 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeSingle-level Optimization For Differential Architecture Search
Paper and Code
Dec 15, 2020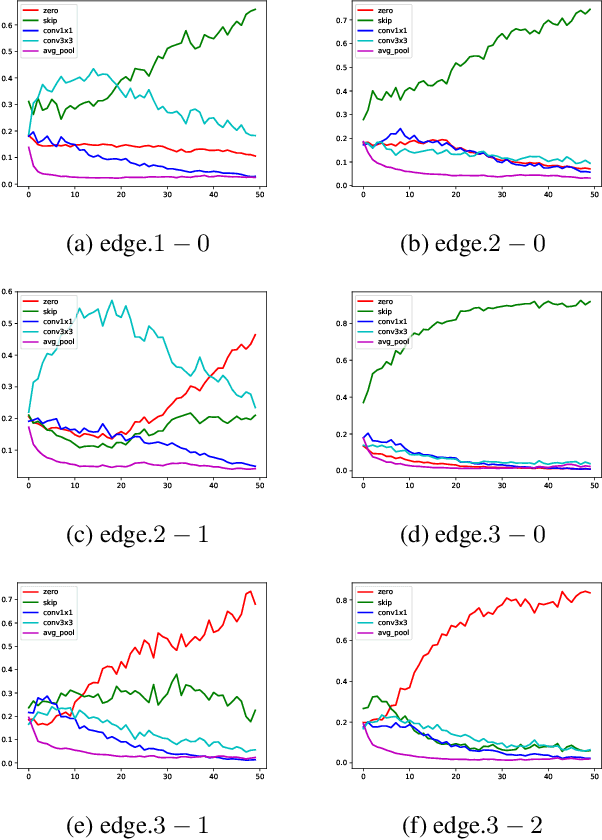

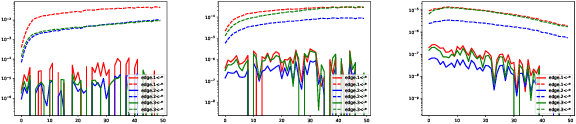

In this paper, we point out that differential architecture search (DARTS) makes gradient of architecture parameters biased for network weights and architecture parameters are updated in different datasets alternatively in the bi-level optimization framework. The bias causes the architecture parameters of non-learnable operations to surpass that of learnable operations. Moreover, using softmax as architecture parameters' activation function and inappropriate learning rate would exacerbate the bias. As a result, it's frequently observed that non-learnable operations are dominated in the search phase. To reduce the bias, we propose to use single-level to replace bi-level optimization and non-competitive activation function like sigmoid to replace softmax. As a result, we could search high-performance architectures steadily. Experiments on NAS Benchmark 201 validate our hypothesis and stably find out nearly the optimal architecture. On DARTS space, we search the state-of-the-art architecture with 77.0% top1 accuracy (training setting follows PDARTS and without any additional module) on ImageNet-1K and steadily search architectures up-to 76.5% top1 accuracy (but not select the best from the searched architectures) which is comparable with current reported best result.