 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeInteractive proofs for verifying (quantum) learning and testing
Oct 31, 2024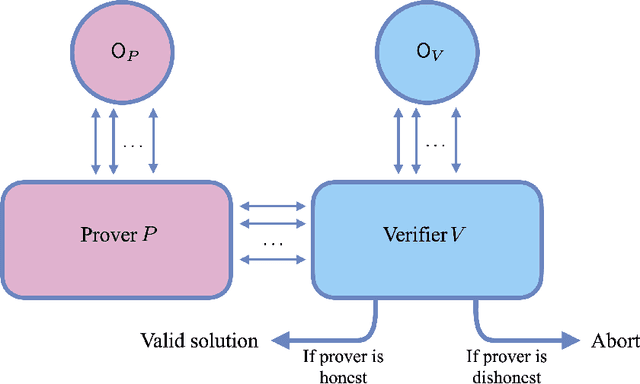

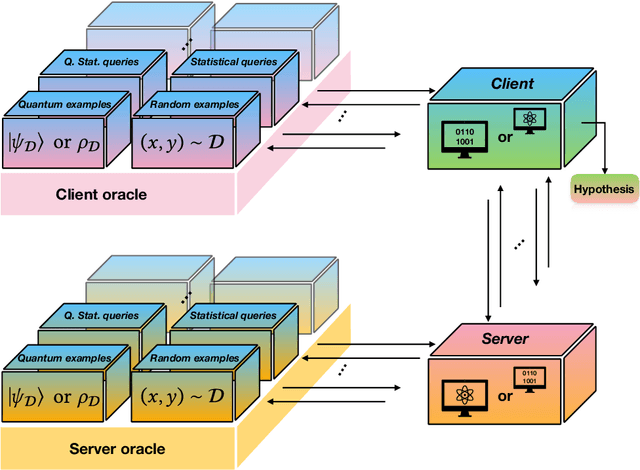
We consider the problem of testing and learning from data in the presence of resource constraints, such as limited memory or weak data access, which place limitations on the efficiency and feasibility of testing or learning. In particular, we ask the following question: Could a resource-constrained learner/tester use interaction with a resource-unconstrained but untrusted party to solve a learning or testing problem more efficiently than they could without such an interaction? In this work, we answer this question both abstractly and for concrete problems, in two complementary ways: For a wide variety of scenarios, we prove that a resource-constrained learner cannot gain any advantage through classical interaction with an untrusted prover. As a special case, we show that for the vast majority of testing and learning problems in which quantum memory is a meaningful resource, a memory-constrained quantum algorithm cannot overcome its limitations via classical communication with a memory-unconstrained quantum prover. In contrast, when quantum communication is allowed, we construct a variety of interactive proof protocols, for specific learning and testing problems, which allow memory-constrained quantum verifiers to gain significant advantages through delegation to untrusted provers. These results highlight both the limitations and potential of delegating learning and testing problems to resource-rich but untrusted third parties.
Learning topological states from randomized measurements using variational tensor network tomography
Jun 04, 2024



Learning faithful representations of quantum states is crucial to fully characterizing the variety of many-body states created on quantum processors. While various tomographic methods such as classical shadow and MPS tomography have shown promise in characterizing a wide class of quantum states, they face unique limitations in detecting topologically ordered two-dimensional states. To address this problem, we implement and study a heuristic tomographic method that combines variational optimization on tensor networks with randomized measurement techniques. Using this approach, we demonstrate its ability to learn the ground state of the surface code Hamiltonian as well as an experimentally realizable quantum spin liquid state. In particular, we perform numerical experiments using MPS ans\"atze and systematically investigate the sample complexity required to achieve high fidelities for systems of sizes up to $48$ qubits. In addition, we provide theoretical insights into the scaling of our learning algorithm by analyzing the statistical properties of maximum likelihood estimation. Notably, our method is sample-efficient and experimentally friendly, only requiring snapshots of the quantum state measured randomly in the $X$ or $Z$ bases. Using this subset of measurements, our approach can effectively learn any real pure states represented by tensor networks, and we rigorously prove that random-$XZ$ measurements are tomographically complete for such states.
