 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeSingle-DARTS: Towards Stable Architecture Search
Aug 18, 2021
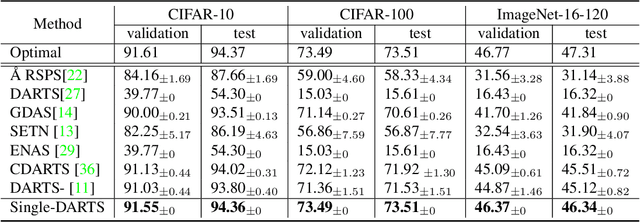


Differentiable architecture search (DARTS) marks a milestone in Neural Architecture Search (NAS), boasting simplicity and small search costs. However, DARTS still suffers from frequent performance collapse, which happens when some operations, such as skip connections, zeroes and poolings, dominate the architecture. In this paper, we are the first to point out that the phenomenon is attributed to bi-level optimization. We propose Single-DARTS which merely uses single-level optimization, updating network weights and architecture parameters simultaneously with the same data batch. Even single-level optimization has been previously attempted, no literature provides a systematic explanation on this essential point. Replacing the bi-level optimization, Single-DARTS obviously alleviates performance collapse as well as enhances the stability of architecture search. Experiment results show that Single-DARTS achieves state-of-the-art performance on mainstream search spaces. For instance, on NAS-Benchmark-201, the searched architectures are nearly optimal ones. We also validate that the single-level optimization framework is much more stable than the bi-level one. We hope that this simple yet effective method will give some insights on differential architecture search. The code is available at https://github.com/PencilAndBike/Single-DARTS.git.
Neural Architecture Search with Random Labels
Jan 28, 2021
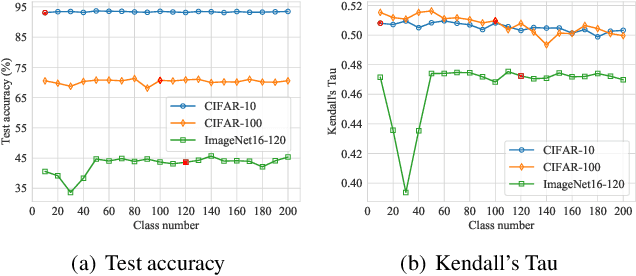
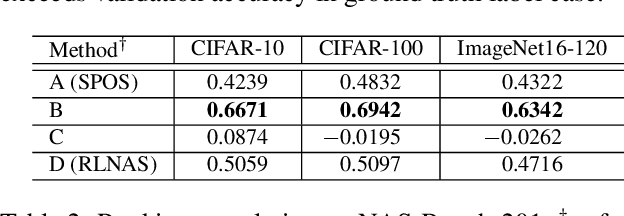

In this paper, we investigate a new variant of neural architecture search (NAS) paradigm -- searching with random labels (RLNAS). The task sounds counter-intuitive for most existing NAS algorithms since random label provides few information on the performance of each candidate architecture. Instead, we propose a novel NAS framework based on ease-of-convergence hypothesis, which requires only random labels during searching. The algorithm involves two steps: first, we train a SuperNet using random labels; second, from the SuperNet we extract the sub-network whose weights change most significantly during the training. Extensive experiments are evaluated on multiple datasets (e.g. NAS-Bench-201 and ImageNet) and multiple search spaces (e.g. DARTS-like and MobileNet-like). Very surprisingly, RLNAS achieves comparable or even better results compared with state-of-the-art NAS methods such as PC-DARTS, Single Path One-Shot, even though the counterparts utilize full ground truth labels for searching. We hope our finding could inspire new understandings on the essential of NAS.
Single-level Optimization For Differential Architecture Search
Dec 15, 2020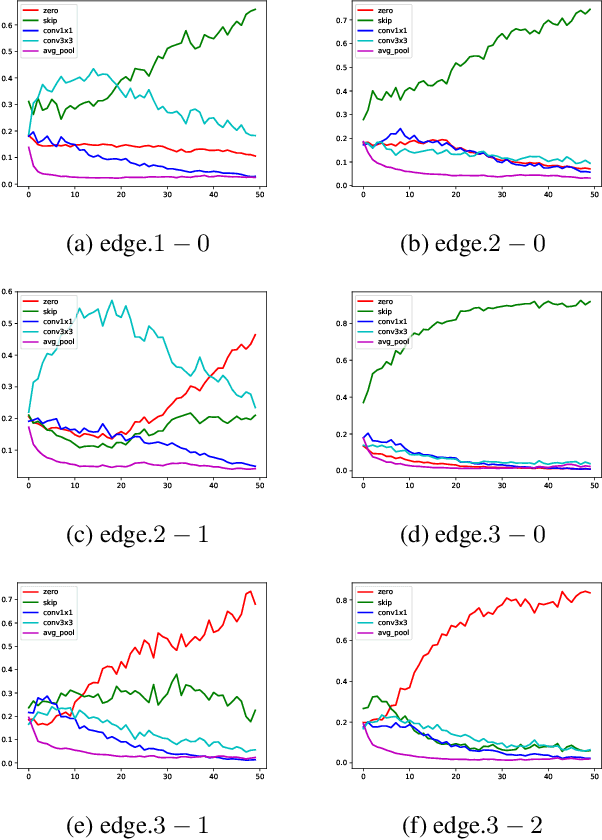

