 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeContinual Deep Learning by Functional Regularisation of Memorable Past
Apr 29, 2020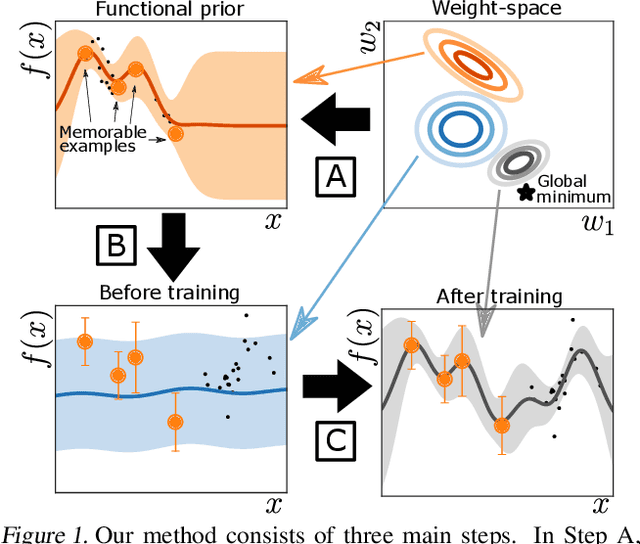

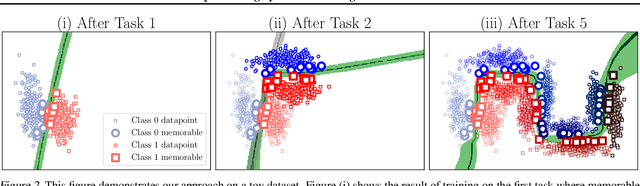

Continually learning new skills is important for intelligent systems, yet most deep learning methods suffer from catastrophic forgetting of the past. Recent works address this with weight regularisation. Functional regularisation, although computationally expensive, is expected to perform better, but rarely does so in practice. In this paper, we fix this issue by proposing a new functional-regularisation approach that utilises a few memorable past examples that are crucial to avoid forgetting. By using a Gaussian Process formulation of deep networks, our approach enables training in weight-space while identifying both the memorable past and a functional prior. Our method achieves state-of-the-art performance on standard benchmarks and opens a new direction for life-long learning where regularisation and memory-based methods are naturally combined.
DM-GAN: Dynamic Memory Generative Adversarial Networks for Text-to-Image Synthesis
Apr 02, 2019

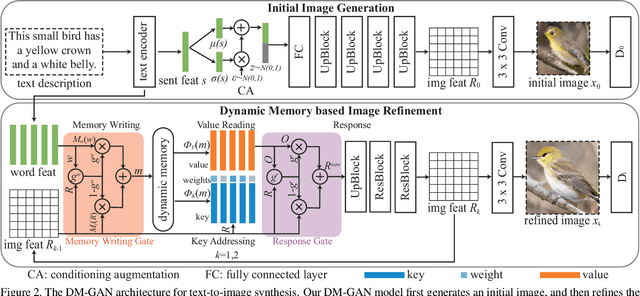
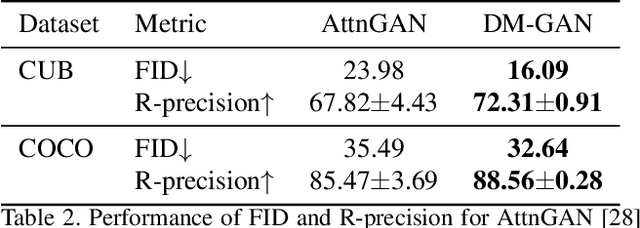
In this paper, we focus on generating realistic images from text descriptions. Current methods first generate an initial image with rough shape and color, and then refine the initial image to a high-resolution one. Most existing text-to-image synthesis methods have two main problems. (1) These methods depend heavily on the quality of the initial images. If the initial image is not well initialized, the following processes can hardly refine the image to a satisfactory quality. (2) Each word contributes a different level of importance when depicting different image contents, however, unchanged text representation is used in existing image refinement processes. In this paper, we propose the Dynamic Memory Generative Adversarial Network (DM-GAN) to generate high-quality images. The proposed method introduces a dynamic memory module to refine fuzzy image contents, when the initial images are not well generated. A memory writing gate is designed to select the important text information based on the initial image content, which enables our method to accurately generate images from the text description. We also utilize a response gate to adaptively fuse the information read from the memories and the image features. We evaluate the DM-GAN model on the Caltech-UCSD Birds 200 dataset and the Microsoft Common Objects in Context dataset. Experimental results demonstrate that our DM-GAN model performs favorably against the state-of-the-art approaches.
Learning Discriminators as Energy Networks in Adversarial Learning
Oct 02, 2018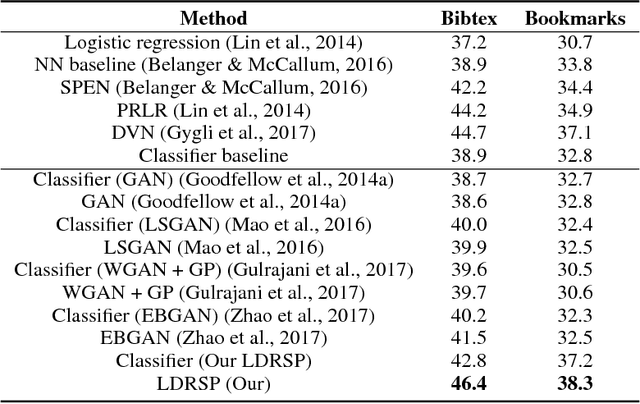


