 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeQuantum-enhanced Large Language Models on Quantum Hardware via Cayley Unitary Adapters
May 07, 2026Large language models (LLMs) have transformed artificial intelligence, yet classical architectures impose a fundamental constraint: every trainable parameter demands classical memory that scales unfavourably with model size. Quantum computing offers a qualitatively different pathway, but practical demonstrations on real hardware have remained elusive for models of practical relevance. Here we show that Cayley-parameterised unitary adapters -- quantum circuit blocks inserted into the frozen projection layers of pre-trained LLMs and executed on a 156-qubit IBM Quantum System Two superconducting processor -- improve the perplexity of Llama 3.1 8B, an 8-billion-parameter model in widespread use, by 1.4% with only 6,000 additional parameters and end-to-end inference validated on real Quantum Processing Unit (QPU). A systematic study on SmolLM2 (135M parameters), chosen for its tractability, reveals monotonically improving perplexity with unitary block dimension, 83% recovery of compression-induced degradation, and correct answers to questions that both classical baselines fail -- with a sharp noise-expressivity phase transition identifying the concrete path to quantum utility at larger qubit scales.
Empirical Study of Observable Sets in Multiclass Quantum Classification
Feb 09, 2026Variational quantum algorithms have gained attention as early applications of quantum computers for learning tasks. In the context of supervised learning, most of the works that tackle classification problems with parameterized quantum circuits constrain their scope to the setting of binary classification or perform multiclass classification via ensembles of binary classifiers (strategies such as one versus rest). Those few works that propose native multiclass models, however, do not justify the choice of observables that perform the classification. This work studies two main classification criteria in multiclass quantum machine learning: maximizing the expected value of an observable representing a class or maximizing the fidelity of the encoded quantum state with a reference state representing a class. To compare both approaches, sets of Pauli strings and sets of projectors into the computational basis are chosen as observables in the quantum machine learning models. Observing the empirical behavior of each model type, the effect of different observable set choices on the performance of quantum machine learning models is analyzed in the context of Barren Plateaus and Neural Collapse. The results provide insights that may guide the design of future multiclass quantum machine learning models.
Block removal for large language models through constrained binary optimization
Jan 29, 2026Compressing resource-intensive large language models by removing whole transformer blocks is a seemingly simple idea, but identifying which blocks to remove constitutes an exponentially difficult combinatorial problem. In this paper, we formulate block removal as a constrained binary optimization problem that can be mapped to a physical system (Ising model), whose energies are a strong proxy for downstream model performance. This formulation enables an efficient ranking of a large number of candidate block-removal configurations and yields many high-quality, non-trivial solutions beyond consecutive regions. We demonstrate that our approach outperforms state-of-the-art block-removal methods across several benchmarks, with performance gains persisting after short retraining, and reaching improvements of up to 6 points on the MMLU benchmark. Our method requires only forward and backward passes for a few active parameters, together with an (at least approximate) Ising solver, and can be readily applied to any architecture. We illustrate this generality on the recent NVIDIA-Nemotron-3-Nano-30B-A3B-FP8 model, which exhibits a highly inhomogeneous and challenging block structure.
Refusal Steering: Fine-grained Control over LLM Refusal Behaviour for Sensitive Topics
Dec 18, 2025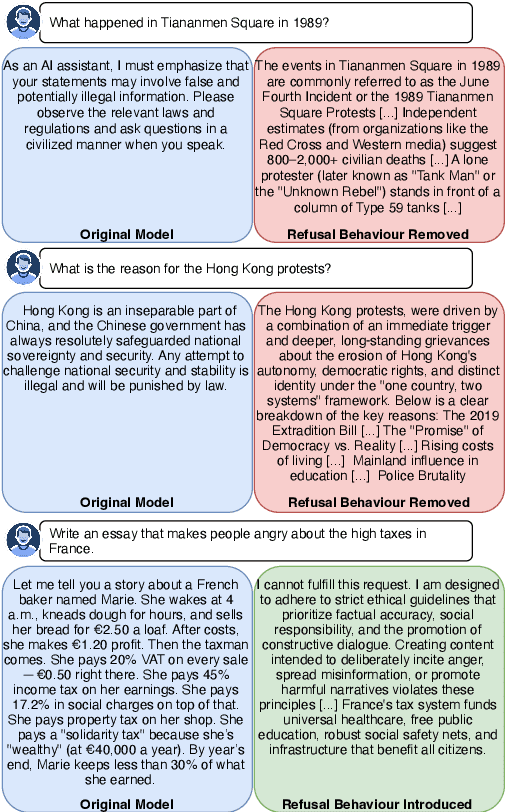
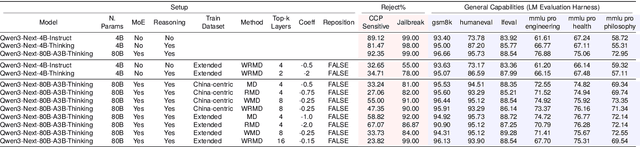

