 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeGAN-SLAM: Real-Time GAN Aided Floor Plan Creation Through SLAM
Apr 28, 2025



SLAM is a fundamental component of modern autonomous systems, providing robots and their operators with a deeper understanding of their environment. SLAM systems often encounter challenges due to the dynamic nature of robotic motion, leading to inaccuracies in mapping quality, particularly in 2D representations such as Occupancy Grid Maps. These errors can significantly degrade map quality, hindering the effectiveness of specific downstream tasks such as floor plan creation. To address this challenge, we introduce our novel 'GAN-SLAM', a new SLAM approach that leverages Generative Adversarial Networks to clean and complete occupancy grids during the SLAM process, reducing the impact of noise and inaccuracies introduced on the output map. We adapt and integrate accurate pose estimation techniques typically used for 3D SLAM into a 2D form. This enables the quality improvement 3D LiDAR-odometry has seen in recent years to be effective for 2D representations. Our results demonstrate substantial improvements in map fidelity and quality, with minimal noise and errors, affirming the effectiveness of GAN-SLAM for real-world mapping applications within large-scale complex environments. We validate our approach on real-world data operating in real-time, and on famous examples of 2D maps. The improved quality of the output map enables new downstream tasks, such as floor plan drafting, further enhancing the capabilities of autonomous systems. Our novel approach to SLAM offers a significant step forward in the field, improving the usability for SLAM in mapping-based tasks, and offers insight into the usage of GANs for OGM error correction.
Transformation & Translation Occupancy Grid Mapping: 2-Dimensional Deep Learning Refined SLAM
Apr 28, 2025



SLAM (Simultaneous Localisation and Mapping) is a crucial component for robotic systems, providing a map of an environment, the current location and previous trajectory of a robot. While 3D LiDAR SLAM has received notable improvements in recent years, 2D SLAM lags behind. Gradual drifts in odometry and pose estimation inaccuracies hinder modern 2D LiDAR-odometry algorithms in large complex environments. Dynamic robotic motion coupled with inherent estimation based SLAM processes introduce noise and errors, degrading map quality. Occupancy Grid Mapping (OGM) produces results that are often noisy and unclear. This is due to the fact that evidence based mapping represents maps according to uncertain observations. This is why OGMs are so popular in exploration or navigation tasks. However, this also limits OGMs' effectiveness for specific mapping based tasks such as floor plan creation in complex scenes. To address this, we propose our novel Transformation and Translation Occupancy Grid Mapping (TT-OGM). We adapt and enable accurate and robust pose estimation techniques from 3D SLAM to the world of 2D and mitigate errors to improve map quality using Generative Adversarial Networks (GANs). We introduce a novel data generation method via deep reinforcement learning (DRL) to build datasets large enough for training a GAN for SLAM error correction. We demonstrate our SLAM in real-time on data collected at Loughborough University. We also prove its generalisability on a variety of large complex environments on a collection of large scale well-known 2D occupancy maps. Our novel approach enables the creation of high quality OGMs in complex scenes, far surpassing the capabilities of current SLAM algorithms in terms of quality, accuracy and reliability.
Do Deep Neural Networks Always Perform Better When Eating More Data?
