 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeStein Variational Gradient Descent-based Detection For Random Access With Preambles In MTC
Sep 15, 2023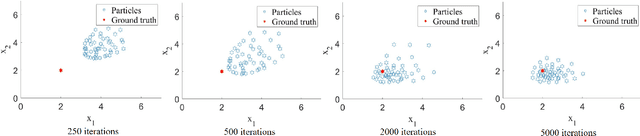
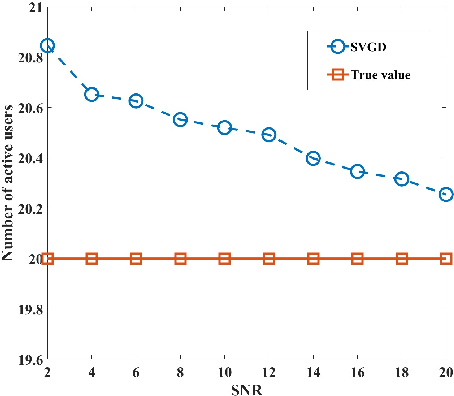
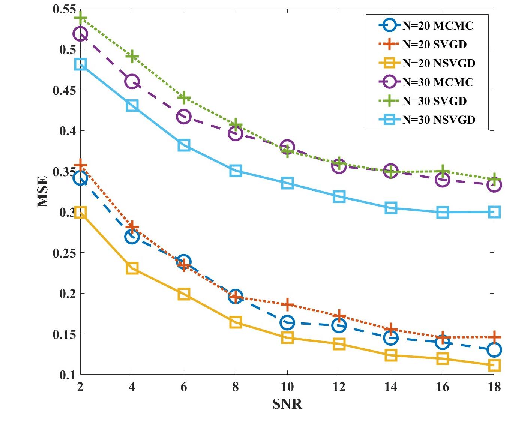
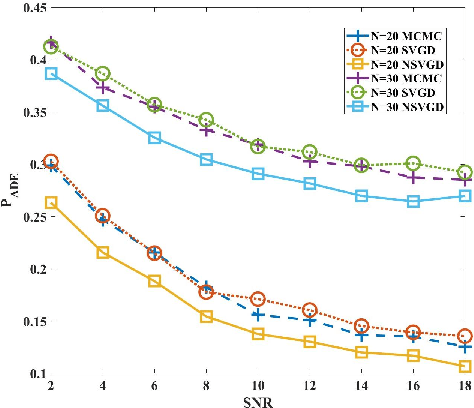
Traditional preamble detection algorithms have low accuracy in the grant-based random access scheme in massive machine-type communication (mMTC). We present a novel preamble detection algorithm based on Stein variational gradient descent (SVGD) at the second step of the random access procedure. It efficiently leverages deterministic updates of particles for continuous inference. To further enhance the performance of the SVGD detector, especially in a dense user scenario, we propose a normalized SVGD detector with momentum. It utilizes the momentum and a bias correction term to reduce the preamble estimation errors during the gradient descent process. Simulation results show that the proposed algorithm performs better than Markov Chain Monte Carlo-based approaches in terms of detection accuracy.
