 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeSemi-Instrumental Variables: A Test for Instrument Admissibility
Jan 10, 2013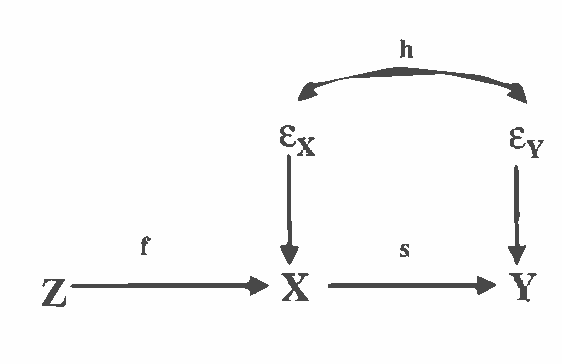
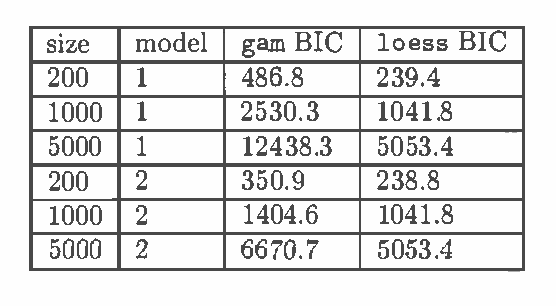
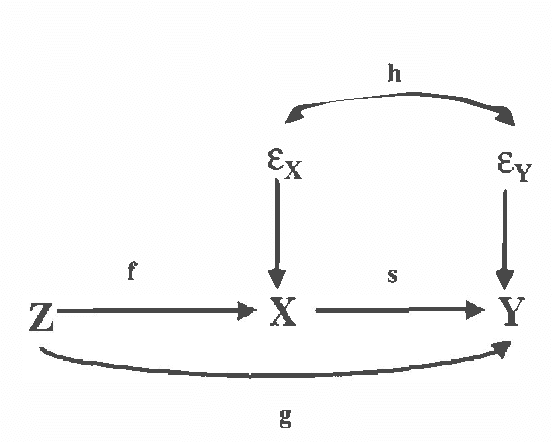

In a causal graphical model, an instrument for a variable X and its effect Y is a random variable that is a cause of X and independent of all the causes of Y except X. (Pearl (1995), Spirtes et al (2000)). Instrumental variables can be used to estimate how the distribution of an effect will respond to a manipulation of its causes, even in the presence of unmeasured common causes (confounders). In typical instrumental variable estimation, instruments are chosen based on domain knowledge. There is currently no statistical test for validating a variable as an instrument. In this paper, we introduce the concept of semi-instrument, which generalizes the concept of instrument. We show that in the framework of additive models, under certain conditions, we can test whether a variable is semi-instrumental. Moreover, adding some distribution assumptions, we can test whether two semi-instruments are instrumental. We give algorithms to estimate the p-value that a random variable is semi-instrumental, and the p-value that two semi-instruments are both instrumental. These algorithms can be used to test the experts' choice of instruments, or to identify instruments automatically.
Learning Measurement Models for Unobserved Variables
Oct 19, 2012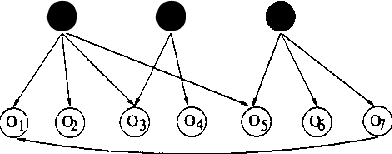
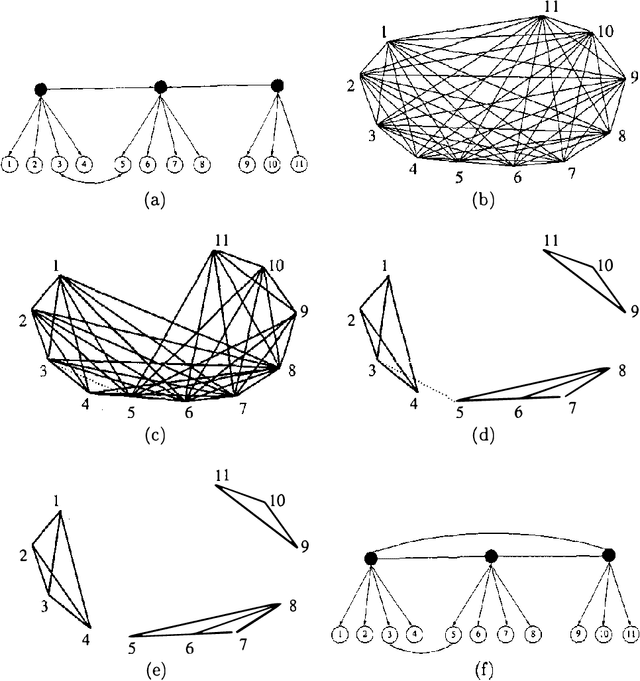

