 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeText Summarization Using Large Language Models: A Comparative Study of MPT-7b-instruct, Falcon-7b-instruct, and OpenAI Chat-GPT Models
Oct 17, 2023
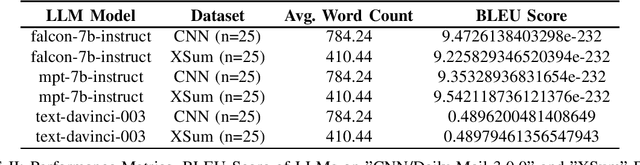
Text summarization is a critical Natural Language Processing (NLP) task with applications ranging from information retrieval to content generation. Leveraging Large Language Models (LLMs) has shown remarkable promise in enhancing summarization techniques. This paper embarks on an exploration of text summarization with a diverse set of LLMs, including MPT-7b-instruct, falcon-7b-instruct, and OpenAI ChatGPT text-davinci-003 models. The experiment was performed with different hyperparameters and evaluated the generated summaries using widely accepted metrics such as the Bilingual Evaluation Understudy (BLEU) Score, Recall-Oriented Understudy for Gisting Evaluation (ROUGE) Score, and Bidirectional Encoder Representations from Transformers (BERT) Score. According to the experiment, text-davinci-003 outperformed the others. This investigation involved two distinct datasets: CNN Daily Mail and XSum. Its primary objective was to provide a comprehensive understanding of the performance of Large Language Models (LLMs) when applied to different datasets. The assessment of these models' effectiveness contributes valuable insights to researchers and practitioners within the NLP domain. This work serves as a resource for those interested in harnessing the potential of LLMs for text summarization and lays the foundation for the development of advanced Generative AI applications aimed at addressing a wide spectrum of business challenges.
Real-time Prediction of Segmentation Quality
Jun 16, 2018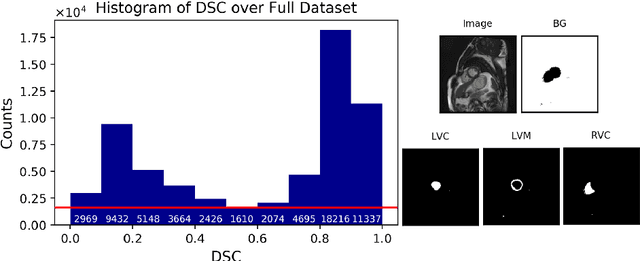
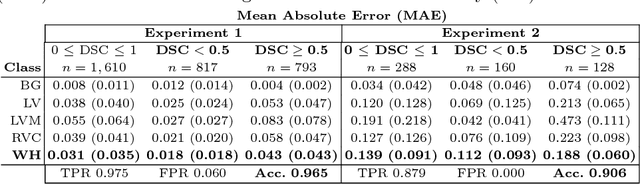
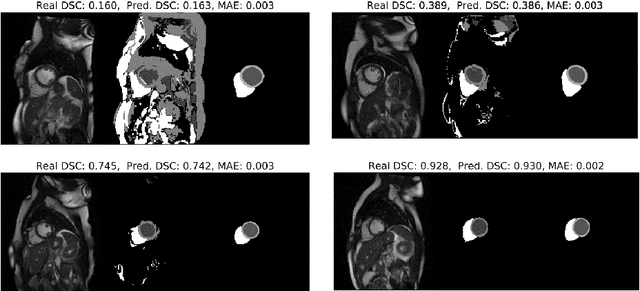
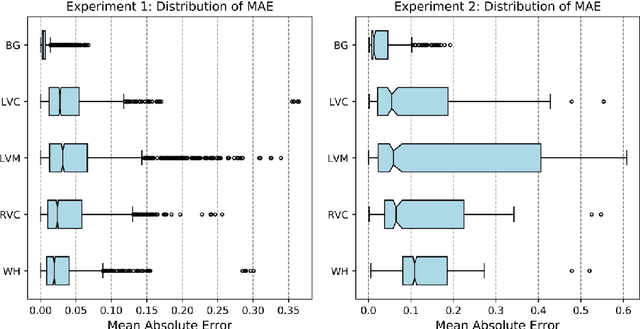
Recent advances in deep learning based image segmentation methods have enabled real-time performance with human-level accuracy. However, occasionally even the best method fails due to low image quality, artifacts or unexpected behaviour of black box algorithms. Being able to predict segmentation quality in the absence of ground truth is of paramount importance in clinical practice, but also in large-scale studies to avoid the inclusion of invalid data in subsequent analysis. In this work, we propose two approaches of real-time automated quality control for cardiovascular MR segmentations using deep learning. First, we train a neural network on 12,880 samples to predict Dice Similarity Coefficients (DSC) on a per-case basis. We report a mean average error (MAE) of 0.03 on 1,610 test samples and 97% binary classification accuracy for separating low and high quality segmentations. Secondly, in the scenario where no manually annotated data is available, we train a network to predict DSC scores from estimated quality obtained via a reverse testing strategy. We report an MAE=0.14 and 91% binary classification accuracy for this case. Predictions are obtained in real-time which, when combined with real-time segmentation methods, enables instant feedback on whether an acquired scan is analysable while the patient is still in the scanner. This further enables new applications of optimising image acquisition towards best possible analysis results.