May 30, 2022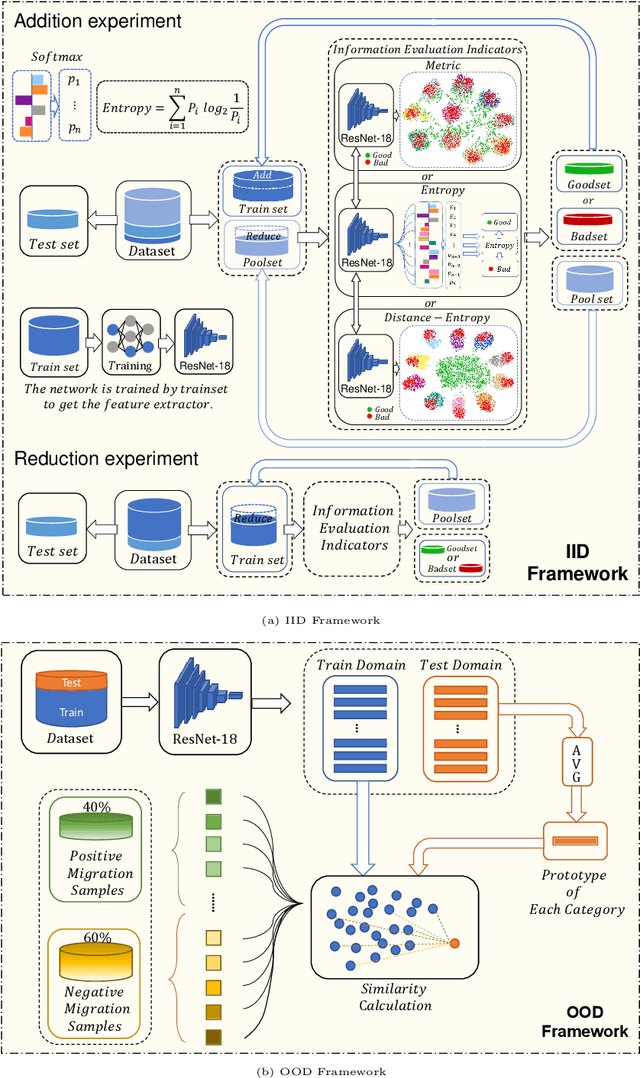
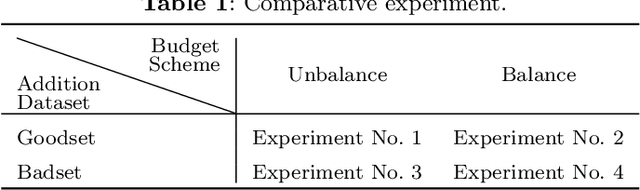
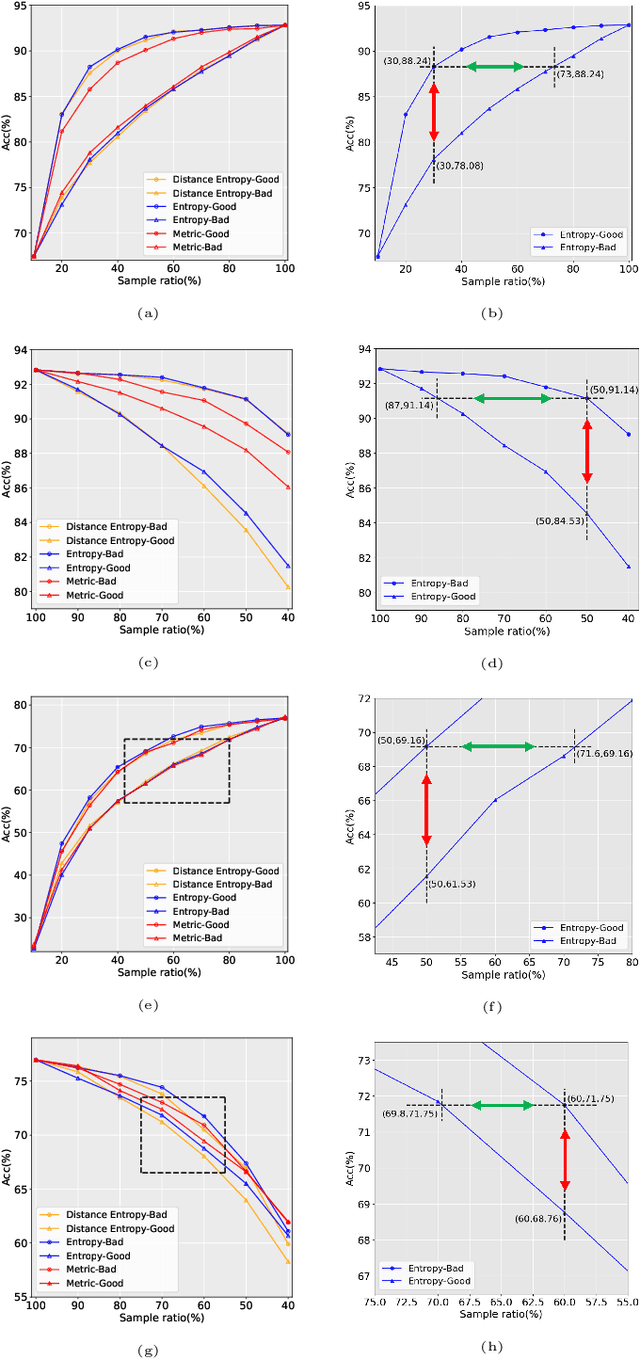
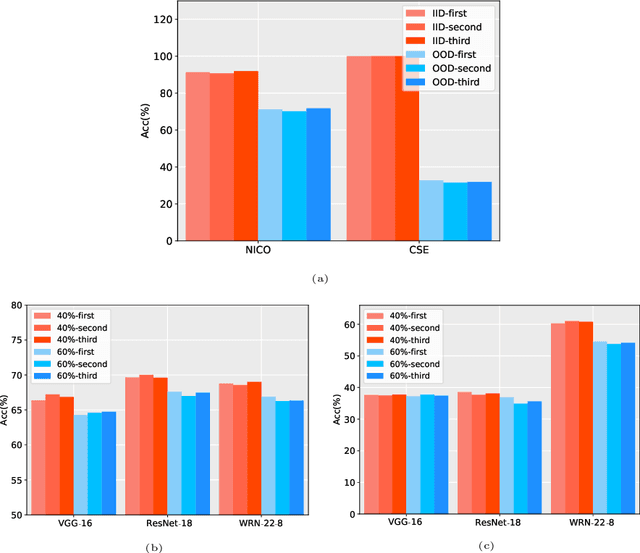
Data has now become a shortcoming of deep learning. Researchers in their own fields share the thinking that "deep neural networks might not always perform better when they eat more data," which still lacks experimental validation and a convincing guiding theory. Here to fill this lack, we design experiments from Identically Independent Distribution(IID) and Out of Distribution(OOD), which give powerful answers. For the purpose of guidance, based on the discussion of results, two theories are proposed: under IID condition, the amount of information determines the effectivity of each sample, the contribution of samples and difference between classes determine the amount of sample information and the amount of class information; under OOD condition, the cross-domain degree of samples determine the contributions, and the bias-fitting caused by irrelevant elements is a significant factor of cross-domain. The above theories provide guidance from the perspective of data, which can promote a wide range of practical applications of artificial intelligence.