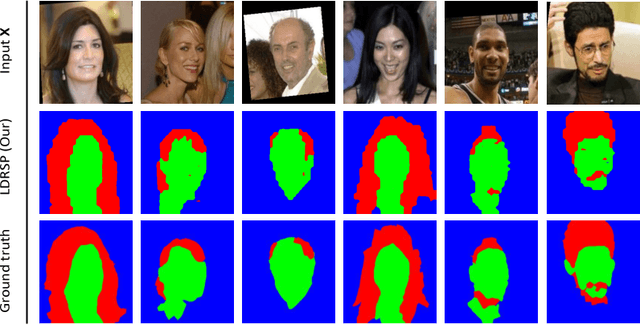
We propose a novel framework for structured prediction via adversarial learning. Existing adversarial learning methods involve two separate networks, i.e., the structured prediction models and the discriminative models, in the training. The information captured by discriminative models complements that in the structured prediction models, but few existing researches have studied on utilizing such information to improve structured prediction models at the inference stage. In this work, we propose to refine the predictions of structured prediction models by effectively integrating discriminative models into the prediction. Discriminative models are treated as energy-based models. Similar to the adversarial learning, discriminative models are trained to estimate scores which measure the quality of predicted outputs, while structured prediction models are trained to predict contrastive outputs with maximal energy scores. In this way, the gradient vanishing problem is ameliorated, and thus we are able to perform inference by following the ascent gradient directions of discriminative models to refine structured prediction models. The proposed method is able to handle a range of tasks, e.g., multi-label classification and image segmentation. Empirical results on these two tasks validate the effectiveness of our learning method.
Hierarchical Recurrent Neural Encoder for Video Representation with Application to Captioning
Nov 11, 2015
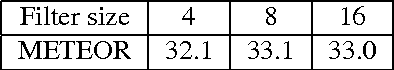

Recently, deep learning approach, especially deep Convolutional Neural Networks (ConvNets), have achieved overwhelming accuracy with fast processing speed for image classification. Incorporating temporal structure with deep ConvNets for video representation becomes a fundamental problem for video content analysis. In this paper, we propose a new approach, namely Hierarchical Recurrent Neural Encoder (HRNE), to exploit temporal information of videos. Compared to recent video representation inference approaches, this paper makes the following three contributions. First, our HRNE is able to efficiently exploit video temporal structure in a longer range by reducing the length of input information flow, and compositing multiple consecutive inputs at a higher level. Second, computation operations are significantly lessened while attaining more non-linearity. Third, HRNE is able to uncover temporal transitions between frame chunks with different granularities, i.e., it can model the temporal transitions between frames as well as the transitions between segments. We apply the new method to video captioning where temporal information plays a crucial role. Experiments demonstrate that our method outperforms the state-of-the-art on video captioning benchmarks. Notably, even using a single network with only RGB stream as input, HRNE beats all the recent systems which combine multiple inputs, such as RGB ConvNet plus 3D ConvNet.