Potential and limitations of random Fourier features for dequantizing quantum machine learning
Sep 20, 2023Quantum machine learning is arguably one of the most explored applications of near-term quantum devices. Much focus has been put on notions of variational quantum machine learning where parameterized quantum circuits (PQCs) are used as learning models. These PQC models have a rich structure which suggests that they might be amenable to efficient dequantization via random Fourier features (RFF). In this work, we establish necessary and sufficient conditions under which RFF does indeed provide an efficient dequantization of variational quantum machine learning for regression. We build on these insights to make concrete suggestions for PQC architecture design, and to identify structures which are necessary for a regression problem to admit a potential quantum advantage via PQC based optimization.
Classical Verification of Quantum Learning
Jun 08, 2023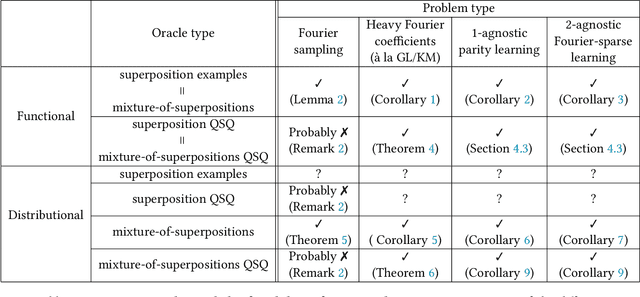
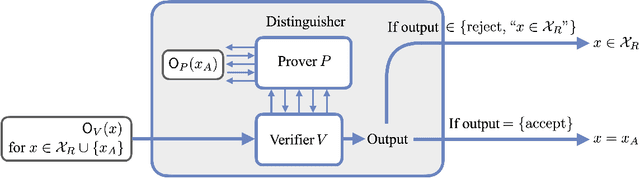
Quantum data access and quantum processing can make certain classically intractable learning tasks feasible. However, quantum capabilities will only be available to a select few in the near future. Thus, reliable schemes that allow classical clients to delegate learning to untrusted quantum servers are required to facilitate widespread access to quantum learning advantages. Building on a recently introduced framework of interactive proof systems for classical machine learning, we develop a framework for classical verification of quantum learning. We exhibit learning problems that a classical learner cannot efficiently solve on their own, but that they can efficiently and reliably solve when interacting with an untrusted quantum prover. Concretely, we consider the problems of agnostic learning parities and Fourier-sparse functions with respect to distributions with uniform input marginal. We propose a new quantum data access model that we call "mixture-of-superpositions" quantum examples, based on which we give efficient quantum learning algorithms for these tasks. Moreover, we prove that agnostic quantum parity and Fourier-sparse learning can be efficiently verified by a classical verifier with only random example or statistical query access. Finally, we showcase two general scenarios in learning and verification in which quantum mixture-of-superpositions examples do not lead to sample complexity improvements over classical data. Our results demonstrate that the potential power of quantum data for learning tasks, while not unlimited, can be utilized by classical agents through interaction with untrusted quantum entities.
On the average-case complexity of learning output distributions of quantum circuits
May 09, 2023In this work, we show that learning the output distributions of brickwork random quantum circuits is average-case hard in the statistical query model. This learning model is widely used as an abstract computational model for most generic learning algorithms. In particular, for brickwork random quantum circuits on $n$ qubits of depth $d$, we show three main results: - At super logarithmic circuit depth $d=\omega(\log(n))$, any learning algorithm requires super polynomially many queries to achieve a constant probability of success over the randomly drawn instance. - There exists a $d=O(n)$, such that any learning algorithm requires $\Omega(2^n)$ queries to achieve a $O(2^{-n})$ probability of success over the randomly drawn instance. - At infinite circuit depth $d\to\infty$, any learning algorithm requires $2^{2^{\Omega(n)}}$ many queries to achieve a $2^{-2^{\Omega(n)}}$ probability of success over the randomly drawn instance. As an auxiliary result of independent interest, we show that the output distribution of a brickwork random quantum circuit is constantly far from any fixed distribution in total variation distance with probability $1-O(2^{-n})$, which confirms a variant of a conjecture by Aaronson and Chen.
A super-polynomial quantum-classical separation for density modelling
Oct 26, 2022Density modelling is the task of learning an unknown probability density function from samples, and is one of the central problems of unsupervised machine learning. In this work, we show that there exists a density modelling problem for which fault-tolerant quantum computers can offer a super-polynomial advantage over classical learning algorithms, given standard cryptographic assumptions. Along the way, we provide a variety of additional results and insights, of potential interest for proving future distribution learning separations between quantum and classical learning algorithms. Specifically, we (a) provide an overview of the relationships between hardness results in supervised learning and distribution learning, and (b) show that any weak pseudo-random function can be used to construct a classically hard density modelling problem. The latter result opens up the possibility of proving quantum-classical separations for density modelling based on weaker assumptions than those necessary for pseudo-random functions.
