 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeComputational Induction of Prosodic Structure
Dec 15, 2019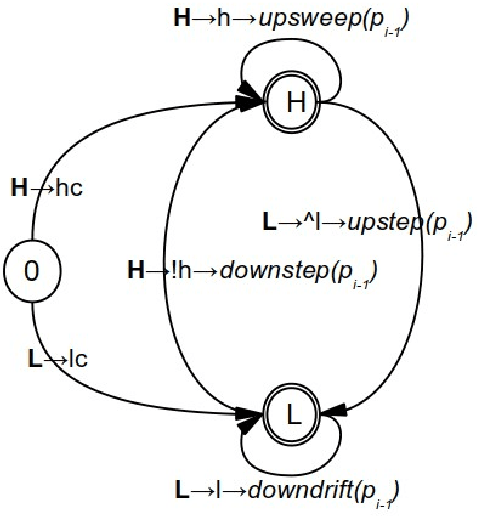

The present study has two goals relating to the grammar of prosody, understood as the rhythms and melodies of speech. First, an overview is provided of the computable grammatical and phonetic approaches to prosody analysis which use hypothetico-deductive methods and are based on learned hermeneutic intuitions about language. Second, a proposal is presented for an inductive grounding in the physical signal, in which prosodic structure is inferred using a language-independent method from the low-frequency spectrum of the speech signal. The overview includes a discussion of computational aspects of standard generative and post-generative models, and suggestions for reformulating these to form inductive approaches. Also included is a discussion of linguistic phonetic approaches to analysis of annotations (pairs of speech unit labels with time-stamps) of recorded spoken utterances. The proposal introduces the inductive approach of Rhythm Formant Theory (RFT) and the associated Rhythm Formant Analysis (RFA) method are introduced, with the aim of completing a gap in the linguistic hypothetico-deductive cycle by grounding in a language-independent inductive procedure of speech signal analysis. The validity of the method is demonstrated and applied to rhythm patterns in read-aloud Mandarin Chinese, finding differences from English which are related to lexical and grammatical differences between the languages, as well as individual variation. The overall conclusions are (1) that normative language-to-language phonological or phonetic comparisons of rhythm, for example of Mandarin and English, are too simplistic, in view of diverse language-internal factors due to genre and style differences as well as utterance dynamics, and (2) that language-independent empirical grounding of rhythm in the physical signal is called for.
Quantifying and Correlating Rhythm Formants in Speech
Sep 03, 2019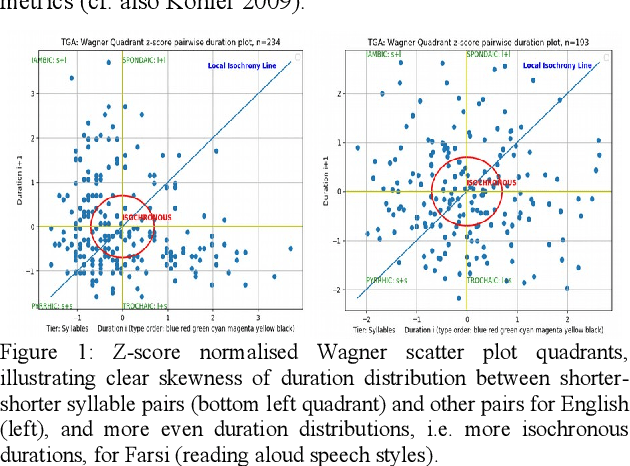
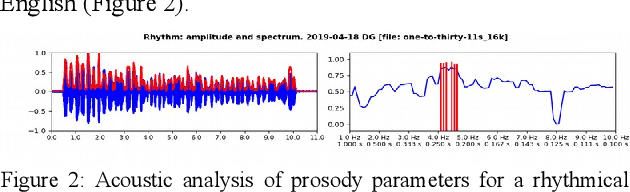
