 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeDiffusion Transformer-based Universal Dose Denoising for Pencil Beam Scanning Proton Therapy
Jun 04, 2025Purpose: Intensity-modulated proton therapy (IMPT) offers precise tumor coverage while sparing organs at risk (OARs) in head and neck (H&N) cancer. However, its sensitivity to anatomical changes requires frequent adaptation through online adaptive radiation therapy (oART), which depends on fast, accurate dose calculation via Monte Carlo (MC) simulations. Reducing particle count accelerates MC but degrades accuracy. To address this, denoising low-statistics MC dose maps is proposed to enable fast, high-quality dose generation. Methods: We developed a diffusion transformer-based denoising framework. IMPT plans and 3D CT images from 80 H&N patients were used to generate noisy and high-statistics dose maps using MCsquare (1 min and 10 min per plan, respectively). Data were standardized into uniform chunks with zero-padding, normalized, and transformed into quasi-Gaussian distributions. Testing was done on 10 H&N, 10 lung, 10 breast, and 10 prostate cancer cases, preprocessed identically. The model was trained with noisy dose maps and CT images as input and high-statistics dose maps as ground truth, using a combined loss of mean square error (MSE), residual loss, and regional MAE (focusing on top/bottom 10% dose voxels). Performance was assessed via MAE, 3D Gamma passing rate, and DVH indices. Results: The model achieved MAEs of 0.195 (H&N), 0.120 (lung), 0.172 (breast), and 0.376 Gy[RBE] (prostate). 3D Gamma passing rates exceeded 92% (3%/2mm) across all sites. DVH indices for clinical target volumes (CTVs) and OARs closely matched the ground truth. Conclusion: A diffusion transformer-based denoising framework was developed and, though trained only on H&N data, generalizes well across multiple disease sites.
Fine-Tuning Open-Source Large Language Models to Improve Their Performance on Radiation Oncology Tasks: A Feasibility Study to Investigate Their Potential Clinical Applications in Radiation Oncology
Jan 28, 2025



Background: The radiation oncology clinical practice involves many steps relying on the dynamic interplay of abundant text data. Large language models have displayed remarkable capabilities in processing complex text information. But their direct applications in specific fields like radiation oncology remain underexplored. Purpose: This study aims to investigate whether fine-tuning LLMs with domain knowledge can improve the performance on Task (1) treatment regimen generation, Task (2) treatment modality selection (photon, proton, electron, or brachytherapy), and Task (3) ICD-10 code prediction in radiation oncology. Methods: Data for 15,724 patient cases were extracted. Cases where patients had a single diagnostic record, and a clearly identifiable primary treatment plan were selected for preprocessing and manual annotation to have 7,903 cases of the patient diagnosis, treatment plan, treatment modality, and ICD-10 code. Each case was used to construct a pair consisting of patient diagnostics details and an answer (treatment regimen, treatment modality, or ICD-10 code respectively) for the supervised fine-tuning of these three tasks. Open source LLaMA2-7B and Mistral-7B models were utilized for the fine-tuning with the Low-Rank Approximations method. Accuracy and ROUGE-1 score were reported for the fine-tuned models and original models. Clinical evaluation was performed on Task (1) by radiation oncologists, while precision, recall, and F-1 score were evaluated for Task (2) and (3). One-sided Wilcoxon signed-rank tests were used to statistically analyze the results. Results: Fine-tuned LLMs outperformed original LLMs across all tasks with p-value <= 0.001. Clinical evaluation demonstrated that over 60% of the fine-tuned LLMs-generated treatment regimens were clinically acceptable. Precision, recall, and F1-score showed improved performance of fine-tuned LLMs.
Evaluating The Performance of Using Large Language Models to Automate Summarization of CT Simulation Orders in Radiation Oncology
Jan 27, 2025



