 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeAutomated Quality Control in Image Segmentation: Application to the UK Biobank Cardiac MR Imaging Study
Jan 27, 2019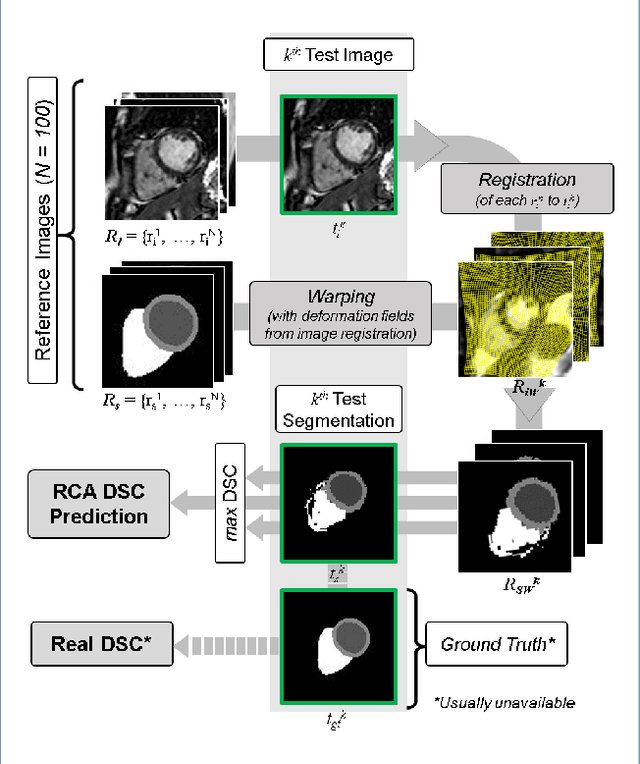
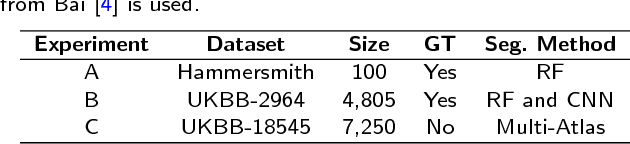
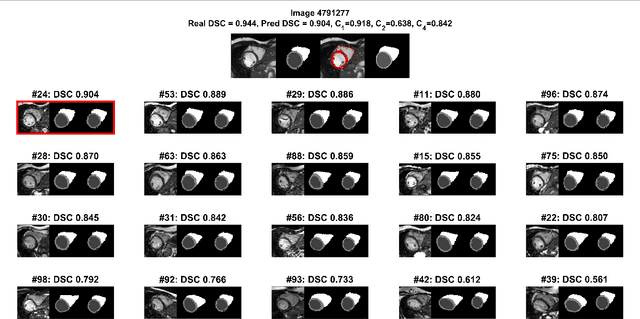
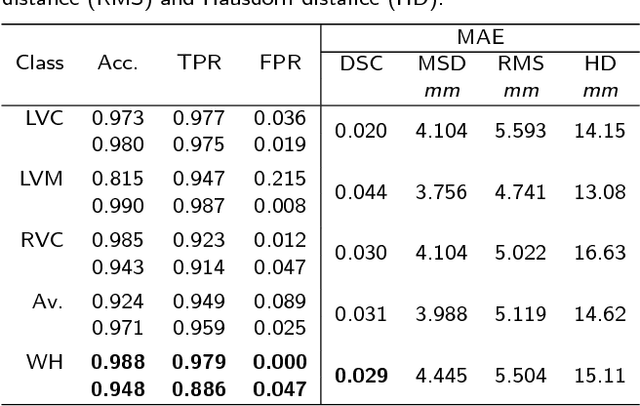
Background: The trend towards large-scale studies including population imaging poses new challenges in terms of quality control (QC). This is a particular issue when automatic processing tools, e.g. image segmentation methods, are employed to derive quantitative measures or biomarkers for later analyses. Manual inspection and visual QC of each segmentation isn't feasible at large scale. However, it's important to be able to automatically detect when a segmentation method fails so as to avoid inclusion of wrong measurements into subsequent analyses which could lead to incorrect conclusions. Methods: To overcome this challenge, we explore an approach for predicting segmentation quality based on Reverse Classification Accuracy, which enables us to discriminate between successful and failed segmentations on a per-cases basis. We validate this approach on a new, large-scale manually-annotated set of 4,800 cardiac magnetic resonance scans. We then apply our method to a large cohort of 7,250 cardiac MRI on which we have performed manual QC. Results: We report results used for predicting segmentation quality metrics including Dice Similarity Coefficient (DSC) and surface-distance measures. As initial validation, we present data for 400 scans demonstrating 99% accuracy for classifying low and high quality segmentations using predicted DSC scores. As further validation we show high correlation between real and predicted scores and 95% classification accuracy on 4,800 scans for which manual segmentations were available. We mimic real-world application of the method on 7,250 cardiac MRI where we show good agreement between predicted quality metrics and manual visual QC scores. Conclusions: We show that RCA has the potential for accurate and fully automatic segmentation QC on a per-case basis in the context of large-scale population imaging as in the UK Biobank Imaging Study.