A Hybrid Quantum-Classical Approach based on the Hadamard Transform for the Convolutional Layer
May 31, 2023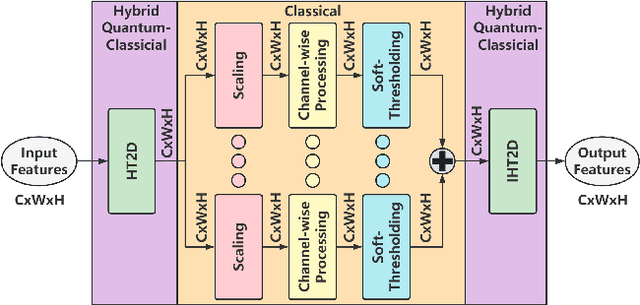

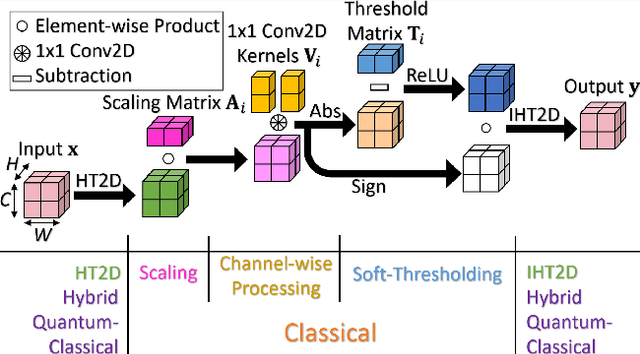
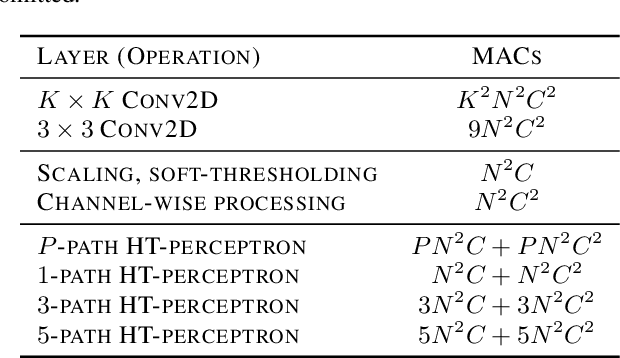
In this paper, we propose a novel Hadamard Transform (HT)-based neural network layer for hybrid quantum-classical computing. It implements the regular convolutional layers in the Hadamard transform domain. The idea is based on the HT convolution theorem which states that the dyadic convolution between two vectors is equivalent to the element-wise multiplication of their HT representation. Computing the HT is simply the application of a Hadamard gate to each qubit individually, so the HT computations of our proposed layer can be implemented on a quantum computer. Compared to the regular Conv2D layer, the proposed HT-perceptron layer is computationally more efficient. Compared to a CNN with the same number of trainable parameters and 99.26\% test accuracy, our HT network reaches 99.31\% test accuracy with 57.1\% MACs reduced in the MNIST dataset; and in our ImageNet-1K experiments, our HT-based ResNet-50 exceeds the accuracy of the baseline ResNet-50 by 0.59\% center-crop top-1 accuracy using 11.5\% fewer parameters with 12.6\% fewer MACs.
Orthogonal Transform Domain Approaches for the Convolutional Layer
Mar 13, 2023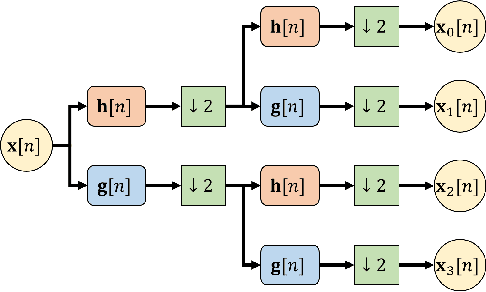