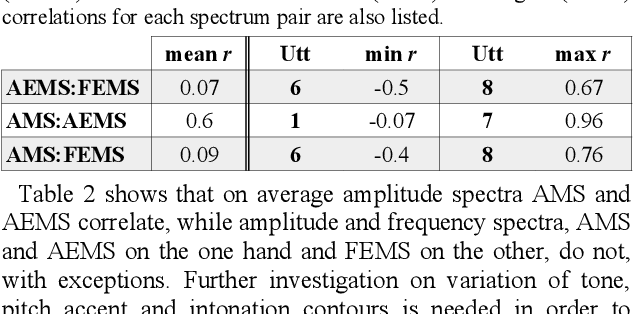
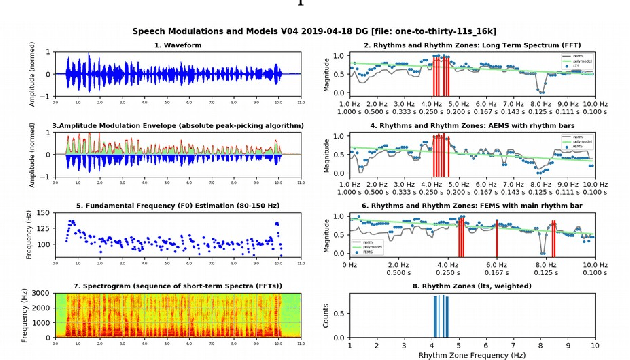
The objective of the present study is exploratory: to introduce and apply a new theory of speech rhythm zones or rhythm formants (R-formants). R-formants are zones of high magnitude frequencies in the low frequency (LF) long-term spectrum (LTS), rather like formants in the short-term spectra of vowels and consonants. After an illustration of the method, an R-formant analysis is made of non-elicited extracts from public speeches. The LF-LTS of three domains, the amplitude modulated (AM) absolute (rectified) signal, the amplitude envelope modulation (AEM) and frequency modulation (FM, F0, 'pitch') of the signal are compared. The first two correlate well, but the third does not correlate consistently with the other two, presumably due to variability of tone, pitch accent and intonation. Consequently, only the LF LTS of the absolute speech signal is used in the empirical analysis. An informal discussion of the relation between R-formant patterns and utterance structure and a selection of pragmatic variables over the same utterances showed some trends for R-formant functionality and thus useful directions for future research.
CRAFT: A multifunction online platform for speech prosody visualisation
Mar 18, 2019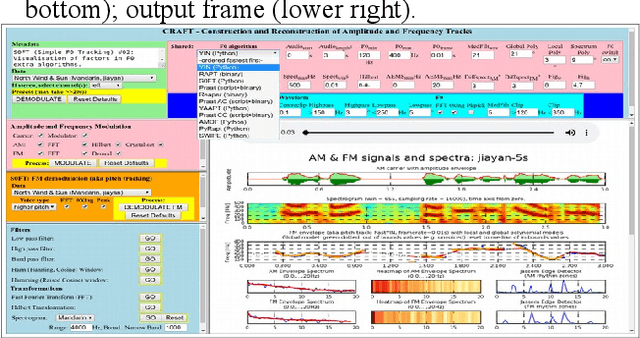
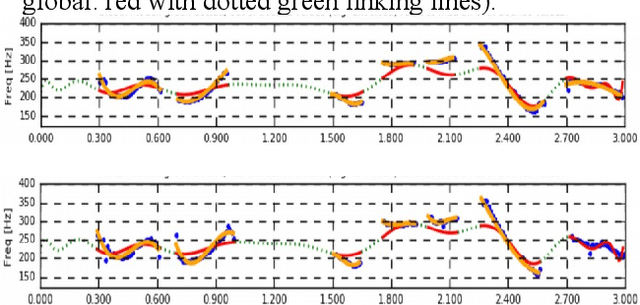
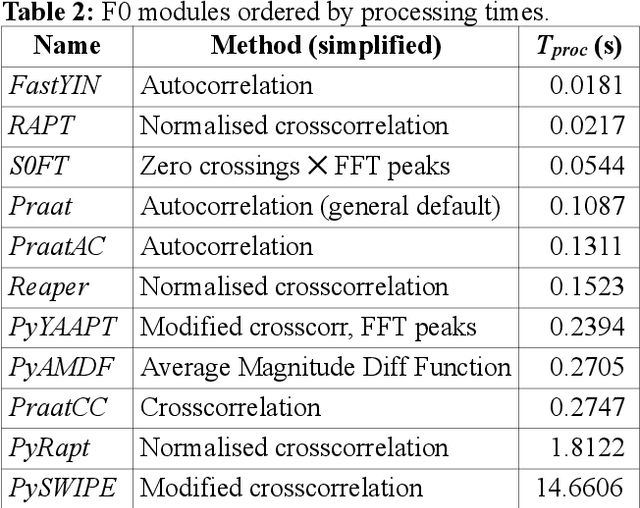
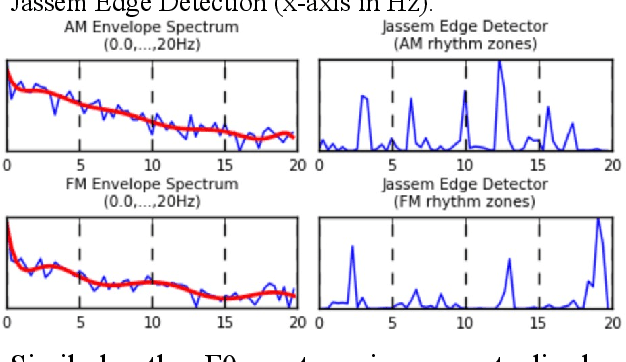
There are many research tools which are also used for teaching the acoustic phonetics of speech rhythm and speech melody. But they were not purpose-designed for teaching-learning situations, and some have a steep learning curve. CRAFT (Creation and Recovery of Amplitude and Frequency Tracks) is custom-designed as a novel flexible online tool for visualisation and critical comparison of functions and transforms, with implementations of the Reaper, RAPT, PyRapt, YAAPT, YIN and PySWIPE F0 estimators, three Praat configurations, and two purpose-built estimators, PyAMDF, S0FT. Visualisations of amplitude and frequency envelope