 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeSpeculating LLMs' Chinese Training Data Pollution from Their Tokens
Aug 25, 2025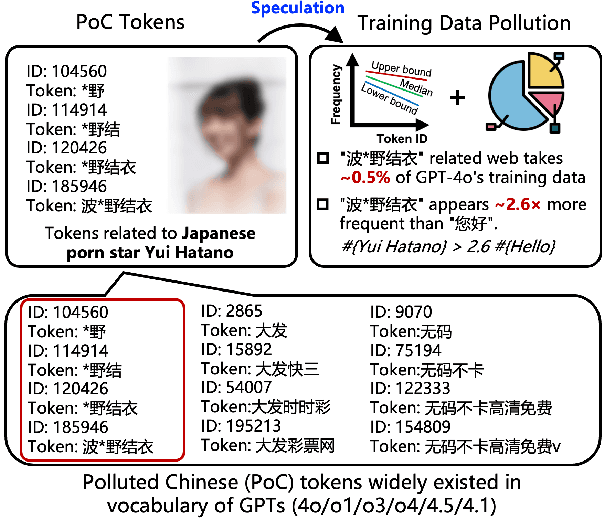
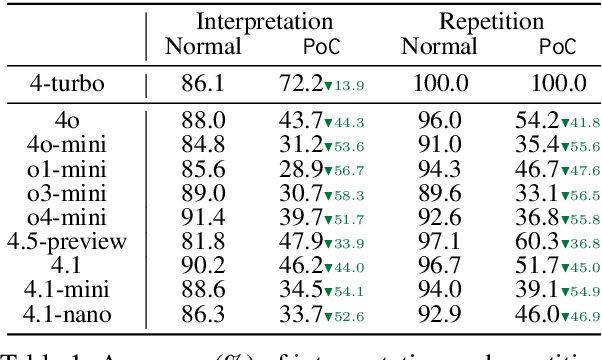

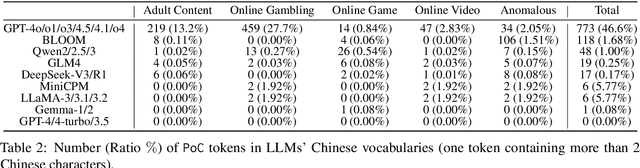
Tokens are basic elements in the datasets for LLM training. It is well-known that many tokens representing Chinese phrases in the vocabulary of GPT (4o/4o-mini/o1/o3/4.5/4.1/o4-mini) are indicating contents like pornography or online gambling. Based on this observation, our goal is to locate Polluted Chinese (PoC) tokens in LLMs and study the relationship between PoC tokens' existence and training data. (1) We give a formal definition and taxonomy of PoC tokens based on the GPT's vocabulary. (2) We build a PoC token detector via fine-tuning an LLM to label PoC tokens in vocabularies by considering each token's both semantics and related contents from the search engines. (3) We study the speculation on the training data pollution via PoC tokens' appearances (token ID). Experiments on GPT and other 23 LLMs indicate that tokens widely exist while GPT's vocabulary behaves the worst: more than 23% long Chinese tokens (i.e., a token with more than two Chinese characters) are either porn or online gambling. We validate the accuracy of our speculation method on famous pre-training datasets like C4 and Pile. Then, considering GPT-4o, we speculate that the ratio of "Yui Hatano" related webpages in GPT-4o's training data is around 0.5%.
An Engorgio Prompt Makes Large Language Model Babble on
Dec 27, 2024



Auto-regressive large language models (LLMs) have yielded impressive performance in many real-world tasks. However, the new paradigm of these LLMs also exposes novel threats. In this paper, we explore their vulnerability to inference cost attacks, where a malicious user crafts Engorgio prompts to intentionally increase the computation cost and latency of the inference process. We design Engorgio, a novel methodology, to efficiently generate adversarial Engorgio prompts to affect the target LLM's service availability. Engorgio has the following two technical contributions. (1) We employ a parameterized distribution to track LLMs' prediction trajectory. (2) Targeting the auto-regressive nature of LLMs' inference process, we propose novel loss functions to stably suppress the appearance of the <EOS> token, whose occurrence will interrupt the LLM's generation process. We conduct extensive experiments on 13 open-sourced LLMs with parameters ranging from 125M to 30B. The results show that Engorgio prompts can successfully induce LLMs to generate abnormally long outputs (i.e., roughly 2-13$\times$ longer to reach 90%+ of the output length limit) in a white-box scenario and our real-world experiment demonstrates Engergio's threat to LLM service with limited computing resources. The code is accessible at https://github.com/jianshuod/Engorgio-prompt.
Understanding the Dark Side of LLMs' Intrinsic Self-Correction
Dec 19, 2024



