 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeThink Locally, Explain Globally: Graph-Guided LLM Investigations via Local Reasoning and Belief Propagation
Jan 25, 2026LLM agents excel when environments are mostly static and the needed information fits in a model's context window, but they often fail in open-ended investigations where explanations must be constructed by iteratively mining evidence from massive, heterogeneous operational data. These investigations exhibit hidden dependency structure: entities interact, signals co-vary, and the importance of a fact may only become clear after other evidence is discovered. Because the context window is bounded, agents must summarize intermediate findings before their significance is known, increasing the risk of discarding key evidence. ReAct-style agents are especially brittle in this regime. Their retrieve-summarize-reason loop makes conclusions sensitive to exploration order and introduces run-to-run non-determinism, producing a reliability gap where Pass-at-k may be high but Majority-at-k remains low. Simply sampling more rollouts or generating longer reasoning traces does not reliably stabilize results, since hypotheses cannot be autonomously checked as new evidence arrives and there is no explicit mechanism for belief bookkeeping and revision. In addition, ReAct entangles semantic reasoning with controller duties such as tool orchestration and state tracking, so execution errors and plan drift degrade reasoning while consuming scarce context. We address these issues by formulating investigation as abductive reasoning over a dependency graph and proposing EoG (Explanations over Graphs), a disaggregated framework in which an LLM performs bounded local evidence mining and labeling (cause vs symptom) while a deterministic controller manages traversal, state, and belief propagation to compute a minimal explanatory frontier. On a representative ITBench diagnostics task, EoG improves both accuracy and run-to-run consistency over ReAct baselines, including a 7x average gain in Majority-at-k entity F1.
FinOps Agent -- A Use-Case for IT Infrastructure and Cost Optimization
Oct 29, 2025



FinOps (Finance + Operations) represents an operational framework and cultural practice which maximizes cloud business value through collaborative financial accountability across engineering, finance, and business teams. FinOps practitioners face a fundamental challenge: billing data arrives in heterogeneous formats, taxonomies, and metrics from multiple cloud providers and internal systems which eventually lead to synthesizing actionable insights, and making time-sensitive decisions. To address this challenge, we propose leveraging autonomous, goal-driven AI agents for FinOps automation. In this paper, we built a FinOps agent for a typical use-case for IT infrastructure and cost optimization. We built a system simulating a realistic end-to-end industry process starting with retrieving data from various sources to consolidating and analyzing the data to generate recommendations for optimization. We defined a set of metrics to evaluate our agent using several open-source and close-source language models and it shows that the agent was able to understand, plan, and execute tasks as well as an actual FinOps practitioner.
ITBench: Evaluating AI Agents across Diverse Real-World IT Automation Tasks
Feb 07, 2025



Realizing the vision of using AI agents to automate critical IT tasks depends on the ability to measure and understand effectiveness of proposed solutions. We introduce ITBench, a framework that offers a systematic methodology for benchmarking AI agents to address real-world IT automation tasks. Our initial release targets three key areas: Site Reliability Engineering (SRE), Compliance and Security Operations (CISO), and Financial Operations (FinOps). The design enables AI researchers to understand the challenges and opportunities of AI agents for IT automation with push-button workflows and interpretable metrics. ITBench includes an initial set of 94 real-world scenarios, which can be easily extended by community contributions. Our results show that agents powered by state-of-the-art models resolve only 13.8% of SRE scenarios, 25.2% of CISO scenarios, and 0% of FinOps scenarios. We expect ITBench to be a key enabler of AI-driven IT automation that is correct, safe, and fast.
Technical Question Answering across Tasks and Domains
Oct 19, 2020
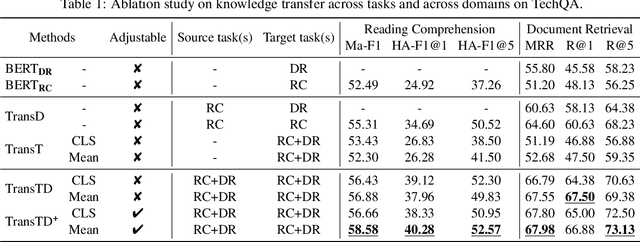

Building automatic technical support system is an important yet challenge task. Conceptually, to answer a user question on a technical forum, a human expert has to first retrieve relevant documents, and then read them carefully to identify the answer snippet. Despite huge success the researchers have achieved in coping with general domain question answering (QA), much less attentions have been paid for investigating technical QA. Specifically, existing methods suffer from several unique challenges (i) the question and answer rarely overlaps substantially and (ii) very limited data size. In this paper, we propose a novel framework of deep transfer learning to effectively address technical QA across tasks and domains. To this end, we present an adjustable joint learning approach for document retrieval and reading comprehension tasks. Our experiments on the TechQA demonstrates superior performance compared with state-of-the-art methods.