 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeA deformation-based framework for learning solution mappings of PDEs defined on varying domains
Dec 02, 2024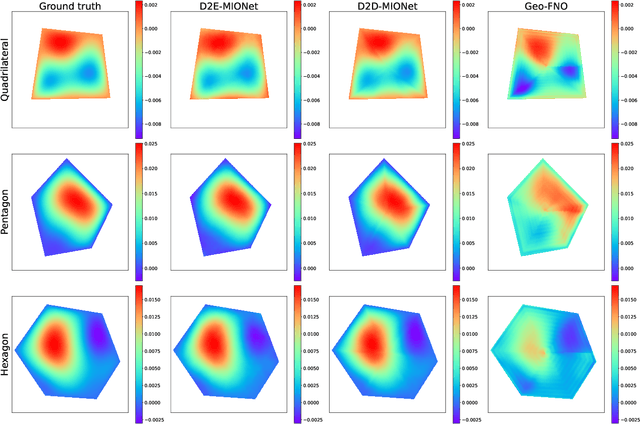

In this work, we establish a deformation-based framework for learning solution mappings of PDEs defined on varying domains. The union of functions defined on varying domains can be identified as a metric space according to the deformation, then the solution mapping is regarded as a continuous metric-to-metric mapping, and subsequently can be represented by another continuous metric-to-Banach mapping using two different strategies, referred to as the D2D framework and the D2E framework, respectively. We point out that such a metric-to-Banach mapping can be learned by neural networks, hence the solution mapping is accordingly learned. With this framework, a rigorous convergence analysis is built for the problem of learning solution mappings of PDEs on varying domains. As the theoretical framework holds based on several pivotal assumptions which need to be verified for a given specific problem, we study the star domains as a typical example, and other situations could be similarly verified. There are three important features of this framework: (1) The domains under consideration are not required to be diffeomorphic, therefore a wide range of regions can be covered by one model provided they are homeomorphic. (2) The deformation mapping is unnecessary to be continuous, thus it can be flexibly established via combining a primary identity mapping and a local deformation mapping. This capability facilitates the resolution of large systems where only local parts of the geometry undergo change. (3) If a linearity-preserving neural operator such as MIONet is adopted, this framework still preserves the linearity of the surrogate solution mapping on its source term for linear PDEs, thus it can be applied to the hybrid iterative method. We finally present several numerical experiments to validate our theoretical results.
Shallow ReLU neural networks and finite elements
Mar 09, 2024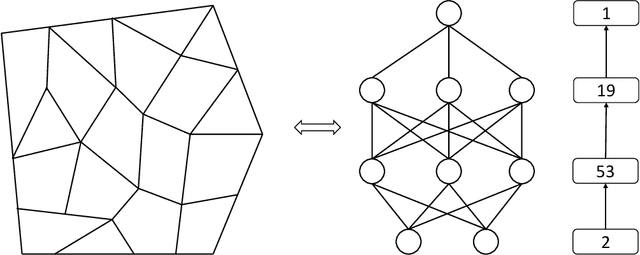


We point out that (continuous or discontinuous) piecewise linear functions on a convex polytope mesh can be represented by two-hidden-layer ReLU neural networks in a weak sense. In addition, the numbers of neurons of the two hidden layers required to weakly represent are accurately given based on the numbers of polytopes and hyperplanes involved in this mesh. The results naturally hold for constant and linear finite element functions. Such weak representation establishes a bridge between shallow ReLU neural networks and finite element functions, and leads to a perspective for analyzing approximation capability of ReLU neural networks in $L^p$ norm via finite element functions. Moreover, we discuss the strict representation for tensor finite element functions via the recent tensor neural networks.
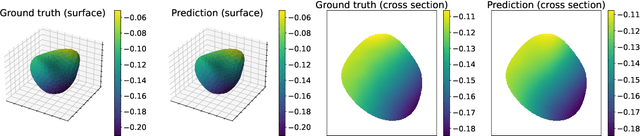
Learning solution operators of PDEs defined on varying domains via MIONet
Feb 23, 2024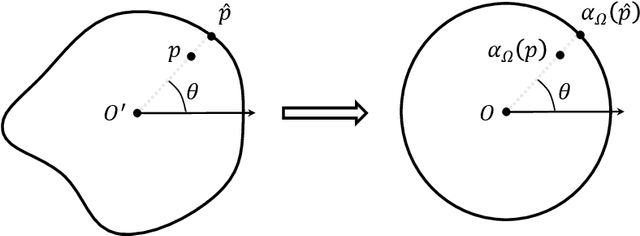