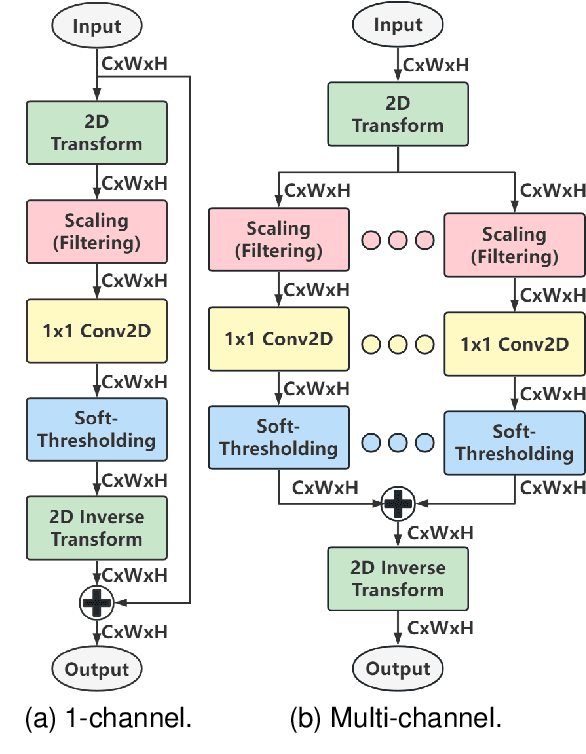
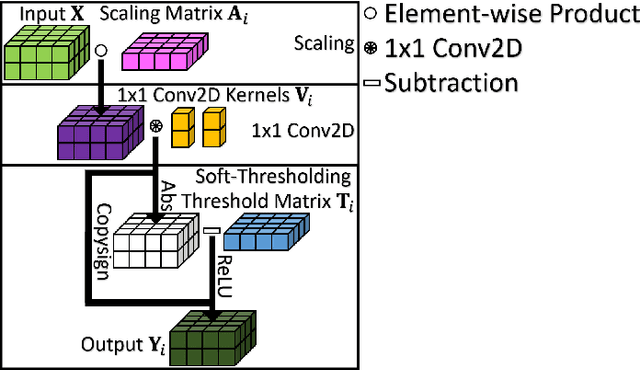
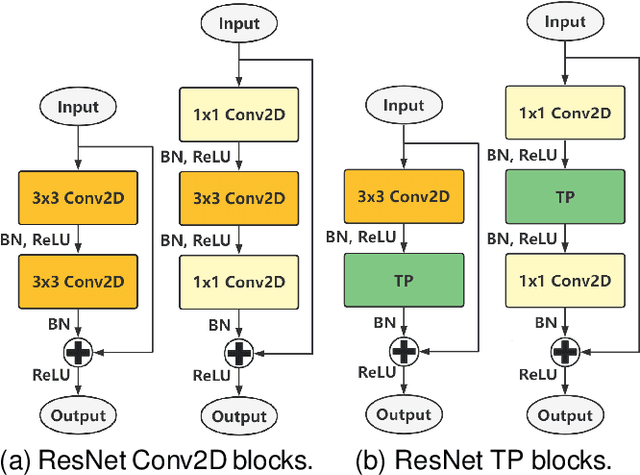
In this paper, we propose a set of transform-based neural network layers as an alternative to the $3\times3$ Conv2D layers in Convolutional Neural Networks (CNNs). The proposed layers can be implemented based on orthogonal transforms such as Discrete Cosine Transform (DCT) and Hadamard transform (HT), and the biorthogonal Block Wavelet Transform (BWT). Convolutional filtering operations are performed in the transform domain using element-wise multiplications by taking advantage of the convolution theorems. Trainable soft-thresholding layers that remove noise in the transform domain bring nonlinearity to the transform domain layers. Compared to the Conv2D layer which is spatial-agnostic and channel-specific, the proposed layers are location-specific and channel-specific. The proposed layers reduce the number of parameters and multiplications significantly while improving the accuracy results of regular ResNets on the ImageNet-1K classification task. Furthermore, the proposed layers can be inserted with a batch normalization layer before the global average pooling layer in the conventional ResNets as an additional layer to improve classification accuracy with a negligible increase in the number of parameters and computational cost.
