 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeSupply Risk-Aware Alloy Discovery and Design
Sep 22, 2024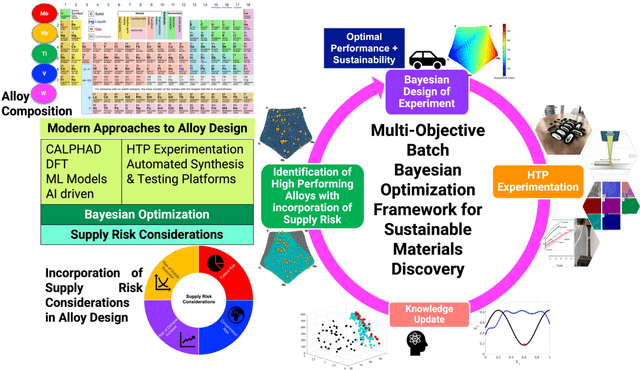

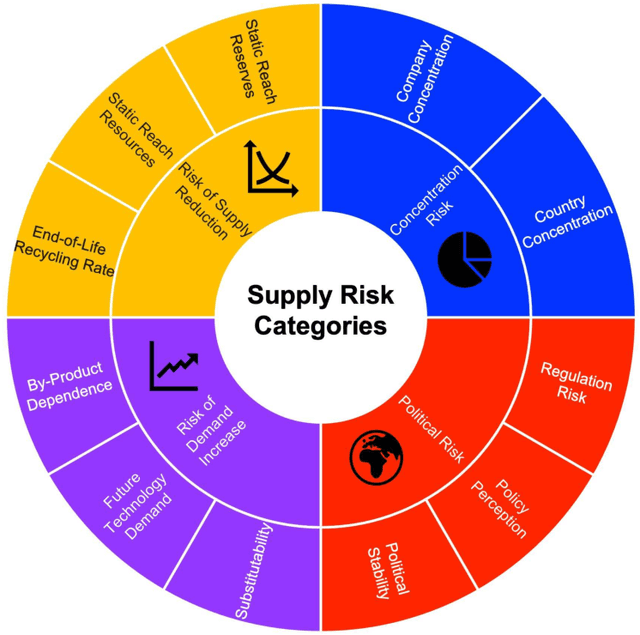
Materials design is a critical driver of innovation, yet overlooking the technological, economic, and environmental risks inherent in materials and their supply chains can lead to unsustainable and risk-prone solutions. To address this, we present a novel risk-aware design approach that integrates Supply-Chain Aware Design Strategies into the materials development process. This approach leverages existing language models and text analysis to develop a specialized model for predicting materials feedstock supply risk indices. To efficiently navigate the multi-objective, multi-constraint design space, we employ Batch Bayesian Optimization (BBO), enabling the identification of Pareto-optimal high entropy alloys (HEAs) that balance performance objectives with minimized supply risk. A case study using the MoNbTiVW system demonstrates the efficacy of our approach in four scenarios, highlighting the significant impact of incorporating supply risk into the design process. By optimizing for both performance and supply risk, we ensure that the developed alloys are not only high-performing but also sustainable and economically viable. This integrated approach represents a critical step towards a future where materials discovery and design seamlessly consider sustainability, supply chain dynamics, and comprehensive life cycle analysis.
Assessing gender bias in medical and scientific masked language models with StereoSet
Nov 15, 2021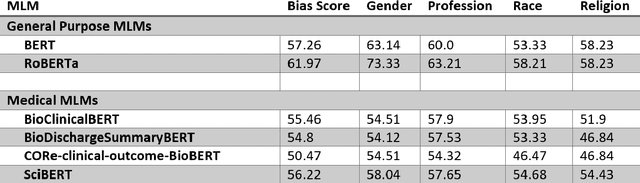
NLP systems use language models such as Masked Language Models (MLMs) that are pre-trained on large quantities of text such as Wikipedia create representations of language. BERT is a powerful and flexible general-purpose MLM system developed using unlabeled text. Pre-training on large quantities of text also has the potential to transparently embed the cultural and social biases found in the source text into the MLM system. This study aims to compare biases in general purpose and medical MLMs with the StereoSet bias assessment tool. The general purpose MLMs showed significant bias overall, with BERT scoring 57 and RoBERTa scoring 61. The category of gender bias is where the best performances were found, with 63 for BERT and 73 for RoBERTa. Performances for profession, race, and religion were similar to the overall bias scores for the general-purpose MLMs.Medical MLMs showed more bias in all categories than the general-purpose MLMs except for SciBERT, which showed a race bias score of 55, which was superior to the race bias score of 53 for BERT. More gender (Medical 54-58 vs. General 63-73) and religious (46-54 vs. 58) biases were found with medical MLMs. This evaluation of four medical MLMs for stereotyped assessments about race, gender, religion, and profession showed inferior performance to general-purpose MLMs. These medically focused MLMs differ considerably in training source data, which is likely the root cause of the differences in ratings for stereotyped biases from the StereoSet tool.