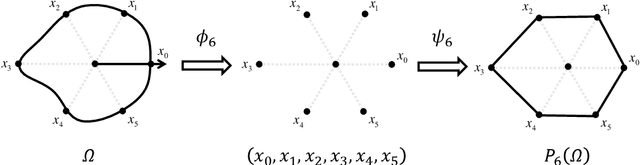
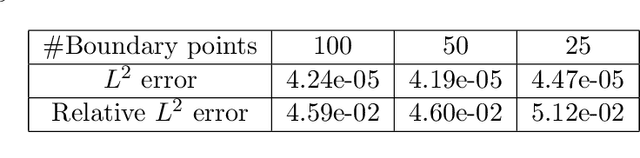
In this work, we propose a method to learn the solution operators of PDEs defined on varying domains via MIONet, and theoretically justify this method. We first extend the approximation theory of MIONet to further deal with metric spaces, establishing that MIONet can approximate mappings with multiple inputs in metric spaces. Subsequently, we construct a set consisting of some appropriate regions and provide a metric on this set thus make it a metric space, which satisfies the approximation condition of MIONet. Building upon the theoretical foundation, we are able to learn the solution mapping of a PDE with all the parameters varying, including the parameters of the differential operator, the right-hand side term, the boundary condition, as well as the domain. Without loss of generality, we for example perform the experiments for 2-d Poisson equations, where the domains and the right-hand side terms are varying. The results provide insights into the performance of this method across convex polygons, polar regions with smooth boundary, and predictions for different levels of discretization on one task. Reasonably, we point out that this is a meshless method, hence can be flexibly used as a general solver for a type of PDE.
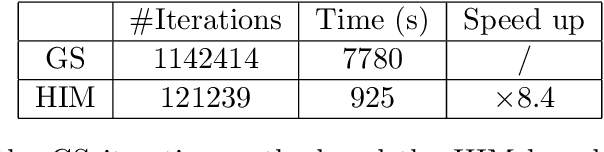
A hybrid iterative method based on MIONet for PDEs: Theory and numerical examples
Feb 11, 2024



We propose a hybrid iterative method based on MIONet for PDEs, which combines the traditional numerical iterative solver and the recent powerful machine learning method of neural operator, and further systematically analyze its theoretical properties, including the convergence condition, the spectral behavior, as well as the convergence rate, in terms of the errors of the discretization and the model inference. We show the theoretical results for the frequently-used smoothers, i.e. Richardson (damped Jacobi) and Gauss-Seidel. We give an upper bound of the convergence rate of the hybrid method w.r.t. the model correction period, which indicates a minimum point to make the hybrid iteration converge fastest. Several numerical examples including the hybrid Richardson (Gauss-Seidel) iteration for the 1-d (2-d) Poisson equation are presented to verify our theoretical results, and also reflect an excellent acceleration effect. As a meshless acceleration method, it is provided with enormous potentials for practice applications.
Experimental observation on a low-rank tensor model for eigenvalue problems
Feb 01, 2023