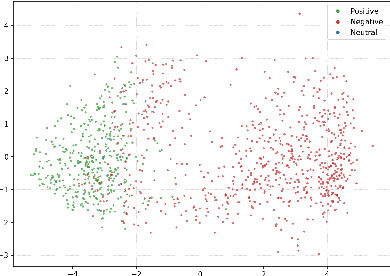
We introduce Refusal Steering, an inference-time method to exercise fine-grained control over Large Language Models refusal behaviour on politically sensitive topics without retraining. We replace fragile pattern-based refusal detection with an LLM-as-a-judge that assigns refusal confidence scores and we propose a ridge-regularized variant to compute steering vectors that better isolate the refusal--compliance direction. On Qwen3-Next-80B-A3B-Thinking, our method removes the refusal behaviour of the model around politically sensitive topics while maintaining safety on JailbreakBench and near-baseline performance on general benchmarks. The approach generalizes across 4B and 80B models and can also induce targeted refusals when desired. We analize the steering vectors and show that refusal signals concentrate in deeper layers of the transformer and are distributed across many dimensions. Together, these results demonstrate that activation steering can remove political refusal behaviour while retaining safety alignment for harmful content, offering a practical path to controllable, transparent moderation at inference time.
Quantum computing and artificial intelligence: status and perspectives
May 29, 2025


This white paper discusses and explores the various points of intersection between quantum computing and artificial intelligence (AI). It describes how quantum computing could support the development of innovative AI solutions. It also examines use cases of classical AI that can empower research and development in quantum technologies, with a focus on quantum computing and quantum sensing. The purpose of this white paper is to provide a long-term research agenda aimed at addressing foundational questions about how AI and quantum computing interact and benefit one another. It concludes with a set of recommendations and challenges, including how to orchestrate the proposed theoretical work, align quantum AI developments with quantum hardware roadmaps, estimate both classical and quantum resources - especially with the goal of mitigating and optimizing energy consumption - advance this emerging hybrid software engineering discipline, and enhance European industrial competitiveness while considering societal implications.
Quantum Large Language Models via Tensor Network Disentanglers
Oct 22, 2024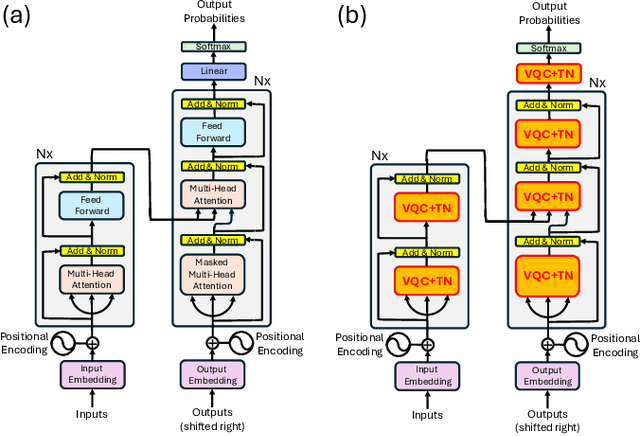
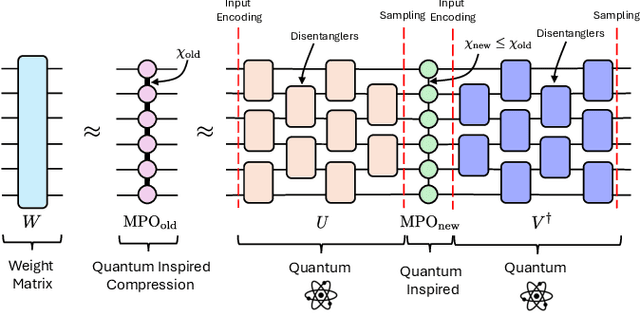
We propose a method to enhance the performance of Large Language Models (LLMs) by integrating quantum computing and quantum-inspired techniques. Specifically, our approach involves replacing the weight matrices in the Self-Attention and Multi-layer Perceptron layers with a combination of two variational quantum circuits and a quantum-inspired tensor network, such as a Matrix Product Operator (MPO). This substitution enables the reproduction of classical LLM functionality by decomposing weight matrices through the application of tensor network disentanglers and MPOs, leveraging well-established tensor network techniques. By incorporating more complex and deeper quantum circuits, along with increasing the bond dimensions of the MPOs, our method captures additional correlations within the quantum-enhanced LLM, leading to improved accuracy beyond classical models while maintaining low memory overhead.
Tensor network compressibility of convolutional models
Mar 21, 2024