Purpose: This study aims to use a large language model (LLM) to automate the generation of summaries from the CT simulation orders and evaluate its performance. Materials and Methods: A total of 607 CT simulation orders for patients were collected from the Aria database at our institution. A locally hosted Llama 3.1 405B model, accessed via the Application Programming Interface (API) service, was used to extract keywords from the CT simulation orders and generate summaries. The downloaded CT simulation orders were categorized into seven groups based on treatment modalities and disease sites. For each group, a customized instruction prompt was developed collaboratively with therapists to guide the Llama 3.1 405B model in generating summaries. The ground truth for the corresponding summaries was manually derived by carefully reviewing each CT simulation order and subsequently verified by therapists. The accuracy of the LLM-generated summaries was evaluated by therapists using the verified ground truth as a reference. Results: About 98% of the LLM-generated summaries aligned with the manually generated ground truth in terms of accuracy. Our evaluations showed an improved consistency in format and enhanced readability of the LLM-generated summaries compared to the corresponding therapists-generated summaries. This automated approach demonstrated a consistent performance across all groups, regardless of modality or disease site. Conclusions: This study demonstrated the high precision and consistency of the Llama 3.1 405B model in extracting keywords and summarizing CT simulation orders, suggesting that LLMs have great potential to help with this task, reduce the workload of therapists and improve workflow efficiency.
Retrospective Comparative Analysis of Prostate Cancer In-Basket Messages: Responses from Closed-Domain LLM vs. Clinical Teams
Sep 26, 2024In-basket message interactions play a crucial role in physician-patient communication, occurring during all phases (pre-, during, and post) of a patient's care journey. However, responding to these patients' inquiries has become a significant burden on healthcare workflows, consuming considerable time for clinical care teams. To address this, we introduce RadOnc-GPT, a specialized Large Language Model (LLM) powered by GPT-4 that has been designed with a focus on radiotherapeutic treatment of prostate cancer with advanced prompt engineering, and specifically designed to assist in generating responses. We integrated RadOnc-GPT with patient electronic health records (EHR) from both the hospital-wide EHR database and an internal, radiation-oncology-specific database. RadOnc-GPT was evaluated on 158 previously recorded in-basket message interactions. Quantitative natural language processing (NLP) analysis and two grading studies with clinicians and nurses were used to assess RadOnc-GPT's responses. Our findings indicate that RadOnc-GPT slightly outperformed the clinical care team in "Clarity" and "Empathy," while achieving comparable scores in "Completeness" and "Correctness." RadOnc-GPT is estimated to save 5.2 minutes per message for nurses and 2.4 minutes for clinicians, from reading the inquiry to sending the response. Employing RadOnc-GPT for in-basket message draft generation has the potential to alleviate the workload of clinical care teams and reduce healthcare costs by producing high-quality, timely responses.
RadOnc-GPT: A Large Language Model for Radiation Oncology
Sep 22, 2023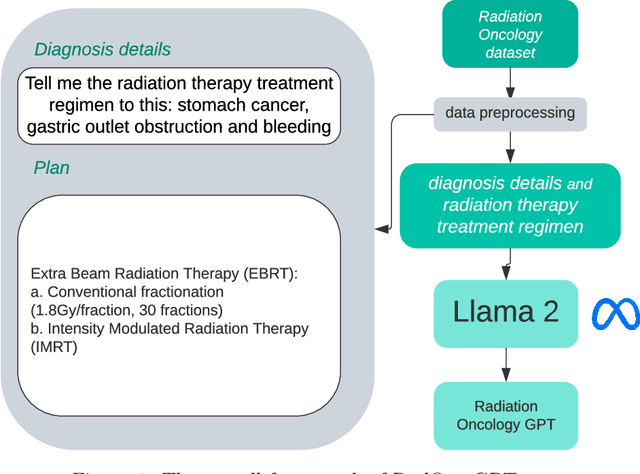
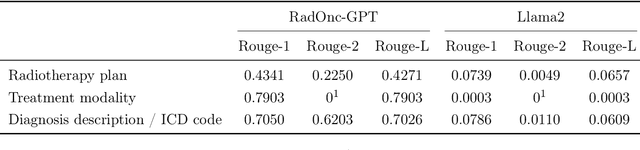

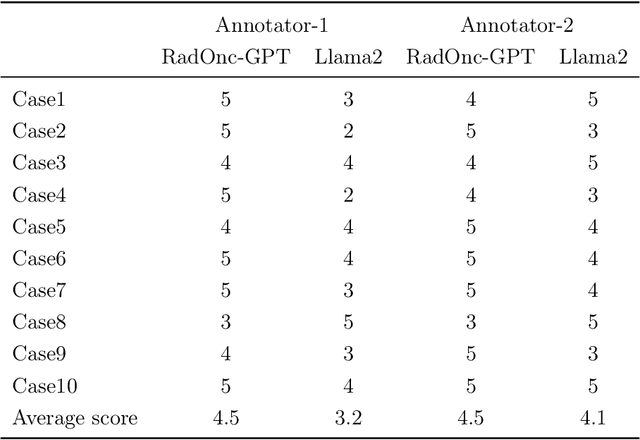
This paper presents RadOnc-GPT, a large language model specialized for radiation oncology through advanced tuning methods. RadOnc-GPT was finetuned on a large dataset of radiation oncology patient records and clinical notes from the Mayo Clinic in Arizona. The model employs instruction tuning on three key tasks - generating radiotherapy treatment regimens, determining optimal radiation modalities, and providing diagnostic descriptions/ICD codes based on patient diagnostic details. Evaluations conducted by comparing RadOnc-GPT outputs to general large language model outputs showed that RadOnc-GPT generated outputs with significantly improved clarity, specificity, and clinical relevance. The study demonstrated the potential of using large language models fine-tuned using domain-specific knowledge like RadOnc-GPT to achieve transformational capabilities in highly specialized healthcare fields such as radiation oncology.