 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeTRACE: Temporal Rule-Anchored Chain-of-Evidence on Knowledge Graphs for Interpretable Stock Movement Prediction
Mar 12, 2026We present a Temporal Rule-Anchored Chain-of-Evidence (TRACE) on knowledge graphs for interpretable stock movement prediction that unifies symbolic relational priors, dynamic graph exploration, and LLM-guided decision making in a single end-to-end pipeline. The approach performs rule-guided multi-hop exploration restricted to admissible relation sequences, grounds candidate reasoning chains in contemporaneous news, and aggregates fully grounded evidence into auditable \texttt{UP}/\texttt{DOWN} verdicts with human-readable paths connecting text and structure. On an S\&P~500 benchmark, the method achieves 55.1\% accuracy, 55.7\% precision, 71.5\% recall, and 60.8\% F1, surpassing strong baselines and improving recall and F1 over the best graph baseline under identical evaluation. The gains stem from (i) rule-guided exploration that focuses search on economically meaningful motifs rather than arbitrary walks, and (ii) text-grounded consolidation that selectively aggregates high-confidence, fully grounded hypotheses instead of uniformly pooling weak signals. Together, these choices yield higher sensitivity without sacrificing selectivity, delivering predictive lift with faithful, auditably interpretable explanations.
Towards Agentic Intelligence for Materials Science
Jan 29, 2026The convergence of artificial intelligence and materials science presents a transformative opportunity, but achieving true acceleration in discovery requires moving beyond task-isolated, fine-tuned models toward agentic systems that plan, act, and learn across the full discovery loop. This survey advances a unique pipeline-centric view that spans from corpus curation and pretraining, through domain adaptation and instruction tuning, to goal-conditioned agents interfacing with simulation and experimental platforms. Unlike prior reviews, we treat the entire process as an end-to-end system to be optimized for tangible discovery outcomes rather than proxy benchmarks. This perspective allows us to trace how upstream design choices-such as data curation and training objectives-can be aligned with downstream experimental success through effective credit assignment. To bridge communities and establish a shared frame of reference, we first present an integrated lens that aligns terminology, evaluation, and workflow stages across AI and materials science. We then analyze the field through two focused lenses: From the AI perspective, the survey details LLM strengths in pattern recognition, predictive analytics, and natural language processing for literature mining, materials characterization, and property prediction; from the materials science perspective, it highlights applications in materials design, process optimization, and the acceleration of computational workflows via integration with external tools (e.g., DFT, robotic labs). Finally, we contrast passive, reactive approaches with agentic design, cataloging current contributions while motivating systems that pursue long-horizon goals with autonomy, memory, and tool use. This survey charts a practical roadmap towards autonomous, safety-aware LLM agents aimed at discovering novel and useful materials.
MatExpert: Decomposing Materials Discovery by Mimicking Human Experts
Oct 26, 2024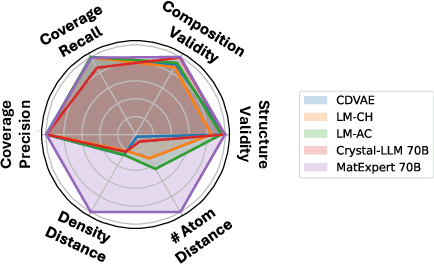
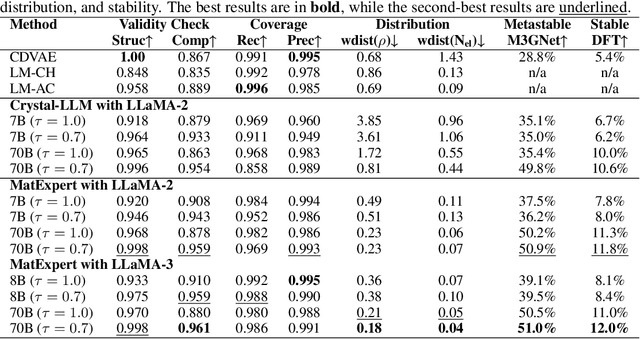

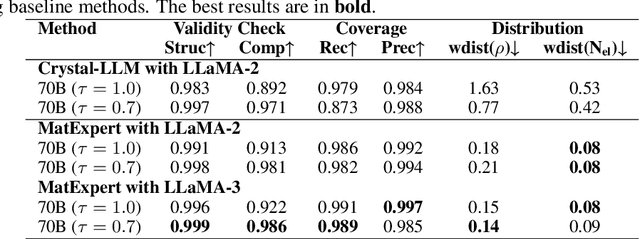
Material discovery is a critical research area with profound implications for various industries. In this work, we introduce MatExpert, a novel framework that leverages Large Language Models (LLMs) and contrastive learning to accelerate the discovery and design of new solid-state materials. Inspired by the workflow of human materials design experts, our approach integrates three key stages: retrieval, transition, and generation. First, in the retrieval stage, MatExpert identifies an existing material that closely matches the desired criteria. Second, in the transition stage, MatExpert outlines the necessary modifications to transform this material formulation to meet specific requirements outlined by the initial user query. Third, in the generation state, MatExpert performs detailed computations and structural generation to create new materials based on the provided information. Our experimental results demonstrate that MatExpert outperforms state-of-the-art methods in material generation tasks, achieving superior performance across various metrics including validity, distribution, and stability. As such, MatExpert represents a meaningful advancement in computational material discovery using langauge-based generative models.