Normalized Stochastic Gradient Descent Training of Deep Neural Networks
Dec 20, 2022
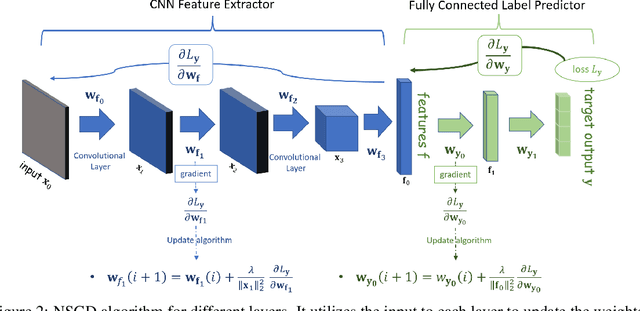

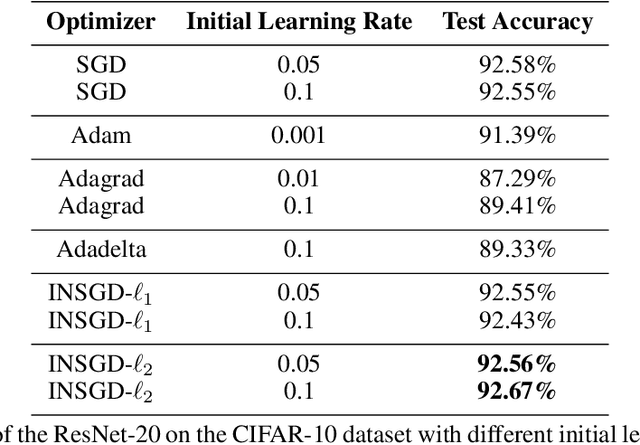
In this paper, we introduce a novel optimization algorithm for machine learning model training called Normalized Stochastic Gradient Descent (NSGD) inspired by Normalized Least Mean Squares (NLMS) from adaptive filtering. When we train a high-complexity model on a large dataset, the learning rate is significantly important as a poor choice of optimizer parameters can lead to divergence. The algorithm updates the new set of network weights using the stochastic gradient but with $\ell_1$ and $\ell_2$-based normalizations on the learning rate parameter similar to the NLMS algorithm. Our main difference from the existing normalization methods is that we do not include the error term in the normalization process. We normalize the update term using the input vector to the neuron. Our experiments present that the model can be trained to a better accuracy level on different initial settings using our optimization algorithm. In this paper, we demonstrate the efficiency of our training algorithm using ResNet-20 and a toy neural network on different benchmark datasets with different initializations. The NSGD improves the accuracy of the ResNet-20 from 91.96\% to 92.20\% on the CIFAR-10 dataset.
DCT Perceptron Layer: A Transform Domain Approach for Convolution Layer
Nov 15, 2022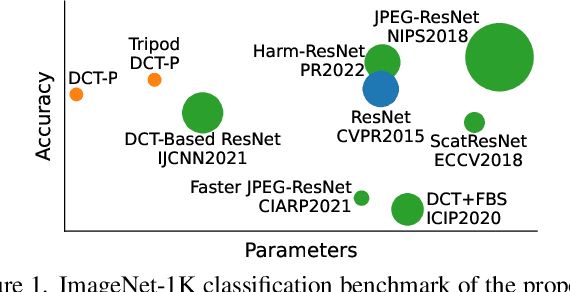

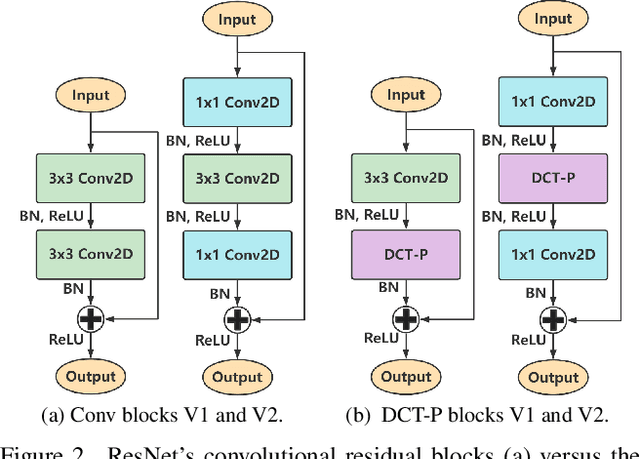

In this paper, we propose a novel Discrete Cosine Transform (DCT)-based neural network layer which we call DCT-perceptron to replace the $3\times3$ Conv2D layers in the Residual neural Network (ResNet). Convolutional filtering operations are performed in the DCT domain using element-wise multiplications by taking advantage of the Fourier and DCT Convolution theorems. A trainable soft-thresholding layer is used as the nonlinearity in the DCT perceptron. Compared to ResNet's Conv2D layer which is spatial-agnostic and channel-specific, the proposed layer is location-specific and channel-specific. The DCT-perceptron layer reduces the number of parameters and multiplications significantly while maintaining comparable accuracy results of regular ResNets in CIFAR-10 and ImageNet-1K. Moreover, the DCT-perceptron layer can be inserted with a batch normalization layer before the global average pooling layer in the conventional ResNets as an additional layer to improve classification accuracy.