Machine Learning with Multi-Site Imaging Data: An Empirical Study on the Impact of Scanner Effects
Oct 10, 2019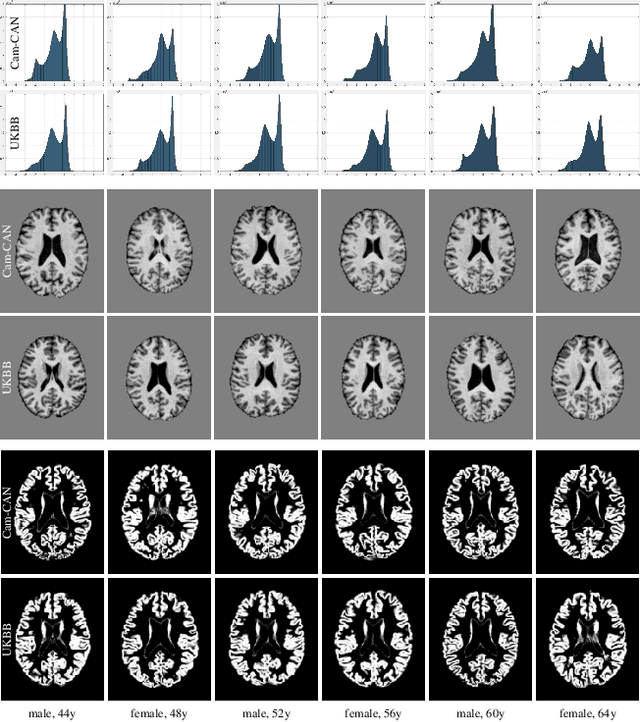
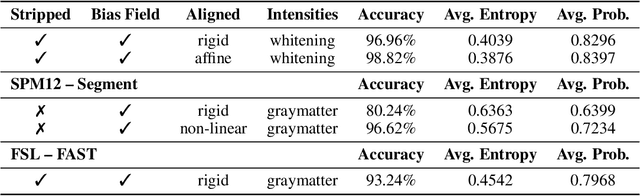
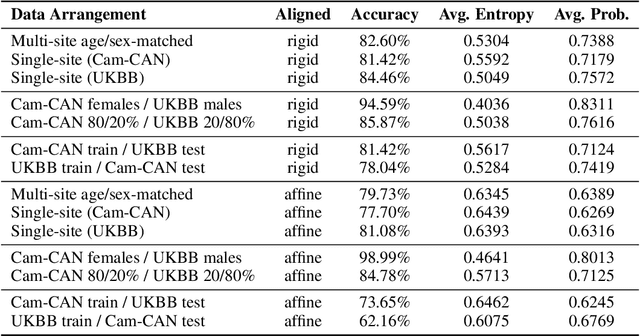
This is an empirical study to investigate the impact of scanner effects when using machine learning on multi-site neuroimaging data. We utilize structural T1-weighted brain MRI obtained from two different studies, Cam-CAN and UK Biobank. For the purpose of our investigation, we construct a dataset consisting of brain scans from 592 age- and sex-matched individuals, 296 subjects from each original study. Our results demonstrate that even after careful pre-processing with state-of-the-art neuroimaging pipelines a classifier can easily distinguish between the origin of the data with very high accuracy. Our analysis on the example application of sex classification suggests that current approaches to harmonize data are unable to remove scanner-specific bias leading to overly optimistic performance estimates and poor generalization. We conclude that multi-site data harmonization remains an open challenge and particular care needs to be taken when using such data with advanced machine learning methods for predictive modelling.
