 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeSWE-Master: Unleashing the Potential of Software Engineering Agents via Post-Training
Feb 03, 2026In this technical report, we present SWE-Master, an open-source and fully reproducible post-training framework for building effective software engineering agents. SWE-Master systematically explores the complete agent development pipeline, including teacher-trajectory synthesis and data curation, long-horizon SFT, RL with real execution feedback, and inference framework design. Starting from an open-source base model with limited initial SWE capability, SWE-Master demonstrates how systematical optimization method can elicit strong long-horizon SWE task solving abilities. We evaluate SWE-Master on SWE-bench Verified, a standard benchmark for realistic software engineering tasks. Under identical experimental settings, our approach achieves a resolve rate of 61.4\% with Qwen2.5-Coder-32B, substantially outperforming existing open-source baselines. By further incorporating test-time scaling~(TTS) with LLM-based environment feedback, SWE-Master reaches 70.8\% at TTS@8, demonstrating a strong performance potential. SWE-Master provides a practical and transparent foundation for advancing reproducible research on software engineering agents. The code is available at https://github.com/RUCAIBox/SWE-Master.
SWE-World: Building Software Engineering Agents in Docker-Free Environments
Feb 03, 2026Recent advances in large language models (LLMs) have enabled software engineering agents to tackle complex code modification tasks. Most existing approaches rely on execution feedback from containerized environments, which require dependency-complete setup and physical execution of programs and tests. While effective, this paradigm is resource-intensive and difficult to maintain, substantially complicating agent training and limiting scalability. We propose SWE-World, a Docker-free framework that replaces physical execution environments with a learned surrogate for training and evaluating software engineering agents. SWE-World leverages LLM-based models trained on real agent-environment interaction data to predict intermediate execution outcomes and final test feedback, enabling agents to learn without interacting with physical containerized environments. This design preserves the standard agent-environment interaction loop while eliminating the need for costly environment construction and maintenance during agent optimization and evaluation. Furthermore, because SWE-World can simulate the final evaluation outcomes of candidate trajectories without real submission, it enables selecting the best solution among multiple test-time attempts, thereby facilitating effective test-time scaling (TTS) in software engineering tasks. Experiments on SWE-bench Verified demonstrate that SWE-World raises Qwen2.5-Coder-32B from 6.2\% to 52.0\% via Docker-free SFT, 55.0\% with Docker-free RL, and 68.2\% with further TTS. The code is available at https://github.com/RUCAIBox/SWE-World
Modeling Dual Period-Varying Preferences for Takeaway Recommendation
Jun 16, 2023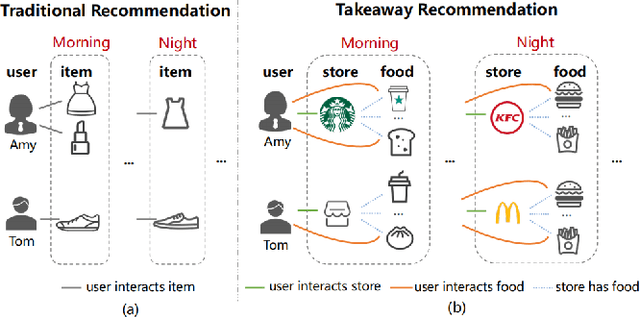

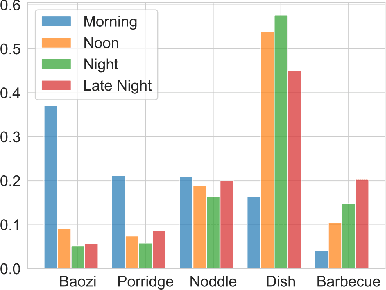

Takeaway recommender systems, which aim to accurately provide stores that offer foods meeting users' interests, have served billions of users in our daily life. Different from traditional recommendation, takeaway recommendation faces two main challenges: (1) Dual Interaction-Aware Preference Modeling. Traditional recommendation commonly focuses on users' single preferences for items while takeaway recommendation needs to comprehensively consider users' dual preferences for stores and foods. (2) Period-Varying Preference Modeling. Conventional recommendation generally models continuous changes in users' preferences from a session-level or day-level perspective. However, in practical takeaway systems, users' preferences vary significantly during the morning, noon, night, and late night periods of the day. To address these challenges, we propose a Dual Period-Varying Preference modeling (DPVP) for takeaway recommendation. Specifically, we design a dual interaction-aware module, aiming to capture users' dual preferences based on their interactions with stores and foods. Moreover, to model various preferences in different time periods of the day, we propose a time-based decomposition module as well as a time-aware gating mechanism. Extensive offline and online experiments demonstrate that our model outperforms state-of-the-art methods on real-world datasets and it is capable of modeling the dual period-varying preferences. Moreover, our model has been deployed online on Meituan Takeaway platform, leading to an average improvement in GMV (Gross Merchandise Value) of 0.70%.