Scalably learning quantum many-body Hamiltonians from dynamical data
Sep 28, 2022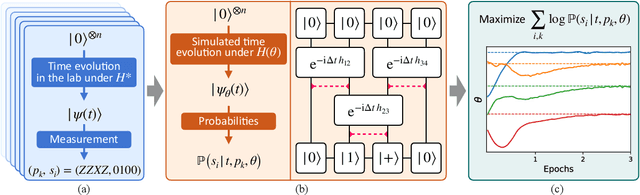
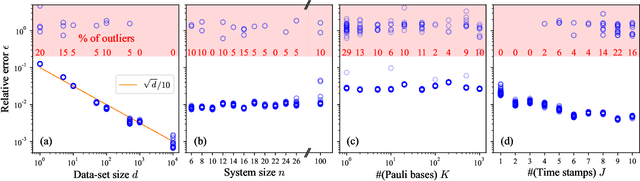
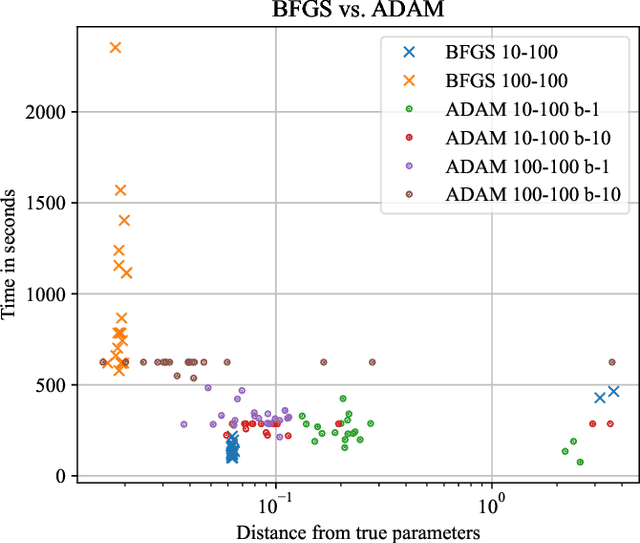
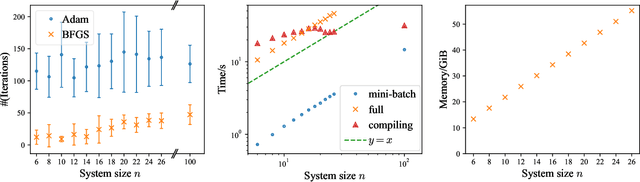
The physics of a closed quantum mechanical system is governed by its Hamiltonian. However, in most practical situations, this Hamiltonian is not precisely known, and ultimately all there is are data obtained from measurements on the system. In this work, we introduce a highly scalable, data-driven approach to learning families of interacting many-body Hamiltonians from dynamical data, by bringing together techniques from gradient-based optimization from machine learning with efficient quantum state representations in terms of tensor networks. Our approach is highly practical, experimentally friendly, and intrinsically scalable to allow for system sizes of above 100 spins. In particular, we demonstrate on synthetic data that the algorithm works even if one is restricted to one simple initial state, a small number of single-qubit observables, and time evolution up to relatively short times. For the concrete example of the one-dimensional Heisenberg model our algorithm exhibits an error constant in the system size and scaling as the inverse square root of the size of the data set.