Automated Quality Control in Image Segmentation: Application to the UK Biobank Cardiac MR Imaging Study
Jan 27, 2019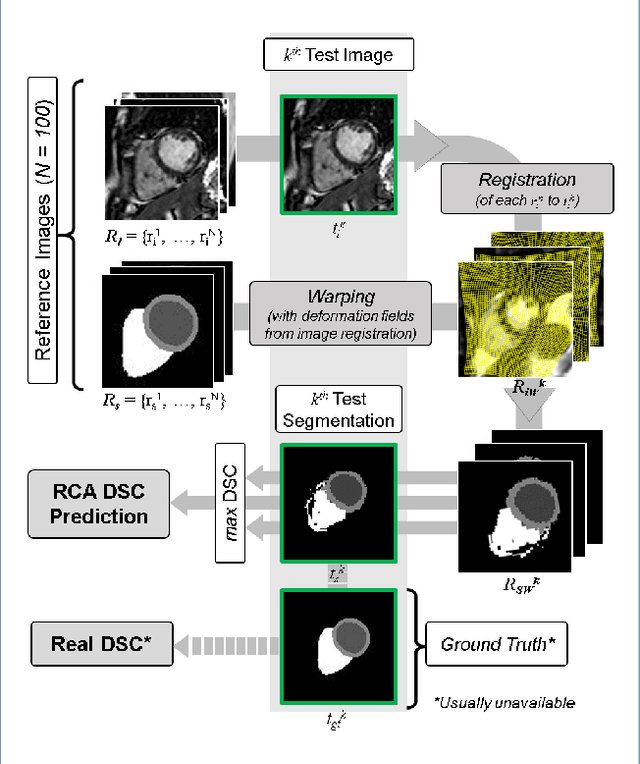
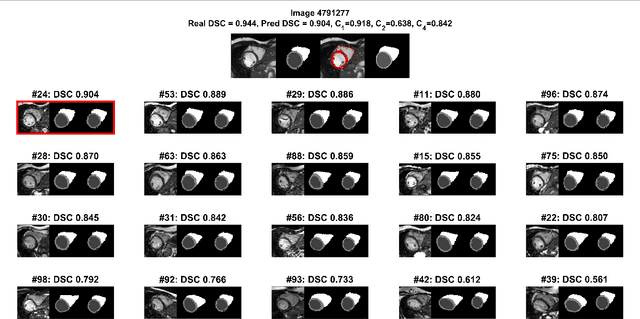
Background: The trend towards large-scale studies including population imaging poses new challenges in terms of quality control (QC). This is a particular issue when automatic processing tools, e.g. image segmentation methods, are employed to derive quantitative measures or biomarkers for later analyses. Manual inspection and visual QC of each segmentation isn't feasible at large scale. However, it's important to be able to automatically detect when a segmentation method fails so as to avoid inclusion of wrong measurements into subsequent analyses which could lead to incorrect conclusions. Methods: To overcome this challenge, we explore an approach for predicting segmentation quality based on Reverse Classification Accuracy, which enables us to discriminate between successful and failed segmentations on a per-cases basis. We validate this approach on a new, large-scale manually-annotated set of 4,800 cardiac magnetic resonance scans. We then apply our method to a large cohort of 7,250 cardiac MRI on which we have performed manual QC. Results: We report results used for predicting segmentation quality metrics including Dice Similarity Coefficient (DSC) and surface-distance measures. As initial validation, we present data for 400 scans demonstrating 99% accuracy for classifying low and high quality segmentations using predicted DSC scores. As further validation we show high correlation between real and predicted scores and 95% classification accuracy on 4,800 scans for which manual segmentations were available. We mimic real-world application of the method on 7,250 cardiac MRI where we show good agreement between predicted quality metrics and manual visual QC scores. Conclusions: We show that RCA has the potential for accurate and fully automatic segmentation QC on a per-case basis in the context of large-scale population imaging as in the UK Biobank Imaging Study.