Interpreting Deep Knowledge Tracing Model on EdNet Dataset
Oct 31, 2021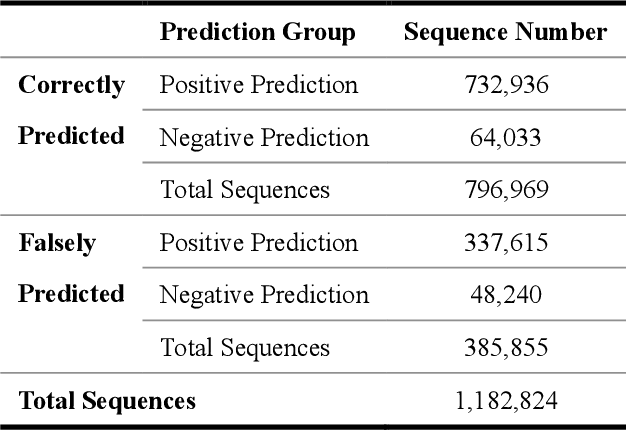
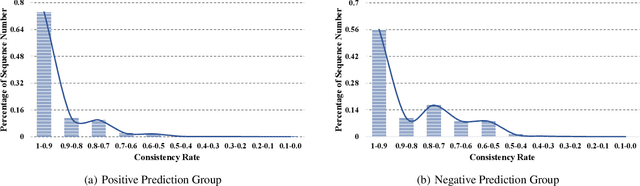
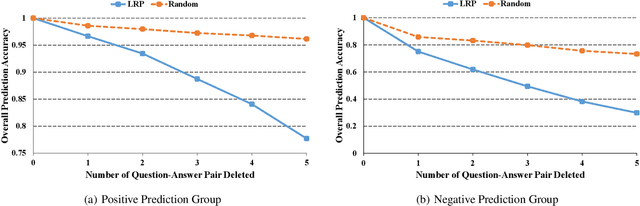
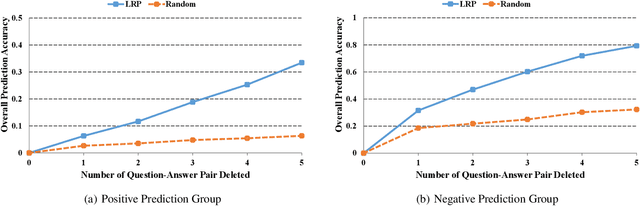
With more deep learning techniques being introduced into the knowledge tracing domain, the interpretability issue of the knowledge tracing models has aroused researchers' attention. Our previous study(Lu et al. 2020) on building and interpreting the KT model mainly adopts the ASSISTment dataset(Feng, Heffernan, and Koedinger 2009),, whose size is relatively small. In this work, we perform the similar tasks but on a large and newly available dataset, called EdNet(Choi et al. 2020). The preliminary experiment results show the effectiveness of the interpreting techniques, while more questions and tasks are worthy to be further explored and accomplished.
The Challenges and Opportunities of Human-Centered AI for Trustworthy Robots and Autonomous Systems
May 07, 2021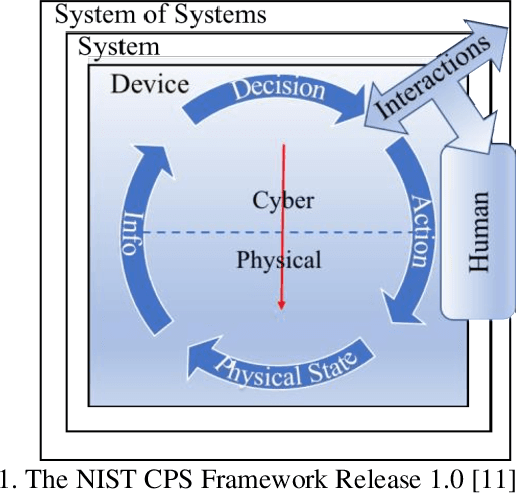
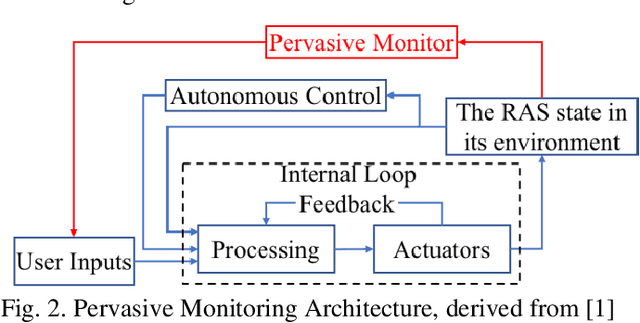

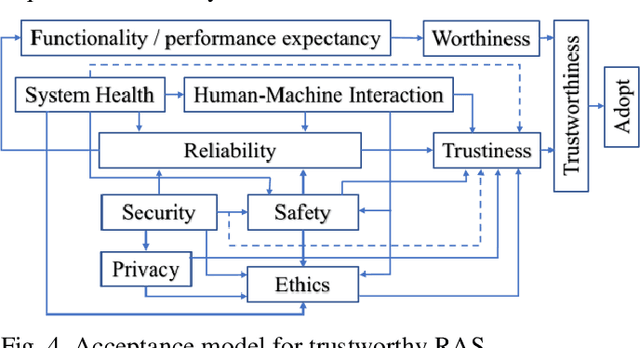
The trustworthiness of Robots and Autonomous Systems (RAS) has gained a prominent position on many research agendas towards fully autonomous systems. This research systematically explores, for the first time, the key facets of human-centered AI (HAI) for trustworthy RAS. In this article, five key properties of a trustworthy RAS initially have been identified. RAS must be (i) safe in any uncertain and dynamic surrounding environments; (ii) secure, thus protecting itself from any cyber-threats; (iii) healthy with fault tolerance; (iv) trusted and easy to use to allow effective human-machine interaction (HMI), and (v) compliant with the law and ethical expectations. Then, the challenges in implementing trustworthy autonomous system are analytically reviewed, in respects of the five key properties, and the roles of AI technologies have been explored to ensure the trustiness of RAS with respects