spectra, spectral edge detection of rhythm zones, and a parametrised spectrogram are included. A selection of audio clips from tone and intonation languages is provided for demonstration purposes. The main advantages of online tools are consistency (users have the same version and the same data selection), interoperability over different platforms, and ease of maintenance. The code is available on GitHub.
Rhythm Zone Theory: Speech Rhythms are Physical after all
Mar 12, 2019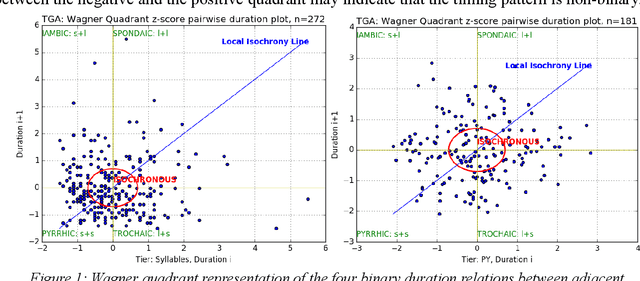
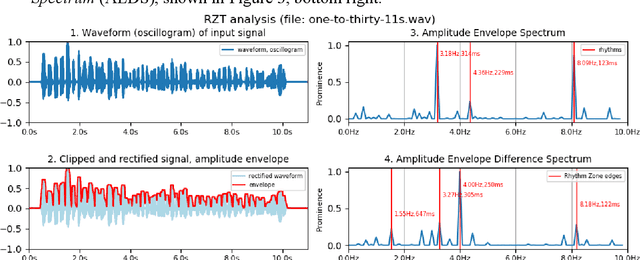
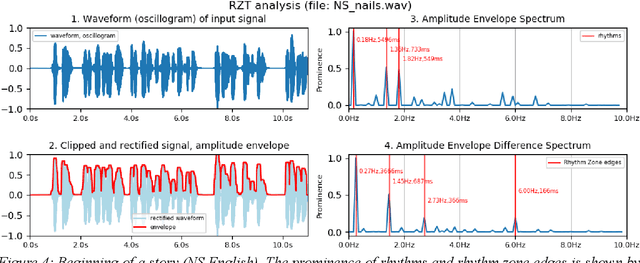
Speech rhythms have been dealt with in three main ways: from the introspective analyses of rhythm as a correlate of syllable and foot timing in linguistics and applied linguistics, through analyses of durations of segments of utterances associated with consonantal and vocalic properties, syllables, feet and words, to models of rhythms in speech production and perception as physical oscillations. The present study avoids introspection and human-filtered annotation methods and extends the signal processing paradigm of amplitude envelope spectrum analysis by adding an additional analytic step of edge detection, and postulating the co-existence of multiple speech rhythms in rhythm zones marked by identifiable edges (Rhythm Zone Theory, RZT). An exploratory investigation of the utility of RZT is conducted, suggesting that native and non-native readings of the same text are distinct sub-genres of read speech: a reading by a US native speaker and non-native readings by relatively low-performing Cantonese adult learners of English. The study concludes by noting that with the methods used, RZT can distinguish between the speech rhythms of well-defined sub-genres of native speaker reading vs. non-native learner reading, but needs further refinement in order to be applied to the paradoxically more complex speech of low-performing language learners, whose speech rhythms are co-determined by non-fluency and disfluency factors in addition to well-known linguistic factors of grammar, vocabulary and discourse constraints.
