 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeText Summarization Using Large Language Models: A Comparative Study of MPT-7b-instruct, Falcon-7b-instruct, and OpenAI Chat-GPT Models
Paper and Code
Oct 17, 2023
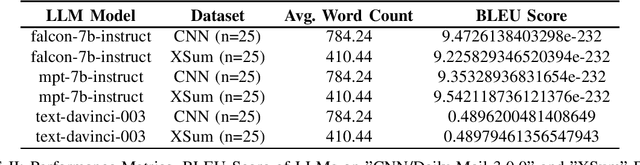
Text summarization is a critical Natural Language Processing (NLP) task with applications ranging from information retrieval to content generation. Leveraging Large Language Models (LLMs) has shown remarkable promise in enhancing summarization techniques. This paper embarks on an exploration of text summarization with a diverse set of LLMs, including MPT-7b-instruct, falcon-7b-instruct, and OpenAI ChatGPT text-davinci-003 models. The experiment was performed with different hyperparameters and evaluated the generated summaries using widely accepted metrics such as the Bilingual Evaluation Understudy (BLEU) Score, Recall-Oriented Understudy for Gisting Evaluation (ROUGE) Score, and Bidirectional Encoder Representations from Transformers (BERT) Score. According to the experiment, text-davinci-003 outperformed the others. This investigation involved two distinct datasets: CNN Daily Mail and XSum. Its primary objective was to provide a comprehensive understanding of the performance of Large Language Models (LLMs) when applied to different datasets. The assessment of these models' effectiveness contributes valuable insights to researchers and practitioners within the NLP domain. This work serves as a resource for those interested in harnessing the potential of LLMs for text summarization and lays the foundation for the development of advanced Generative AI applications aimed at addressing a wide spectrum of business challenges.