Observed associations in a database may be due in whole or part to variations in unrecorded (latent) variables. Identifying such variables and their causal relationships with one another is a principal goal in many scientific and practical domains. Previous work shows that, given a partition of observed variables such that members of a class share only a single latent common cause, standard search algorithms for causal Bayes nets can infer structural relations between latent variables. We introduce an algorithm for discovering such partitions when they exist. Uniquely among available procedures, the algorithm is (asymptotically) correct under standard assumptions in causal Bayes net search algorithms, requires no prior knowledge of the number of latent variables, and does not depend on the mathematical form of the relationships among the latent variables. We evaluate the algorithm on a variety of simulated data sets.
On the Number of Experiments Sufficient and in the Worst Case Necessary to Identify All Causal Relations Among N Variables
Jul 04, 2012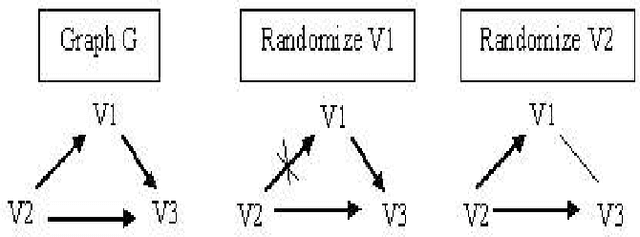
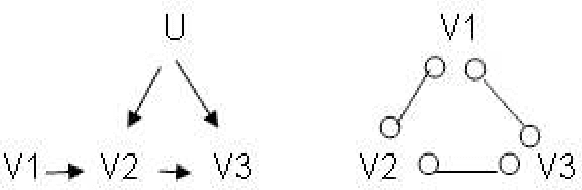
We show that if any number of variables are allowed to be simultaneously and independently randomized in any one experiment, log2(N) + 1 experiments are sufficient and in the worst case necessary to determine the causal relations among N >= 2 variables when no latent variables, no sample selection bias and no feedback cycles are present. For all K, 0 < K < 1/(2N) we provide an upper bound on the number experiments required to determine causal structure when each experiment simultaneously randomizes K variables. For large N, these bounds are significantly lower than the N - 1 bound required when each experiment randomizes at most one variable. For kmax < N/2, we show that (N/kmax-1)+N/(2kmax)log2(kmax) experiments aresufficient and in the worst case necessary. We over a conjecture as to the minimal number of experiments that are in the worst case sufficient to identify all causal relations among N observed variables that are a subset of the vertices of a DAG.
Causal discovery of linear acyclic models with arbitrary distributions
Jun 13, 2012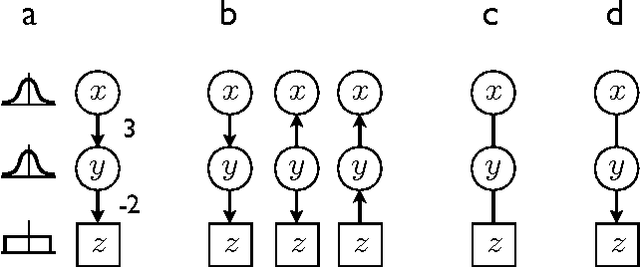


An important task in data analysis is the discovery of causal relationships between observed variables. For continuous-valued data, linear acyclic causal models are commonly used to model the data-generating process, and the inference of such models is a well-studied problem. However, existing methods have significant limitations. Methods based on conditional independencies (Spirtes et al. 1993; Pearl 2000) cannot distinguish between independence-equivalent models, whereas approaches purely based on Independent Component Analysis (Shimizu et al. 2006) are inapplicable to data which is partially Gaussian. In this paper, we generalize and combine the two approaches, to yield a method able to learn the model structure in many cases for which the previous methods provide answers that are either incorrect or are not as informative as possible. We give exact graphical conditions for when two distinct models represent the same family of distributions, and empirically demonstrate the power of our method through thorough simulations.