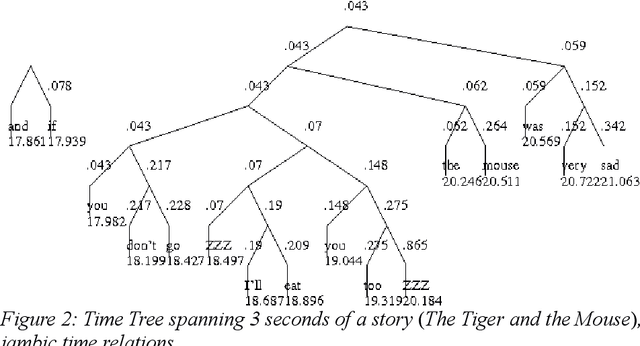
The Future of Prosody: It's about Time
May 15, 2018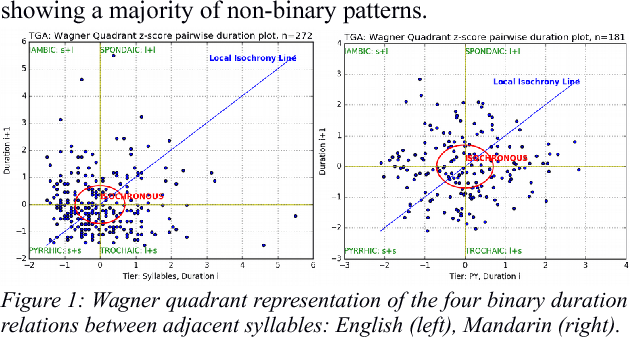
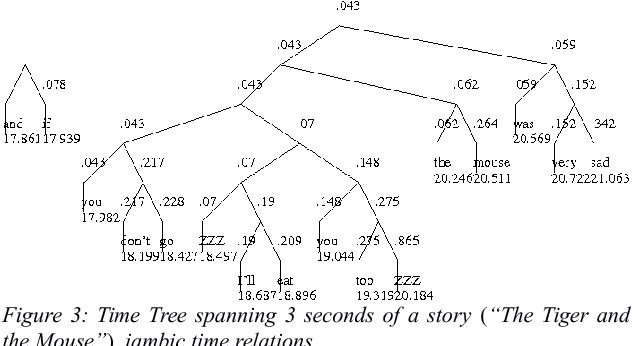

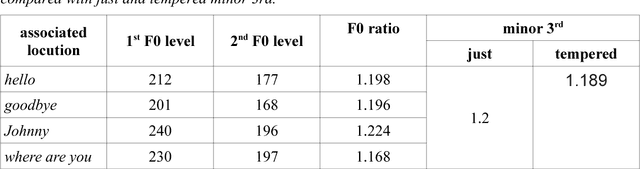
Prosody is usually defined in terms of the three distinct but interacting domains of pitch, intensity and duration patterning, or, more generally, as phonological and phonetic properties of 'suprasegmentals', speech segments which are larger than consonants and vowels. Rather than taking this approach, the concept of multiple time domains for prosody processing is taken up, and methods of time domain analysis are discussed: annotation mining with timing dispersion measures, time tree induction, oscillator models in phonology and phonetics, and finally the use of the Amplitude Envelope Modulation Spectrum (AEMS). While frequency demodulation (in the form of pitch tracking) is a central issue in prosodic analysis, in the present context it is amplitude envelope demodulation and frequency zones in the long time-domain spectra of the demodulated envelope which are focused. A generalised view is taken of oscillation as iteration in abstract prosodic models and as modulation and demodulation of a variety of rhythms in the speech signal.