GPN: A Joint Structural Learning Framework for Graph Neural Networks
May 12, 2022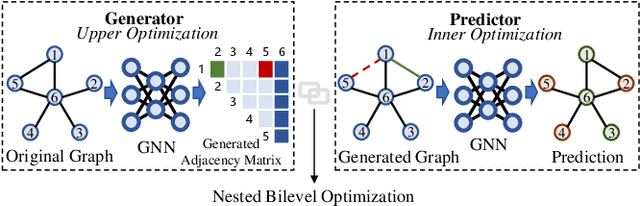
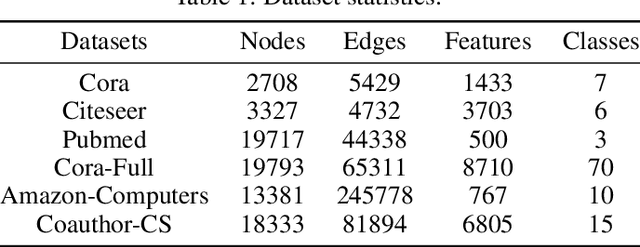
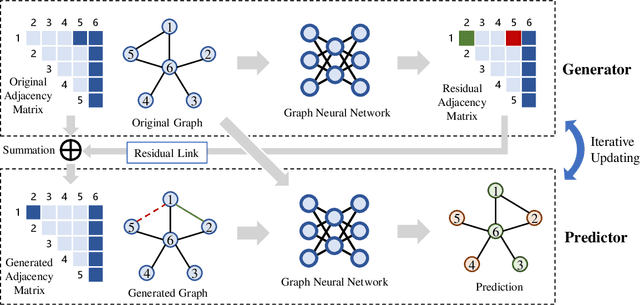
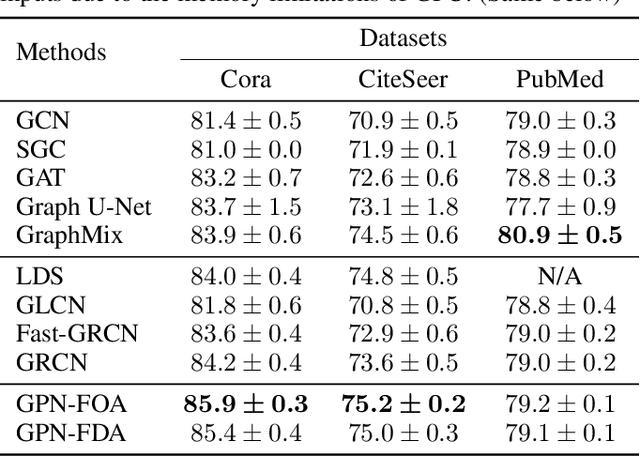
Graph neural networks (GNNs) have been applied into a variety of graph tasks. Most existing work of GNNs is based on the assumption that the given graph data is optimal, while it is inevitable that there exists missing or incomplete edges in the graph data for training, leading to degraded performance. In this paper, we propose Generative Predictive Network (GPN), a GNN-based joint learning framework that simultaneously learns the graph structure and the downstream task. Specifically, we develop a bilevel optimization framework for this joint learning task, in which the upper optimization (generator) and the lower optimization (predictor) are both instantiated with GNNs. To the best of our knowledge, our method is the first GNN-based bilevel optimization framework for resolving this task. Through extensive experiments, our method outperforms a wide range of baselines using benchmark datasets.