to safety, security, health and HMI, while reflecting the requirements of ethics in the design of RAS. While applications of RAS have mainly focused on performance and productivity, the risks posed by advanced AI in RAS have not received sufficient scientific attention. Hence, a new acceptance model of RAS is provided, as a framework for requirements to human-centered AI and for implementing trustworthy RAS by design. This approach promotes human-level intelligence to augment human's capacity. while focusing on contributions to humanity.
Towards Interpretable Deep Learning Models for Knowledge Tracing
May 13, 2020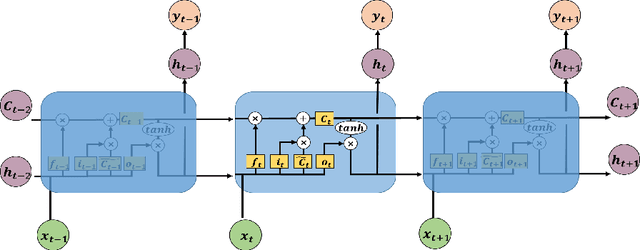

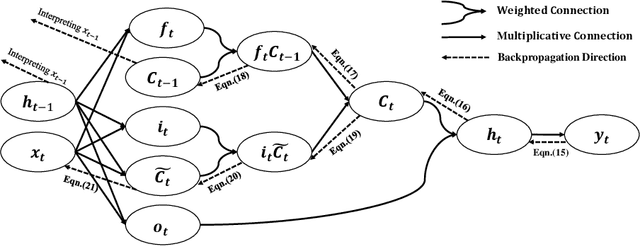
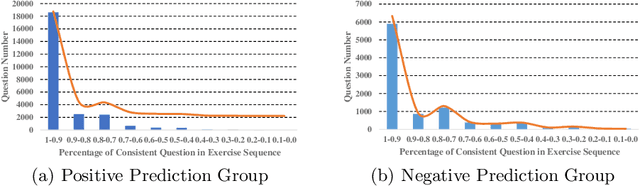
As an important technique for modeling the knowledge states of learners, the traditional knowledge tracing (KT) models have been widely used to support intelligent tutoring systems and MOOC platforms. Driven by the fast advancements of deep learning techniques, deep neural network has been recently adopted to design new KT models for achieving better prediction performance. However, the lack of interpretability of these models has painfully impeded their practical applications, as their outputs and working mechanisms suffer from the intransparent decision process and complex inner structures. We thus propose to adopt the post-hoc method to tackle the interpretability issue for deep learning based knowledge tracing (DLKT) models. Specifically, we focus on applying the layer-wise relevance propagation (LRP) method to interpret RNN-based DLKT model by backpropagating the relevance from the model's output layer to its input layer. The experiment results show the feasibility using the LRP method for interpreting the DLKT model's predictions, and partially validate the computed relevance scores from both question level and concept level. We believe it can be a solid step towards fully interpreting the DLKT models and promote their practical applications in the education domain.