 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeClassification of the Cervical Vertebrae Maturation (CVM) stages Using the Tripod Network
Nov 15, 2022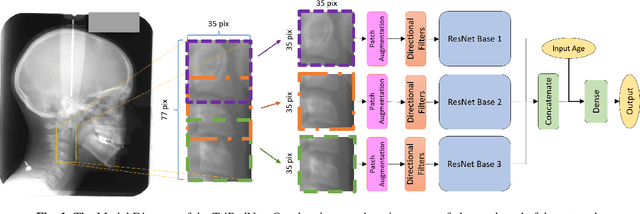


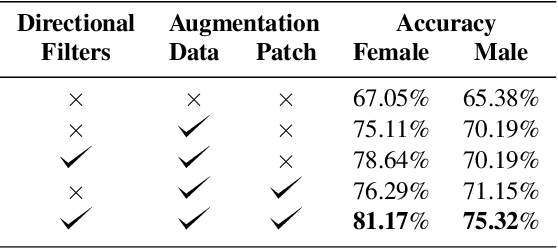
We present a novel deep learning method for fully automated detection and classification of the Cervical Vertebrae Maturation (CVM) stages. The deep convolutional neural network consists of three parallel networks (TriPodNet) independently trained with different initialization parameters. They also have a built-in set of novel directional filters that highlight the Cervical Verte edges in X-ray images. Outputs of the three parallel networks are combined using a fully connected layer. 1018 cephalometric radiographs were labeled, divided by gender, and classified according to the CVM stages. Resulting images, using different training techniques and patches, were used to train TripodNet together with a set of tunable directional edge enhancers. Data augmentation is implemented to avoid overfitting. TripodNet achieves the state-of-the-art accuracy of 81.18\% in female patients and 75.32\% in male patients. The proposed TripodNet achieves a higher accuracy in our dataset than the Swin Transformers and the previous network models that we investigated for CVM stage estimation.
Improved EEG Classification by factoring in sensor topography
May 22, 2019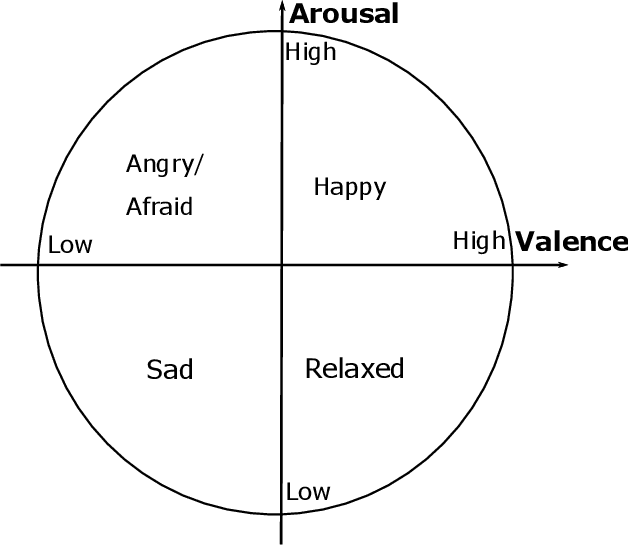
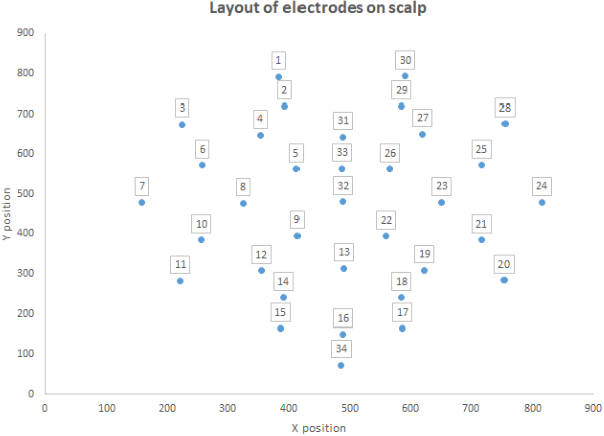
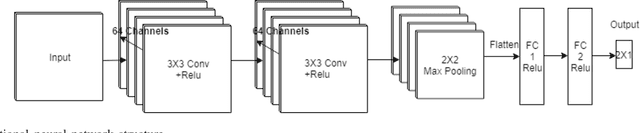
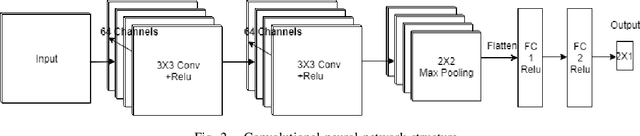
Electroencephalography (EEG) serves as an effective diagnostic tool for mental disorders and neurological abnormalities. Enhanced analysis and classification of EEG signals can help improve detection performance. This work presents a new approach that seeks to exploit the knowledge of EEG sensor spatial configuration to achieve higher detection accuracy. Two classification models, one which ignores the configuration (model 1) and one that exploits it with different interpolation methods (model 2), are studied. The analysis is based on the information content of these signals represented in two different ways: concatenation of the channels of the frequency bands and an image-like 2D representation of the EEG channel locations. Performance of these models is examined on two tasks, social anxiety disorder (SAD) detection, and emotion recognition using DEAP dataset. Validity of our hypothesis that model 2 will significantly outperform model 1 is borne out in the results, with accuracy $5$--$8\%$ higher for model 2 for each machine learning algorithm we investigated. Convolutional Neural Networks (CNN) were found to provide much better performance than SVM and kNNs.
EEG Classification based on Image Configuration in Social Anxiety Disorder
Dec 07, 2018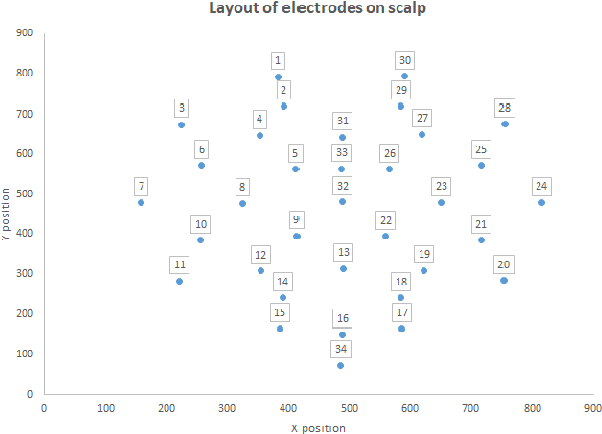
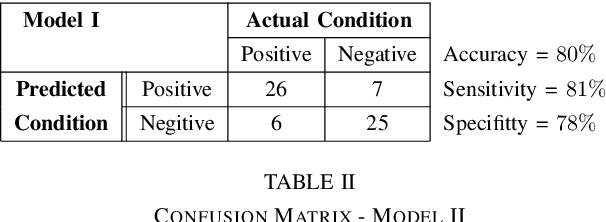
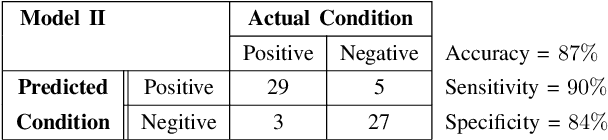
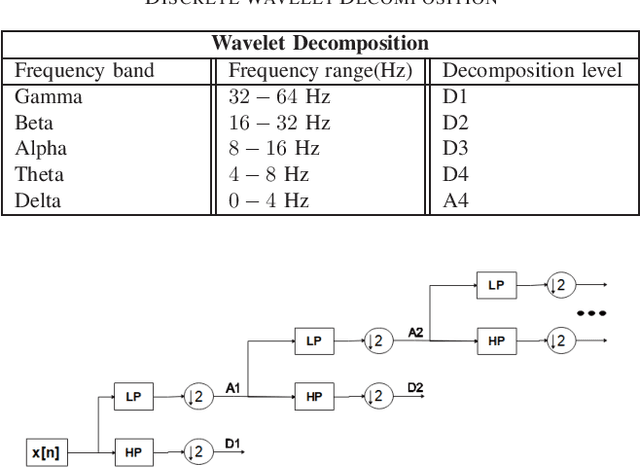
The problem of detecting the presence of Social Anxiety Disorder (SAD) using Electroencephalography (EEG) for classification has seen limited study and is addressed with a new approach that seeks to exploit the knowledge of EEG sensor spatial configuration. Two classification models, one which ignores the configuration (model 1) and one that exploits it with different interpolation methods (model 2), are studied. Performance of these two models is examined for analyzing 34 EEG data channels each consisting of five frequency bands and further decomposed with a filter bank. The data are collected from 64 subjects consisting of healthy controls and patients with SAD. Validity of our hypothesis that model 2 will significantly outperform model 1 is borne out in the results, with accuracy $6$--$7\%$ higher for model 2 for each machine learning algorithm we investigated. Convolutional Neural Networks (CNN) were found to provide much better performance than SVM and kNNs.