Real-time Prediction of Segmentation Quality
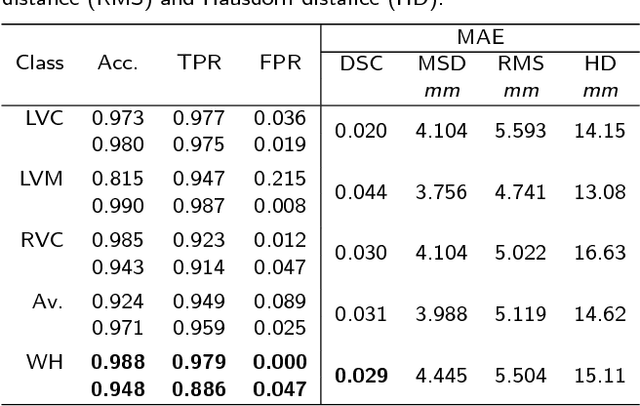
Jun 16, 2018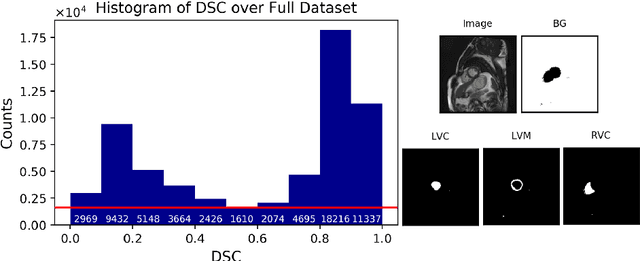
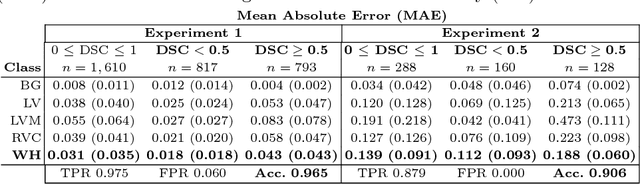
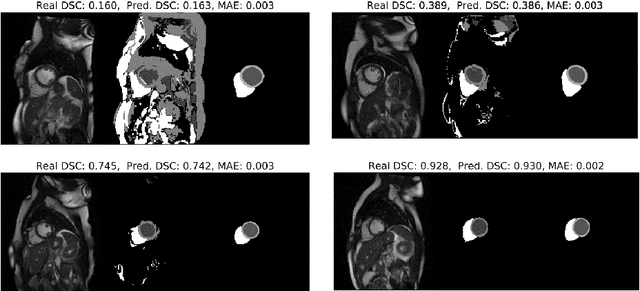
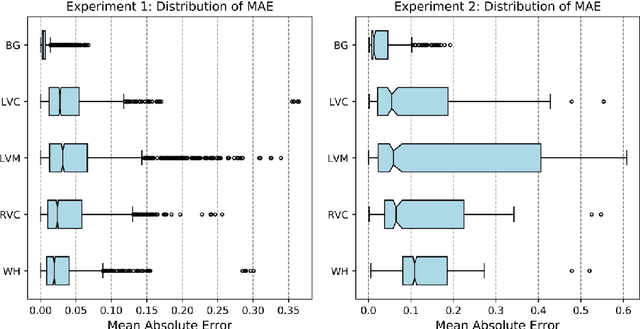
Recent advances in deep learning based image segmentation methods have enabled real-time performance with human-level accuracy. However, occasionally even the best method fails due to low image quality, artifacts or unexpected behaviour of black box algorithms. Being able to predict segmentation quality in the absence of ground truth is of paramount importance in clinical practice, but also in large-scale studies to avoid the inclusion of invalid data in subsequent analysis. In this work, we propose two approaches of real-time automated quality control for cardiovascular MR segmentations using deep learning. First, we train a neural network on 12,880 samples to predict Dice Similarity Coefficients (DSC) on a per-case basis. We report a mean average error (MAE) of 0.03 on 1,610 test samples and 97% binary classification accuracy for separating low and high quality segmentations. Secondly, in the scenario where no manually annotated data is available, we train a network to predict DSC scores from estimated quality obtained via a reverse testing strategy. We report an MAE=0.14 and 91% binary classification accuracy for this case. Predictions are obtained in real-time which, when combined with real-time segmentation methods, enables instant feedback on whether an acquired scan is analysable while the patient is still in the scanner. This further enables new applications of optimising image acquisition towards best possible analysis results.