 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeMultipod Convolutional Network
Paper and Code
Oct 03, 2022


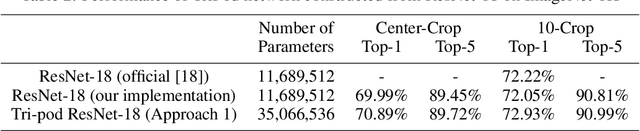
In this paper, we introduce a convolutional network which we call MultiPodNet consisting of a combination of two or more convolutional networks which process the input image in parallel to achieve the same goal. Output feature maps of parallel convolutional networks are fused at the fully connected layer of the network. We experimentally observed that three parallel pod networks (TripodNet) produce the best results in commonly used object recognition datasets. Baseline pod networks can be of any type. In this paper, we use ResNets as baseline networks and their inputs are augmented image patches. The number of parameters of the TripodNet is about three times that of a single ResNet. We train the TripodNet using the standard backpropagation type algorithms. In each individual ResNet, parameters are initialized with different random numbers during training. The TripodNet achieved state-of-the-art performance on CIFAR-10 and ImageNet datasets. For example, it improved the accuracy of a single ResNet from 91.66% to 92.47% under the same training process on the CIFAR-10 dataset.