Small Organ Segmentation in Whole-body MRI using a Two-stage FCN and Weighting Schemes
Jul 30, 2018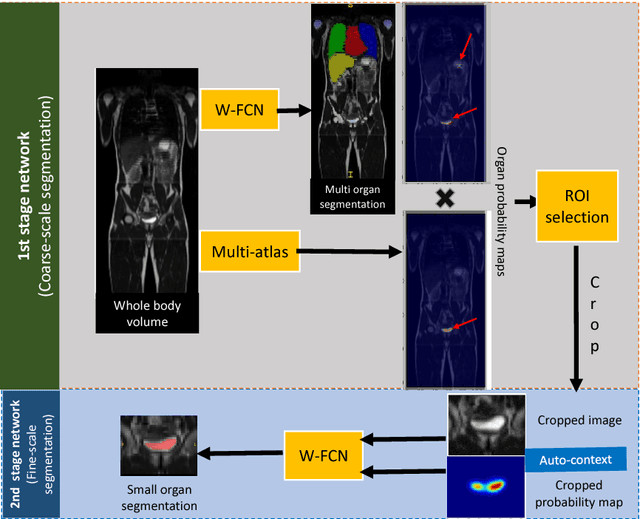

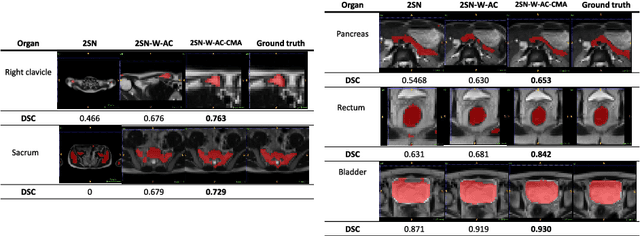
Accurate and robust segmentation of small organs in whole-body MRI is difficult due to anatomical variation and class imbalance. Recent deep network based approaches have demonstrated promising performance on abdominal multi-organ segmentations. However, the performance on small organs is still suboptimal as these occupy only small regions of the whole-body volumes with unclear boundaries and variable shapes. A coarse-to-fine, hierarchical strategy is a common approach to alleviate this problem, however, this might miss useful contextual information. We propose a two-stage approach with weighting schemes based on auto-context and spatial atlas priors. Our experiments show that the proposed approach can boost the segmentation accuracy of multiple small organs in whole-body MRI scans.
Domain Adaptation for MRI Organ Segmentation using Reverse Classification Accuracy
Jun 01, 2018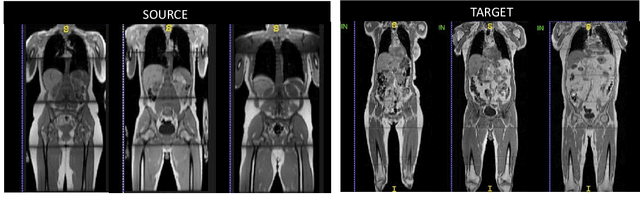

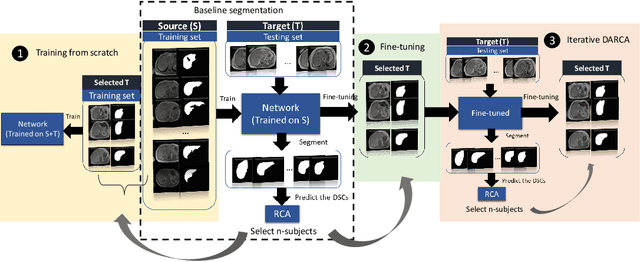
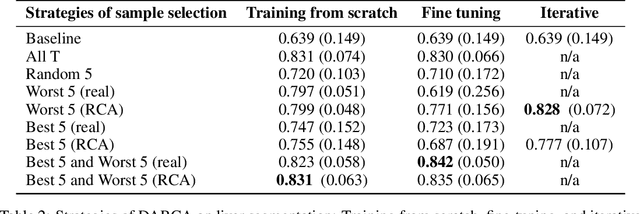
The variations in multi-center data in medical imaging studies have brought the necessity of domain adaptation. Despite the advancement of machine learning in automatic segmentation, performance often degrades when algorithms are applied on new data acquired from different scanners or sequences than the training data. Manual annotation is costly and time consuming if it has to be carried out for every new target domain. In this work, we investigate automatic selection of suitable subjects to be annotated for supervised domain adaptation using the concept of reverse classification accuracy (RCA). RCA predicts the performance of a trained model on data from the new domain and different strategies of selecting subjects to be included in the adaptation via transfer learning are evaluated. We perform experiments on a two-center MR database for the task of organ segmentation. We show that subject selection via RCA can reduce the burden of annotation of new data for the target domain.