 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeOpenAI o1 System Card
Dec 21, 2024



The o1 model series is trained with large-scale reinforcement learning to reason using chain of thought. These advanced reasoning capabilities provide new avenues for improving the safety and robustness of our models. In particular, our models can reason about our safety policies in context when responding to potentially unsafe prompts, through deliberative alignment. This leads to state-of-the-art performance on certain benchmarks for risks such as generating illicit advice, choosing stereotyped responses, and succumbing to known jailbreaks. Training models to incorporate a chain of thought before answering has the potential to unlock substantial benefits, while also increasing potential risks that stem from heightened intelligence. Our results underscore the need for building robust alignment methods, extensively stress-testing their efficacy, and maintaining meticulous risk management protocols. This report outlines the safety work carried out for the OpenAI o1 and OpenAI o1-mini models, including safety evaluations, external red teaming, and Preparedness Framework evaluations.
A Unified View of SDP-based Neural Network Verification through Completely Positive Programming
Mar 06, 2022
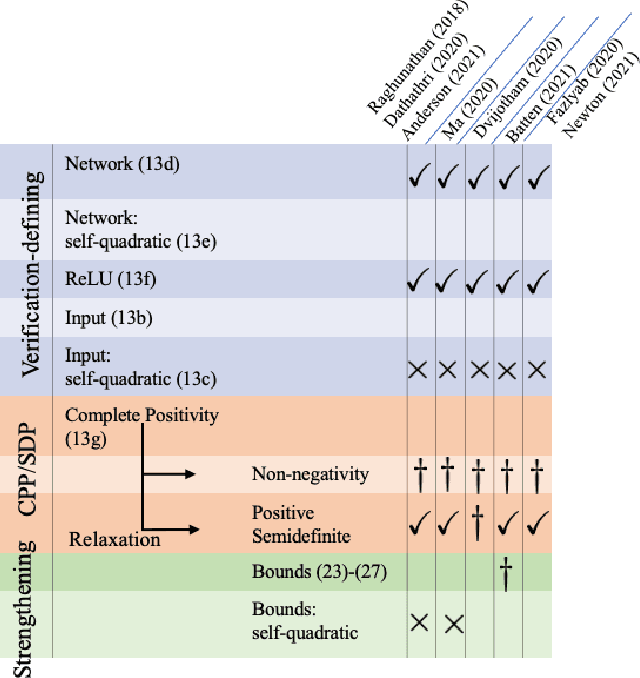
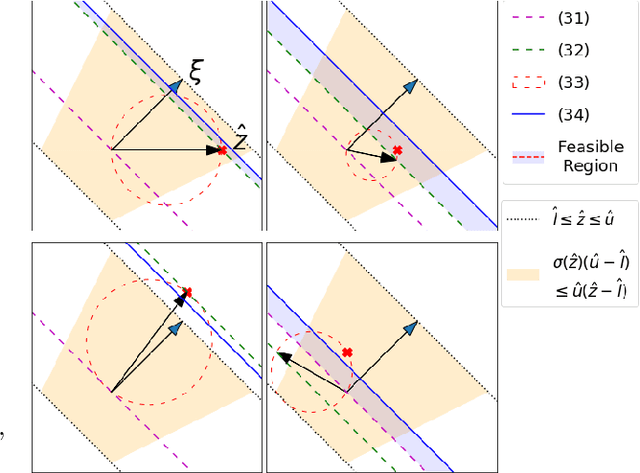
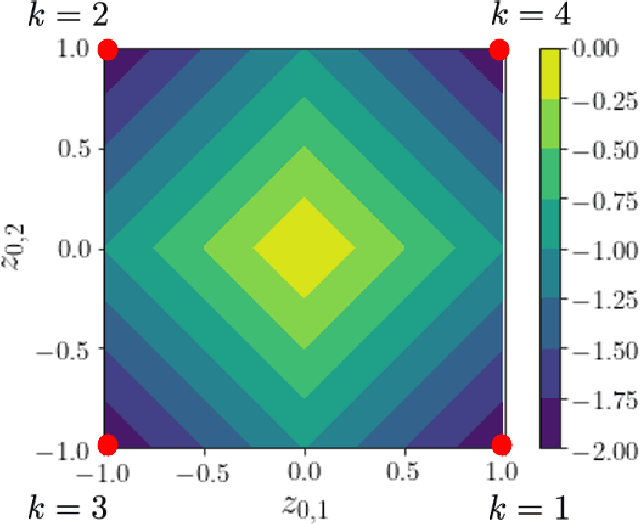
Verifying that input-output relationships of a neural network conform to prescribed operational specifications is a key enabler towards deploying these networks in safety-critical applications. Semidefinite programming (SDP)-based approaches to Rectified Linear Unit (ReLU) network verification transcribe this problem into an optimization problem, where the accuracy of any such formulation reflects the level of fidelity in how the neural network computation is represented, as well as the relaxations of intractable constraints. While the literature contains much progress on improving the tightness of SDP formulations while maintaining tractability, comparatively little work has been devoted to the other extreme, i.e., how to most accurately capture the original verification problem before SDP relaxation. In this work, we develop an exact, convex formulation of verification as a completely positive program (CPP), and provide analysis showing that our formulation is minimal -- the removal of any constraint fundamentally misrepresents the neural network computation. We leverage our formulation to provide a unifying view of existing approaches, and give insight into the source of large relaxation gaps observed in some cases.
On Local Computation for Optimization in Multi-Agent Systems
Mar 03, 2020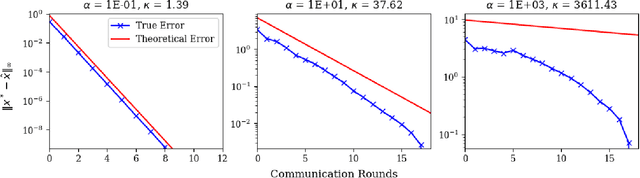

A number of prototypical optimization problems in multi-agent systems (e.g., task allocation and network load-sharing) exhibit a highly local structure: that is, each agent's decision variables are only directly coupled to few other agent's variables through the objective function or the constraints. Nevertheless, existing algorithms for distributed optimization generally do not exploit the locality structure of the problem, requiring all agents to compute or exchange the full set of decision variables. In this paper, we develop a rigorous notion of "locality" that quantifies the degree to which agents can compute their portion of the global solution based solely on information in their local neighborhood. This notion provides a theoretical basis for a rather simple algorithm in which agents individually solve a truncated sub-problem of the global problem, where the size of the sub-problem used depends on the locality of the problem, and the desired accuracy. Numerical results show that the proposed theoretical bounds are remarkably tight for well-conditioned problems.