Here we utilize a low-rank tensor model (LTM) as a function approximator, combined with the gradient descent method, to solve eigenvalue problems including the Laplacian operator and the harmonic oscillator. Experimental results show the superiority of the polynomial-based low-rank tensor model (PLTM) compared to the tensor neural network (TNN). We also test such low-rank architectures for the classification problem on the MNIST dataset.
On Numerical Integration in Neural Ordinary Differential Equations
Jun 15, 2022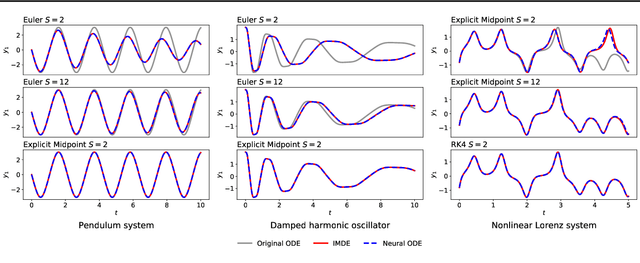
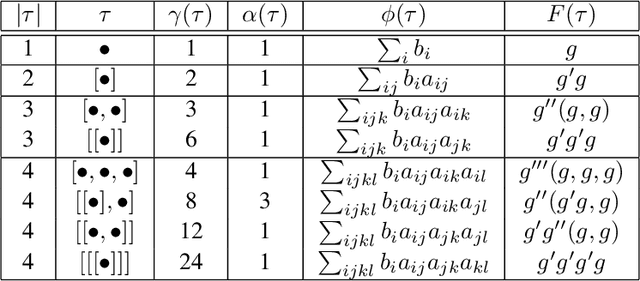
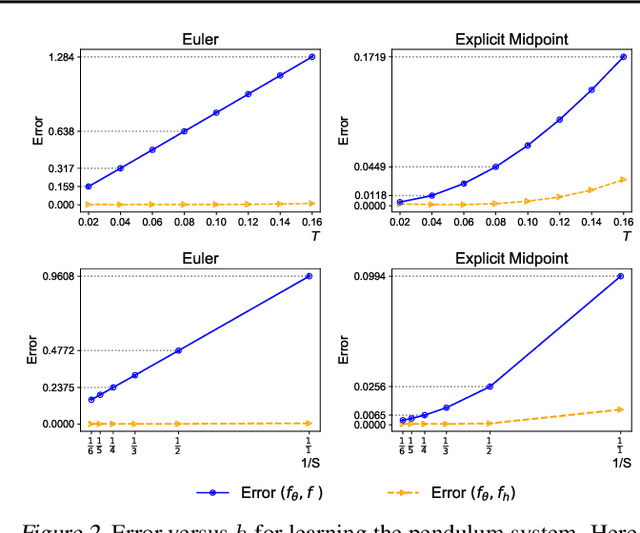
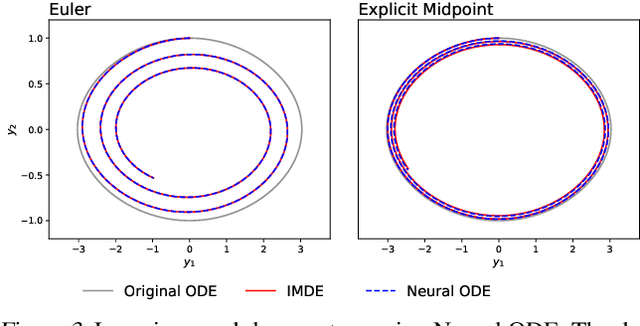
The combination of ordinary differential equations and neural networks, i.e., neural ordinary differential equations (Neural ODE), has been widely studied from various angles. However, deciphering the numerical integration in Neural ODE is still an open challenge, as many researches demonstrated that numerical integration significantly affects the performance of the model. In this paper, we propose the inverse modified differential equations (IMDE) to clarify the influence of numerical integration on training Neural ODE models. IMDE is determined by the learning task and the employed ODE solver. It is shown that training a Neural ODE model actually returns a close approximation of the IMDE, rather than the true ODE. With the help of IMDE, we deduce that (i) the discrepancy between the learned model and the true ODE is bounded by the sum of discretization error and learning loss; (ii) Neural ODE using non-symplectic numerical integration fail to learn conservation laws theoretically. Several experiments are performed to numerically verify our theoretical analysis.
MIONet: Learning multiple-input operators via tensor product
Feb 12, 2022
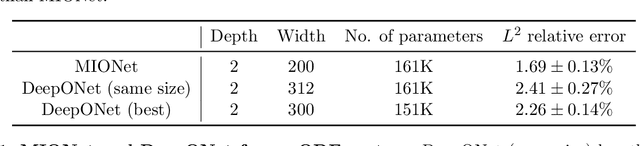


As an emerging paradigm in scientific machine learning, neural operators aim to learn operators, via neural networks, that map between infinite-dimensional function spaces. Several neural operators have been recently developed. However, all the existing neural operators are only designed to learn operators defined on a single Banach space, i.e., the input of the operator is a single function. Here, for the first time, we study the operator regression via neural networks for multiple-input operators defined on the product of Banach spaces. We first prove a universal approximation theorem of continuous multiple-input operators. We also provide detailed theoretical analysis including the approximation error, which provides a guidance of the design of the network architecture. Based on our theory and a low-rank approximation, we propose a novel neural operator, MIONet, to learn multiple-input operators. MIONet consists of several branch nets for encoding the input functions and a trunk net for encoding the domain of the output function. We demonstrate that MIONet can learn solution operators involving systems governed by ordinary and partial differential equations. In our computational examples, we also show that we can endow MIONet with prior knowledge of the underlying system, such as linearity and periodicity, to further improve the accuracy.
Approximation capabilities of measure-preserving neural networks
Jun 21, 2021
Measure-preserving neural networks are well-developed invertible models, however, the approximation capabilities remain unexplored. This paper rigorously establishes the general sufficient conditions for approximating measure-preserving maps using measure-preserving neural networks. It is shown that for compact $U \subset \R^D$ with $D\geq 2$, every measure-preserving map $\psi: U\to \R^D$ which is injective and bounded can be approximated in the $L^p$-norm by measure-preserving neural networks. Specifically, the differentiable maps with $\pm 1$ determinants of Jacobians are measure-preserving, injective and bounded on $U$, thus hold the approximation property.
Learning Poisson systems and trajectories of autonomous systems via Poisson neural networks
Dec 05, 2020
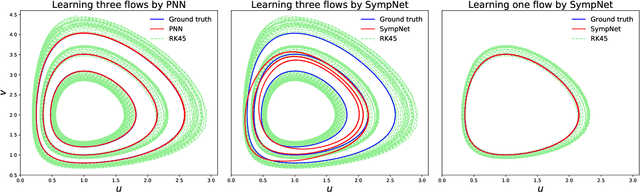
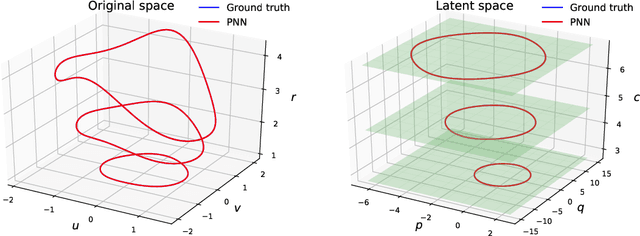