A single $T$-gate makes distribution learning hard
Jul 07, 2022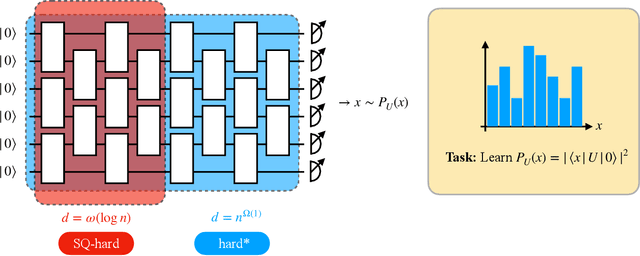
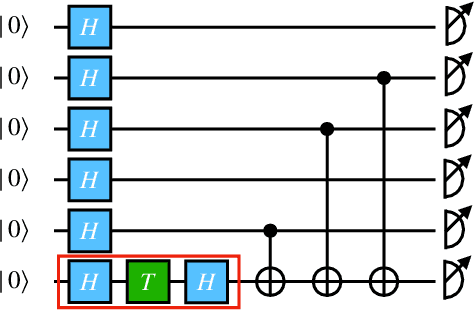
The task of learning a probability distribution from samples is ubiquitous across the natural sciences. The output distributions of local quantum circuits form a particularly interesting class of distributions, of key importance both to quantum advantage proposals and a variety of quantum machine learning algorithms. In this work, we provide an extensive characterization of the learnability of the output distributions of local quantum circuits. Our first result yields insight into the relationship between the efficient learnability and the efficient simulatability of these distributions. Specifically, we prove that the density modelling problem associated with Clifford circuits can be efficiently solved, while for depth $d=n^{\Omega(1)}$ circuits the injection of a single $T$-gate into the circuit renders this problem hard. This result shows that efficient simulatability does not imply efficient learnability. Our second set of results provides insight into the potential and limitations of quantum generative modelling algorithms. We first show that the generative modelling problem associated with depth $d=n^{\Omega(1)}$ local quantum circuits is hard for any learning algorithm, classical or quantum. As a consequence, one cannot use a quantum algorithm to gain a practical advantage for this task. We then show that, for a wide variety of the most practically relevant learning algorithms -- including hybrid-quantum classical algorithms -- even the generative modelling problem associated with depth $d=\omega(\log(n))$ Clifford circuits is hard. This result places limitations on the applicability of near-term hybrid quantum-classical generative modelling algorithms.
Learnability of the output distributions of local quantum circuits
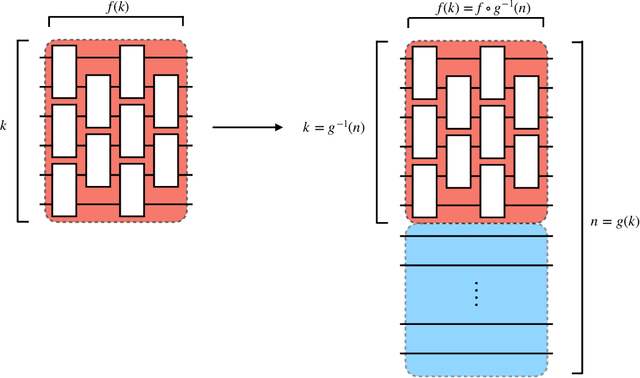
Oct 11, 2021
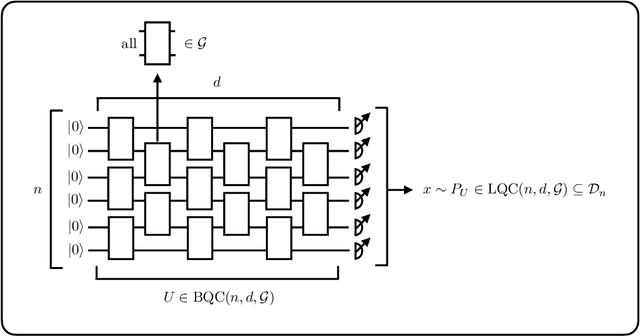
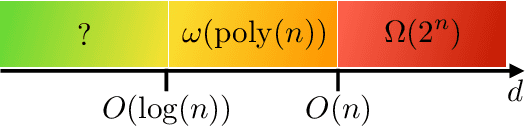
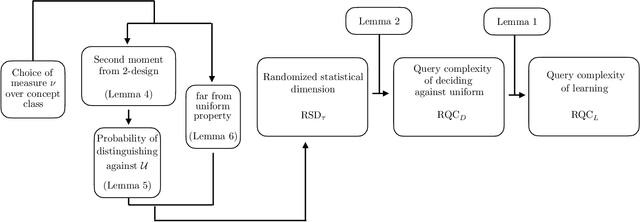
There is currently a large interest in understanding the potential advantages quantum devices can offer for probabilistic modelling. In this work we investigate, within two different oracle models, the probably approximately correct (PAC) learnability of quantum circuit Born machines, i.e., the output distributions of local quantum circuits. We first show a negative result, namely, that the output distributions of super-logarithmic depth Clifford circuits are not sample-efficiently learnable in the statistical query model, i.e., when given query access to empirical expectation values of bounded functions over the sample space. This immediately implies the hardness, for both quantum and classical algorithms, of learning from statistical queries the output distributions of local quantum circuits using any gate set which includes the Clifford group. As many practical generative modelling algorithms use statistical queries -- including those for training quantum circuit Born machines -- our result is broadly applicable and strongly limits the possibility of a meaningful quantum advantage for learning the output distributions of local quantum circuits. As a positive result, we show that in a more powerful oracle model, namely when directly given access to samples, the output distributions of local Clifford circuits are computationally efficiently PAC learnable by a classical learner. Our results are equally applicable to the problems of learning an algorithm for generating samples from the target distribution (generative modelling) and learning an algorithm for evaluating its probabilities (density modelling). They provide the first rigorous insights into the learnability of output distributions of local quantum circuits from the probabilistic modelling perspective.