Automated Pain Detection from Facial Expressions using FACS: A Review
Nov 13, 2018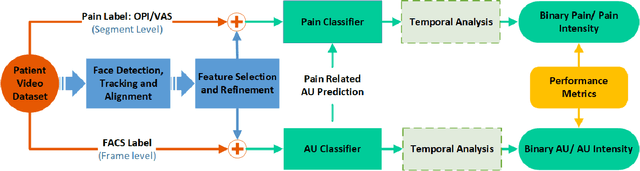
Facial pain expression is an important modality for assessing pain, especially when the patient's verbal ability to communicate is impaired. The facial muscle-based action units (AUs), which are defined by the Facial Action Coding System (FACS), have been widely studied and are highly reliable as a method for detecting facial expressions (FE) including valid detection of pain. Unfortunately, FACS coding by humans is a very time-consuming task that makes its clinical use prohibitive. Significant progress on automated facial expression recognition (AFER) has led to its numerous successful applications in FACS-based affective computing problems. However, only a handful of studies have been reported on automated pain detection (APD), and its application in clinical settings is still far from a reality. In this paper, we review the progress in research that has contributed to automated pain detection, with focus on 1) the framework-level similarity between spontaneous AFER and APD problems; 2) the evolution of system design including the recent development of deep learning methods; 3) the strategies and considerations in developing a FACS-based pain detection framework from existing research; and 4) introduction of the most relevant databases that are available for AFER and APD studies. We attempt to present key considerations in extending a general AFER framework to an APD framework in clinical settings. In addition, the performance metrics are also highlighted in evaluating an AFER or an APD system.
Learning Pain from Action Unit Combinations: A Weakly Supervised Approach via Multiple Instance Learning
Feb 20, 2018



Patient pain can be detected highly reliably from facial expressions using a set of facial muscle-based action units (AUs) defined by the Facial Action Coding System (FACS). A key characteristic of facial expression of pain is the simultaneous occurrence of pain-related AU combinations, whose automated detection would be highly beneficial for efficient and practical pain monitoring. Existing general Automated Facial Expression Recognition (AFER) systems prove inadequate when applied specifically for detecting pain as they either focus on detecting individual pain-related AUs but not on combinations or they seek to bypass AU detection by training a binary pain classifier directly on pain intensity data but are limited by lack of enough labeled data for satisfactory training. In this paper, we propose a new approach that mimics the strategy of human coders of decoupling pain detection into two consecutive tasks: one performed at the individual video-frame level and the other at video-sequence level. Using state-of-the-art AFER tools to detect single AUs at the frame level, we propose two novel data structures to encode AU combinations from single AU scores. Two weakly supervised learning frameworks namely multiple instance learning (MIL) and multiple clustered instance learning (MCIL) are employed corresponding to each data structure to learn pain from video sequences. Experimental results show an 87% pain recognition accuracy with 0.94 AUC (Area Under Curve) on the UNBC-McMaster Shoulder Pain Expression dataset. Tests on long videos in a lung cancer patient video dataset demonstrates the potential value of the proposed system for pain monitoring in clinical settings.