Classification of the Cervical Vertebrae Maturation (CVM) stages Using the Tripod Network
Nov 15, 2022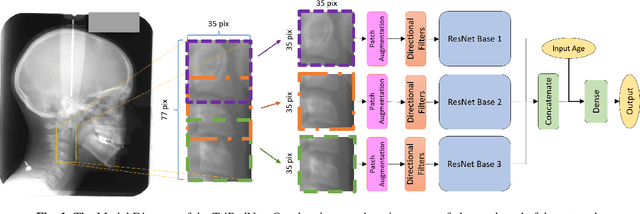


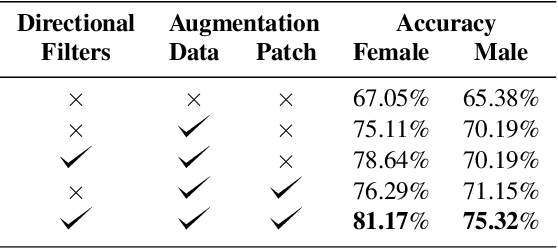
We present a novel deep learning method for fully automated detection and classification of the Cervical Vertebrae Maturation (CVM) stages. The deep convolutional neural network consists of three parallel networks (TriPodNet) independently trained with different initialization parameters. They also have a built-in set of novel directional filters that highlight the Cervical Verte edges in X-ray images. Outputs of the three parallel networks are combined using a fully connected layer. 1018 cephalometric radiographs were labeled, divided by gender, and classified according to the CVM stages. Resulting images, using different training techniques and patches, were used to train TripodNet together with a set of tunable directional edge enhancers. Data augmentation is implemented to avoid overfitting. TripodNet achieves the state-of-the-art accuracy of 81.18\% in female patients and 75.32\% in male patients. The proposed TripodNet achieves a higher accuracy in our dataset than the Swin Transformers and the previous network models that we investigated for CVM stage estimation.
Multipod Convolutional Network
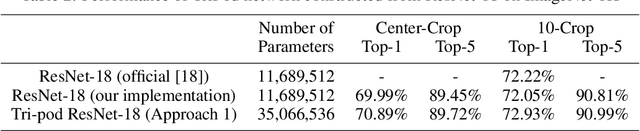
Oct 03, 2022


In this paper, we introduce a convolutional network which we call MultiPodNet consisting of a combination of two or more convolutional networks which process the input image in parallel to achieve the same goal. Output feature maps of parallel convolutional networks are fused at the fully connected layer of the network. We experimentally observed that three parallel pod networks (TripodNet) produce the best results in commonly used object recognition datasets. Baseline pod networks can be of any type. In this paper, we use ResNets as baseline networks and their inputs are augmented image patches. The number of parameters of the TripodNet is about three times that of a single ResNet. We train the TripodNet using the standard backpropagation type algorithms. In each individual ResNet, parameters are initialized with different random numbers during training. The TripodNet achieved state-of-the-art performance on CIFAR-10 and ImageNet datasets. For example, it improved the accuracy of a single ResNet from 91.66% to 92.47% under the same training process on the CIFAR-10 dataset.