Multilinear Grammar: Ranks and Interpretations
Aug 27, 2017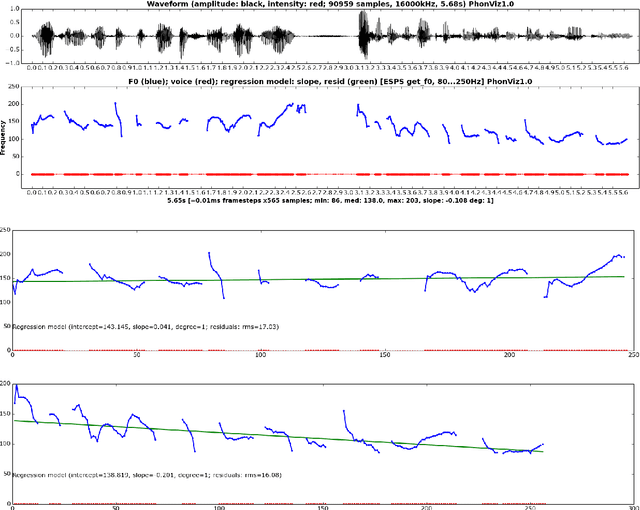
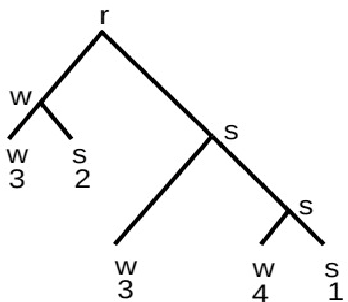
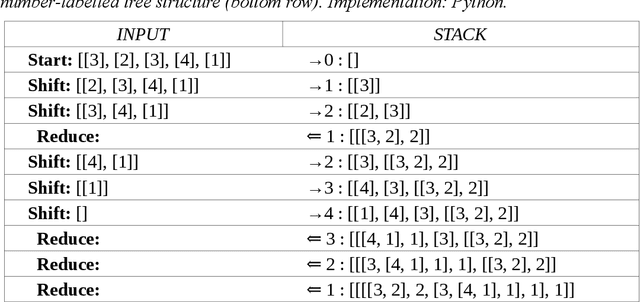
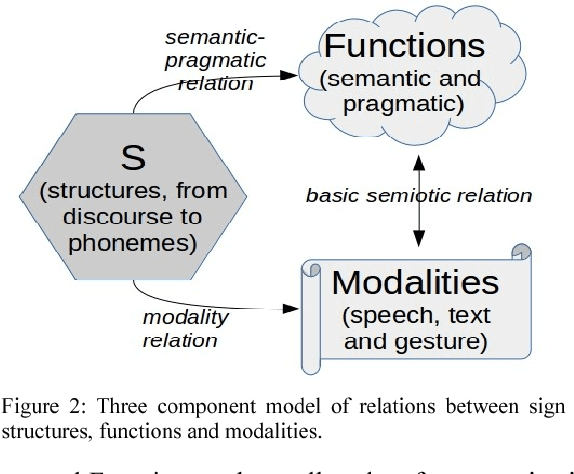
Multilinear Grammar provides a framework for integrating the many different syntagmatic structures of language into a coherent semiotically based Rank Interpretation Architecture, with default linear grammars at each rank. The architecture defines a Sui Generis Condition on ranks, from discourse through utterance and phrasal structures to the word, with its sub-ranks of morphology and phonology. Each rank has unique structures and its own semantic-pragmatic and prosodic-phonetic interpretation models. Default computational models for each rank are proposed, based on a Procedural Plausibility Condition: incremental processing in linear time with finite working memory. We suggest that the Rank Interpretation Architecture and its multilinear properties provide systematic design features of human languages, contrasting with unordered lists of key properties or single structural properties at one rank, such as recursion, which have previously been been put forward as language design features. The framework provides a realistic background for the gradual development of complexity in the phylogeny and ontogeny of language, and clarifies a range of challenges for the evaluation of realistic linguistic theories and applications. The empirical objective of the paper is to demonstrate unique multilinear properties at each rank and thereby motivate the Multilinear Grammar and Rank Interpretation Architecture framework as a coherent approach to capturing the complexity of human languages in the simplest possible way.