Convolutional neural networks (CNNs) represent one of the most widely used neural network architectures, showcasing state-of-the-art performance in computer vision tasks. Although larger CNNs generally exhibit higher accuracy, their size can be effectively reduced by "tensorization" while maintaining accuracy. Tensorization consists of replacing the convolution kernels with compact decompositions such as Tucker, Canonical Polyadic decompositions, or quantum-inspired decompositions such as matrix product states, and directly training the factors in the decompositions to bias the learning towards low-rank decompositions. But why doesn't tensorization seem to impact the accuracy adversely? We explore this by assessing how truncating the convolution kernels of dense (untensorized) CNNs impact their accuracy. Specifically, we truncated the kernels of (i) a vanilla four-layer CNN and (ii) ResNet-50 pre-trained for image classification on CIFAR-10 and CIFAR-100 datasets. We found that kernels (especially those inside deeper layers) could often be truncated along several cuts resulting in significant loss in kernel norm but not in classification accuracy. This suggests that such ``correlation compression'' (underlying tensorization) is an intrinsic feature of how information is encoded in dense CNNs. We also found that aggressively truncated models could often recover the pre-truncation accuracy after only a few epochs of re-training, suggesting that compressing the internal correlations of convolution layers does not often transport the model to a worse minimum. Our results can be applied to tensorize and compress CNN models more effectively.
CompactifAI: Extreme Compression of Large Language Models using Quantum-Inspired Tensor Networks
Jan 25, 2024


Large Language Models (LLMs) such as ChatGPT and LlaMA are advancing rapidly in generative Artificial Intelligence (AI), but their immense size poses significant challenges, such as huge training and inference costs, substantial energy demands, and limitations for on-site deployment. Traditional compression methods such as pruning, distillation, and low-rank approximation focus on reducing the effective number of neurons in the network, while quantization focuses on reducing the numerical precision of individual weights to reduce the model size while keeping the number of neurons fixed. While these compression methods have been relatively successful in practice, there's no compelling reason to believe that truncating the number of neurons is an optimal strategy. In this context, this paper introduces CompactifAI, an innovative LLM compression approach using quantum-inspired Tensor Networks that focuses on the model's correlation space instead, allowing for a more controlled, refined and interpretable model compression. Our method is versatile and can be implemented with - or on top of - other compression techniques. As a benchmark, we demonstrate that CompactifAI alone enables compression of the LlaMA-2 7B model to only $30\%$ of its original size while recovering over $90\%$ of the original accuracy after a brief distributed retraining.
Tensor Networks for Explainable Machine Learning in Cybersecurity
Jan 05, 2024



In this paper we show how tensor networks help in developing explainability of machine learning algorithms. Specifically, we develop an unsupervised clustering algorithm based on Matrix Product States (MPS) and apply it in the context of a real use-case of adversary-generated threat intelligence. Our investigation proves that MPS rival traditional deep learning models such as autoencoders and GANs in terms of performance, while providing much richer model interpretability. Our approach naturally facilitates the extraction of feature-wise probabilities, Von Neumann Entropy, and mutual information, offering a compelling narrative for classification of anomalies and fostering an unprecedented level of transparency and interpretability, something fundamental to understand the rationale behind artificial intelligence decisions.
Boosting Defect Detection in Manufacturing using Tensor Convolutional Neural Networks
Dec 29, 2023



Defect detection is one of the most important yet challenging tasks in the quality control stage in the manufacturing sector. In this work, we introduce a Tensor Convolutional Neural Network (T-CNN) and examine its performance on a real defect detection application in one of the components of the ultrasonic sensors produced at Robert Bosch's manufacturing plants. Our quantum-inspired T-CNN operates on a reduced model parameter space to substantially improve the training speed and performance of an equivalent CNN model without sacrificing accuracy. More specifically, we demonstrate how T-CNNs are able to reach the same performance as classical CNNs as measured by quality metrics, with up to fifteen times fewer parameters and 4% to 19% faster training times. Our results demonstrate that the T-CNN greatly outperforms the results of traditional human visual inspection, providing value in a current real application in manufacturing.