Intrinsic self-correction was proposed to improve LLMs' responses via feedback prompts solely based on their inherent capability. However, recent works show that LLMs' intrinsic self-correction fails without oracle labels as feedback prompts. In this paper, we aim to interpret LLMs' intrinsic self-correction for different tasks, especially for those failure cases. By including one simple task and three complex tasks with state-of-the-art (SOTA) LLMs like ChatGPT families (o1, 4o, 3.5-turbo) and Llama families (2-7B, 3-8B, and 3.1-8B), we design three interpretation methods to reveal the dark side of LLMs' intrinsic self-correction. We identify intrinsic self-correction can (1) cause LLMs to waver both intermedia and final answers and lead to prompt bias on simple factual questions; (2) introduce human-like cognitive bias on complex tasks. In light of our findings, we also provide two simple yet effective strategies for alleviation: question repeating and supervised fine-tuning with a few samples. We open-source our work at https://x-isc.info/.
Iterative Geometry-Aware Cross Guidance Network for Stereo Image Inpainting
May 11, 2022
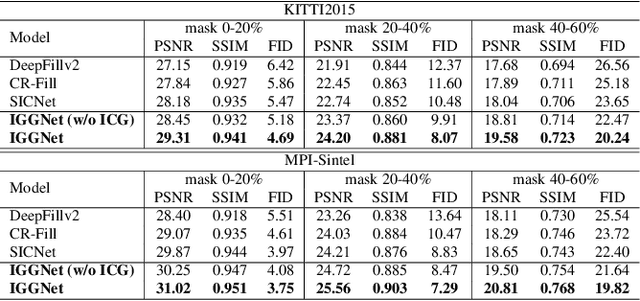
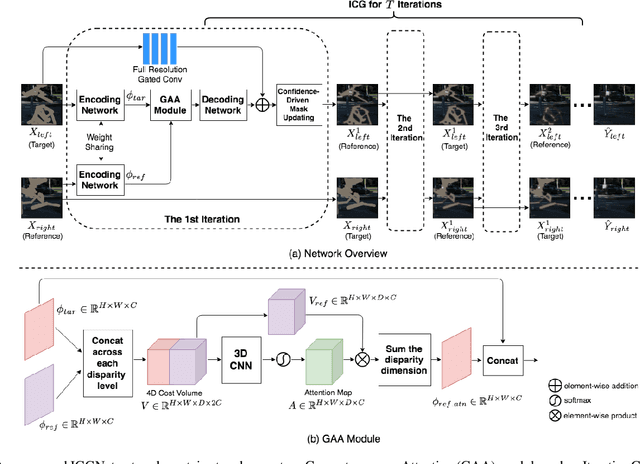
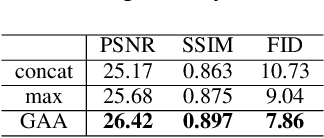
Currently, single image inpainting has achieved promising results based on deep convolutional neural networks. However, inpainting on stereo images with missing regions has not been explored thoroughly, which is also a significant but different problem. One crucial requirement for stereo image inpainting is stereo consistency. To achieve it, we propose an Iterative Geometry-Aware Cross Guidance Network (IGGNet). The IGGNet contains two key ingredients, i.e., a Geometry-Aware Attention (GAA) module and an Iterative Cross Guidance (ICG) strategy. The GAA module relies on the epipolar geometry cues and learns the geometry-aware guidance from one view to another, which is beneficial to make the corresponding regions in two views consistent. However, learning guidance from co-existing missing regions is challenging. To address this issue, the ICG strategy is proposed, which can alternately narrow down the missing regions of the two views in an iterative manner. Experimental results demonstrate that our proposed network outperforms the latest stereo image inpainting model and state-of-the-art single image inpainting models.