We propose the Poisson neural networks (PNNs) to learn Poisson systems and trajectories of autonomous systems from data. Based on the Darboux-Lie theorem, the phase flow of a Poisson system can be written as the composition of (1) a coordinate transformation, (2) an extended symplectic map and (3) the inverse of the transformation. In this work, we extend this result to the unknotted trajectories of autonomous systems. We employ structured neural networks with physical priors to approximate the three aforementioned maps. We demonstrate through several simulations that PNNs are capable of handling very accurately several challenging tasks, including the motion of a particle in the electromagnetic potential, the nonlinear Schr{\"o}dinger equation, and pixel observations of the two-body problem.
Symplectic networks: Intrinsic structure-preserving networks for identifying Hamiltonian systems
Jan 11, 2020
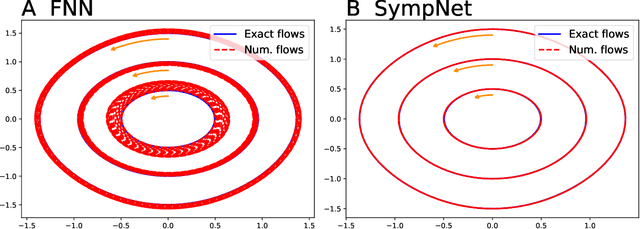

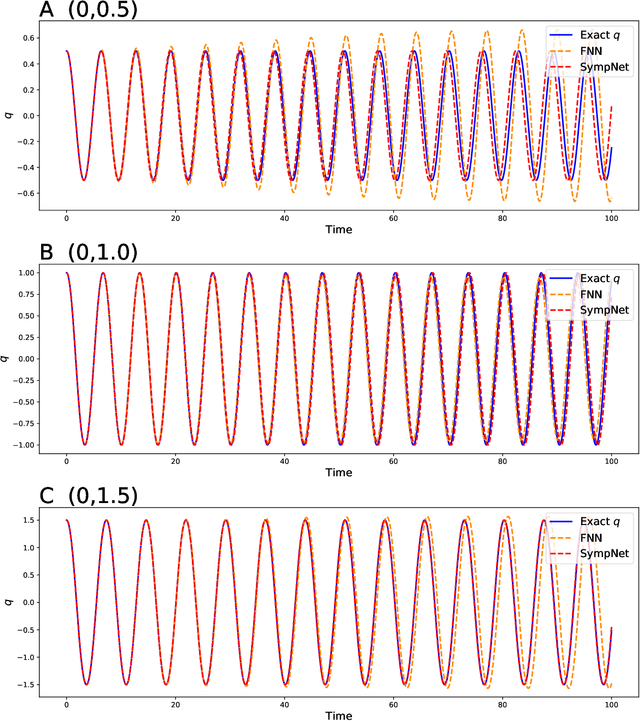
This work presents a framework of constructing the neural networks preserving the symplectic structure, so-called symplectic networks (SympNets). With the symplectic networks, we show some numerical results about (\romannumeral1) solving the Hamiltonian systems by learning abundant data points over the phase space, and (\romannumeral2) predicting the phase flows by learning a series of points depending on time. All the experiments point out that the symplectic networks perform much more better than the fully-connected networks that without any prior information, especially in the task of predicting which is unable to do within the conventional numerical methods.