Encoding-dependent generalization bounds for parametrized quantum circuits
Jun 07, 2021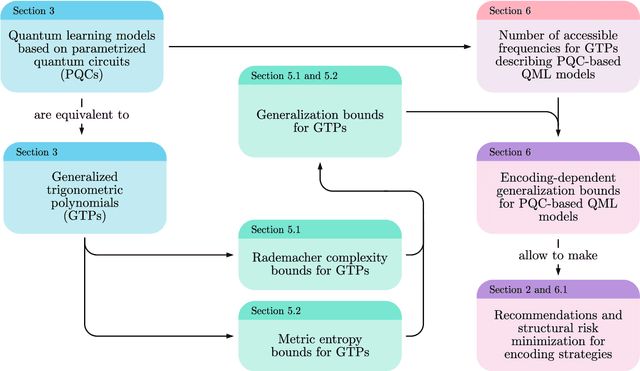
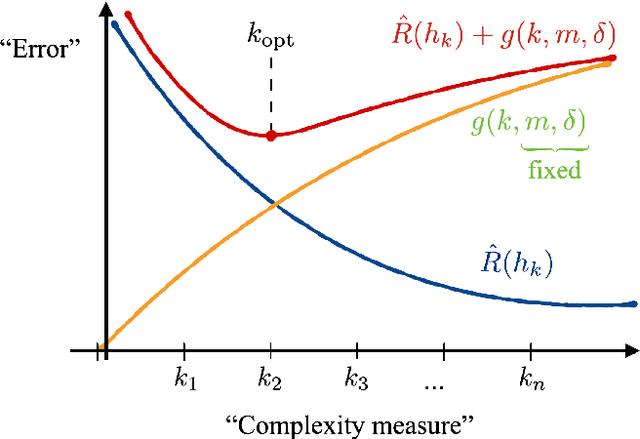
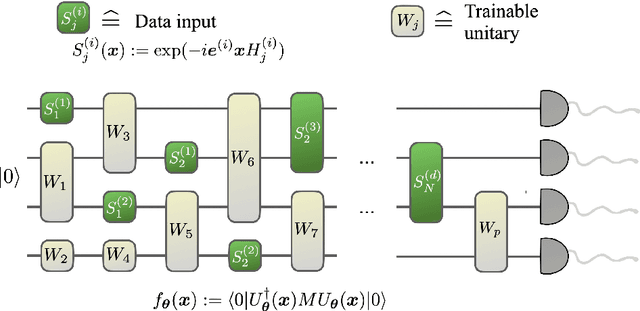

A large body of recent work has begun to explore the potential of parametrized quantum circuits (PQCs) as machine learning models, within the framework of hybrid quantum-classical optimization. In particular, theoretical guarantees on the out-of-sample performance of such models, in terms of generalization bounds, have emerged. However, none of these generalization bounds depend explicitly on how the classical input data is encoded into the PQC. We derive generalization bounds for PQC-based models that depend explicitly on the strategy used for data-encoding. These imply bounds on the performance of trained PQC-based models on unseen data. Moreover, our results facilitate the selection of optimal data-encoding strategies via structural risk minimization, a mathematically rigorous framework for model selection. We obtain our generalization bounds by bounding the complexity of PQC-based models as measured by the Rademacher complexity and the metric entropy, two complexity measures from statistical learning theory. To achieve this, we rely on a representation of PQC-based models via trigonometric functions. Our generalization bounds emphasize the importance of well-considered data-encoding strategies for PQC-based models.