* 45 pages, 10 figures. In press, journal Open Linguistics (de Gruyter Open), proofread and corrected version
Prosody: The Rhythms and Melodies of Speech
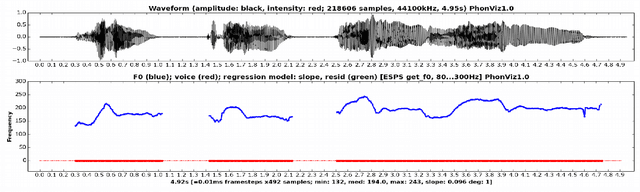
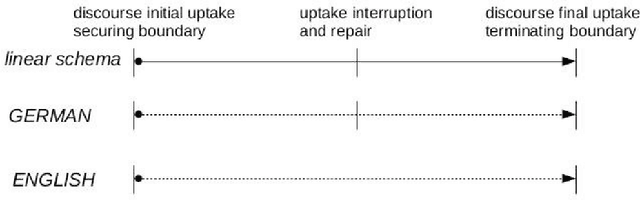
Apr 27, 2017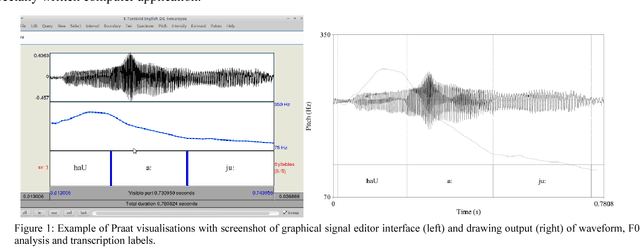

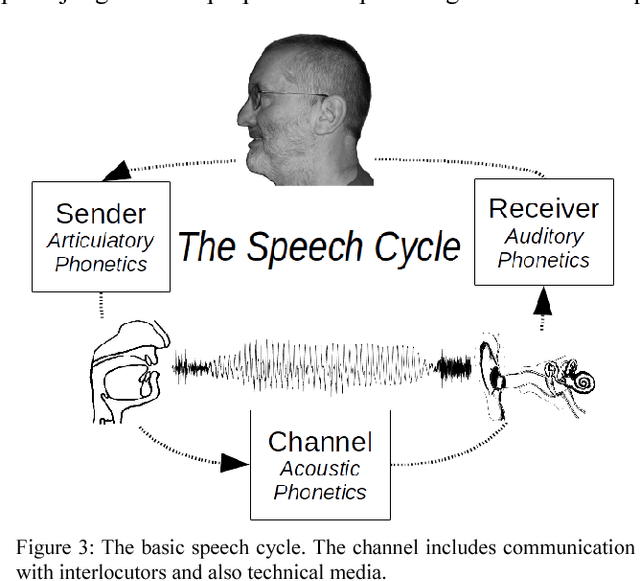
The present contribution is a tutorial on selected aspects of prosody, the rhythms and melodies of speech, based on a course of the same name at the Summer School on Contemporary Phonetics and Phonology at Tongji University, Shanghai, China in July 2016. The tutorial is not intended as an introduction to experimental methodology or as an overview of the literature on the topic, but as an outline of observationally accessible aspects of fundamental frequency and timing patterns with the aid of computational visualisation, situated in a semiotic framework of sign ranks and interpretations. After an informal introduction to the basic concepts of prosody in the introduction and a discussion of the place of prosody in the architecture of language, a selection of acoustic phonetic topics in phonemic tone and accent prosody, word prosody, phrasal prosody and discourse prosody are discussed, and a stylisation method for visualising aspects of prosody is introduced. Examples are taken from a number of typologically different languages: Anyi/Agni (Niger-Congo>Kwa, Ivory Coast), English, Kuki-Thadou (Sino-Tibetan, North-East India and Myanmar), Mandarin Chinese, Tem (Niger-Congo>Gur, Togo) and Farsi. The main focus is on fundamental frequency patterns, but issues of timing and rhythm are also discussed. In the final section, further reading and possible future research directions are outlined.