and suggest changes to the evaluation procedure to reflect the insights of psychological literature for word, phrase and sentence similarity. We suggest to ask humans to provide a list of commonalities and differences instead of numerical similarity scores and employ the structure of human judgements beyond pairwise similarity for model evaluation. We believe that the proposed approach will give rise to datasets that test meaning representation models more thoroughly with respect to the human treatment of similarity.