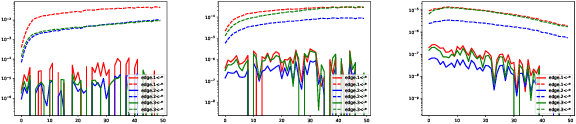

In this paper, we point out that differential architecture search (DARTS) makes gradient of architecture parameters biased for network weights and architecture parameters are updated in different datasets alternatively in the bi-level optimization framework. The bias causes the architecture parameters of non-learnable operations to surpass that of learnable operations. Moreover, using softmax as architecture parameters' activation function and inappropriate learning rate would exacerbate the bias. As a result, it's frequently observed that non-learnable operations are dominated in the search phase. To reduce the bias, we propose to use single-level to replace bi-level optimization and non-competitive activation function like sigmoid to replace softmax. As a result, we could search high-performance architectures steadily. Experiments on NAS Benchmark 201 validate our hypothesis and stably find out nearly the optimal architecture. On DARTS space, we search the state-of-the-art architecture with 77.0% top1 accuracy (training setting follows PDARTS and without any additional module) on ImageNet-1K and steadily search architectures up-to 76.5% top1 accuracy (but not select the best from the searched architectures) which is comparable with current reported best result.
Elements of Effective Deep Reinforcement Learning towards Tactical Driving Decision Making
Feb 01, 2018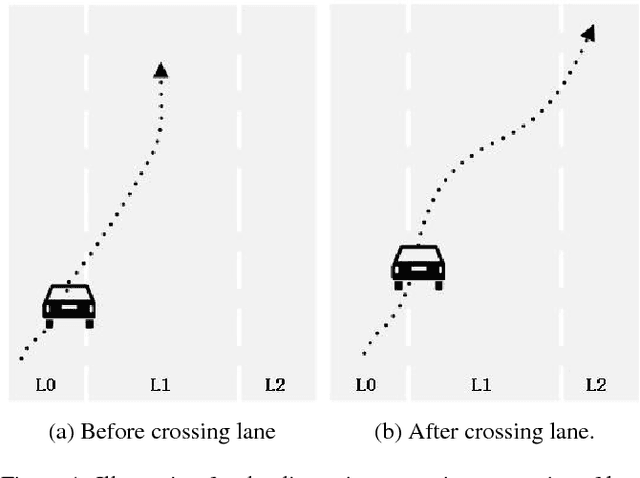



Tactical driving decision making is crucial for autonomous driving systems and has attracted considerable interest in recent years. In this paper, we propose several practical components that can speed up deep reinforcement learning algorithms towards tactical decision making tasks: 1) non-uniform action skipping as a more stable alternative to action-repetition frame skipping, 2) a counter-based penalty for lanes on which ego vehicle has less right-of-road, and 3) heuristic inference-time action masking for apparently undesirable actions. We evaluate the proposed components in a realistic driving simulator and compare them with several baselines. Results show that the proposed scheme provides superior performance in terms of safety, efficiency, and comfort.