RetroXpert: Decompose Retrosynthesis Prediction like a Chemist
Nov 04, 2020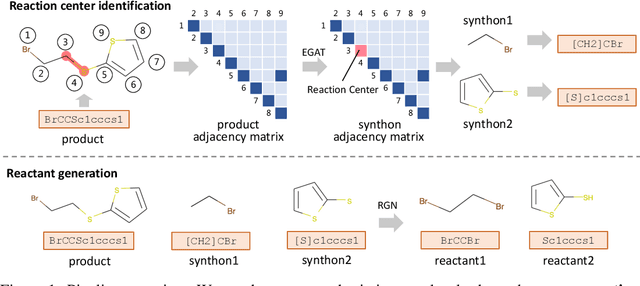
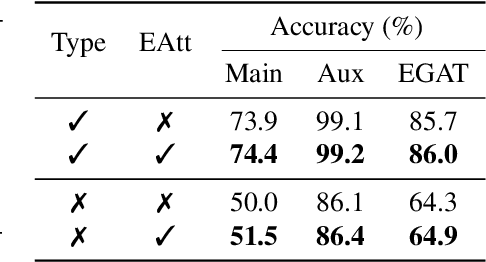
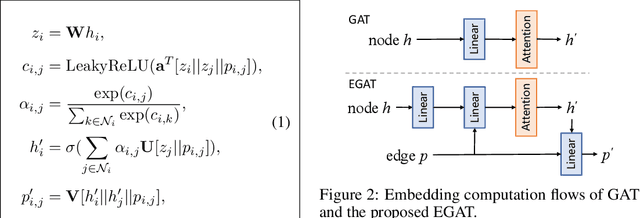
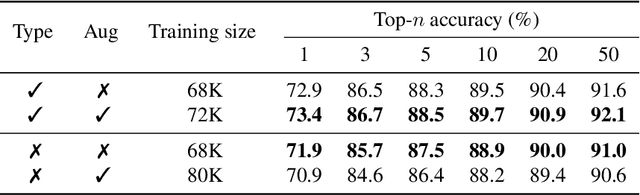
Retrosynthesis is the process of recursively decomposing target molecules into available building blocks. It plays an important role in solving problems in organic synthesis planning. To automate or assist in the retrosynthesis analysis, various retrosynthesis prediction algorithms have been proposed. However, most of them are cumbersome and lack interpretability about their predictions. In this paper, we devise a novel template-free algorithm for automatic retrosynthetic expansion inspired by how chemists approach retrosynthesis prediction. Our method disassembles retrosynthesis into two steps: i) identify the potential reaction center of the target molecule through a novel graph neural network and generate intermediate synthons, and ii) generate the reactants associated with synthons via a robust reactant generation model. While outperforming the state-of-the-art baselines by a significant margin, our model also provides chemically reasonable interpretation.
Adaptive Regularization of Labels
Aug 15, 2019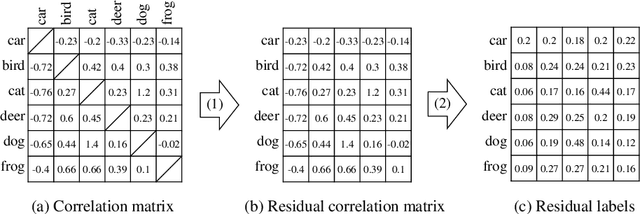
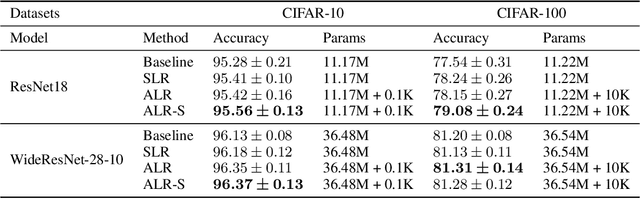
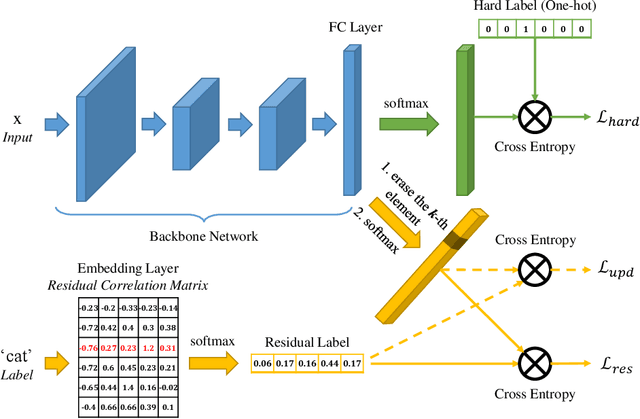
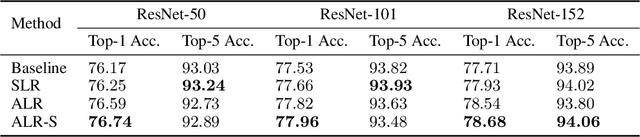
Recently, a variety of regularization techniques have been widely applied in deep neural networks, such as dropout, batch normalization, data augmentation, and so on. These methods mainly focus on the regularization of weight parameters to prevent overfitting effectively. In addition, label regularization techniques such as label smoothing and label disturbance have also been proposed with the motivation of adding a stochastic perturbation to labels. In this paper, we propose a novel adaptive label regularization method, which enables the neural network to learn from the erroneous experience and update the optimal label representation online. On the other hand, compared with knowledge distillation, which learns the correlation of categories using teacher network, our proposed method requires only a minuscule increase in parameters without cumbersome teacher network. Furthermore, we evaluate our method on CIFAR-10/CIFAR-100/ImageNet datasets for image recognition tasks and AGNews/Yahoo/Yelp-Full datasets for text classification tasks. The empirical results show significant improvement under all experimental settings.