Efficient refinement of GPS-based localization in urban areas using visual information and sensor parameter
Oct 28, 2015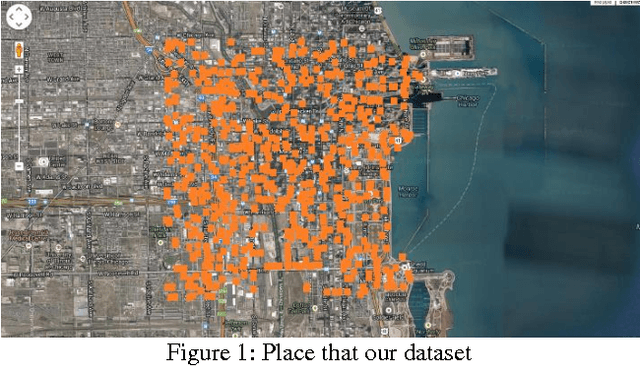
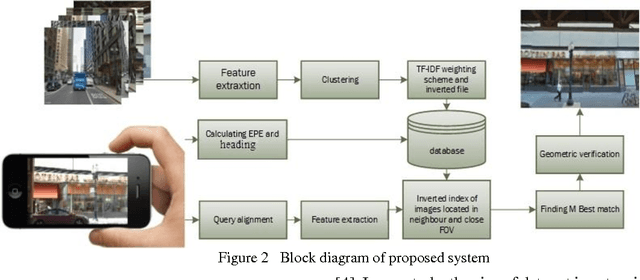
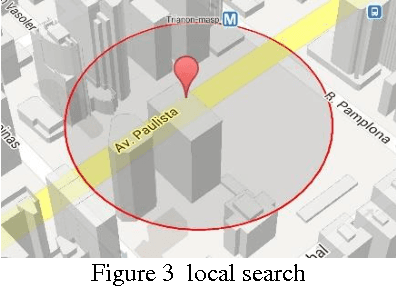
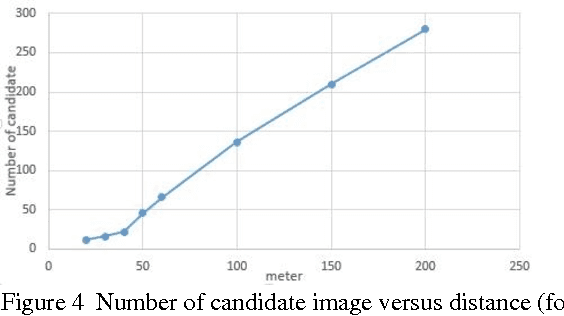
An efficient method is proposed for refining GPS-acquired location coordinates in urban areas using camera images, Google Street View (GSV) and sensor parameters. The main goal is to compensate for GPS location imprecision in dense area of cities due to proximity to walls and buildings. Avail-able methods for better localization often use visual information by using query images acquired with camera-equipped mobile devices and applying image retrieval techniques to find the closest match in a GPS-referenced image data set. The search areas required for reliable search are about 1-2 sq. Km and the accuracy is typically 25-100 meters. Here we describe a method based on image retrieval where a reliable search can be confined to areas of 0.01 sq. Km and the accuracy in our experiments is less than 10 meters. To test our procedure we created a database by acquiring all Google Street View images close to what is seen by a pedestrian in a large region of downtown Chicago and saved all coordinates and orientation data to be used for confining our search region. Prior knowledge from approximate position of query image is leveraged to address complexity and accuracy issues of our search in a large scale geo-tagged data set. One key aspect that differentiates our work is that it utilizes the sensor information of GPS SOS and the camera orientation in improving localization. Finally we demonstrate retrieval-based technique are less accurate in sparse open areas compared with purely GPS measurement. The effectiveness of our approach is discussed in detail and experimental results show improved performance when compared with regular approaches.