 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeWasserstein Exponential Smoothing
Jun 04, 2026Exponential smoothing (ES) often outperforms other techniques in time series forecasting across a wide range of data-generating processes. While ES has traditionally been applied to time series in $\mathbb{R}$, this paper extends the methodology to distributional time series, where each observation is a probability distribution on $\mathbb{R}$. The primary contribution of this work is twofold. First, we propose a principled and intuitive generalization of ES within the Wasserstein space, which retains the exceptional parsimony of classical ES. Second, we theoretically and empirically demonstrate that the smoothing parameter can be consistently estimated by minimizing a Wasserstein distance. Applications to distributional time series of high-frequency financial returns and household electricity demands confirm the practical effectiveness of our Wasserstein ES model.
Intention-Aware Semantic Agent Communications for AI Glasses
Apr 26, 2026Smart glasses are emerging as a promising interface between humans and artificial intelligence (AI) agents, enabling first-person perception, contextual awareness, and real-time assistance. However, continuous offloading of visual data from wearable devices to cloud-based vision-language models (VLMs) is fundamentally constrained by limited wireless bandwidth and energy resources. This paper proposes an intention-aware semantic agent communication framework for AI glasses, where data transmission is guided by user intention rather than raw pixel fidelity. In the proposed architecture, AI glasses act as an edge semantic agent while a server-side VLM executes high-level cognition and reasoning. The user intention can be inferred by the server-side VLM through the current transmitted content and the historical prompts. Driven by specific user intentions, the glasses adaptively preserve textual content, document layout, or object semantics before transmission. We evaluate three representative scenarios with different lightweight preprocessing tools on the AI glasses. Simulation results demonstrate that intention-aware preprocessing significantly achieves more than 50% bandwidth reduction depending on the current task while maintaining task performance. Moreover, semantic transmission exhibits graceful degradation under low SNRs. The findings demonstrate that aligning communication resources with user intention is essential for robust and efficient wearable AI agent systems.
AgentComm: Semantic Communication for Embodied Agents
Apr 15, 2026The increasing deployment of agentic artificial intelligence (AI) systems has intensified the demand for efficient agent to agent communication, particularly over bandwidth limited wireless links. In embodied AI applications, agents must exchange task related information under strict latency and reliability constraints. Existing agent communication methods primarily focus on connectivity and protocol efficiency, but lack effective mechanisms to reduce physical layer transmission overhead while preserving task semantics.To address this challenge, this paper proposes a semantic agent communication framework that reduces communication overhead while maintaining task performance and shared understanding among agents. An LLM based semantic processor is first introduced to reorganize and condense agent generated messages by extracting task relevant semantic content. To cope with information loss introduced by aggressive message reduction, an importance-aware semantic transmission strategy is developed, which adaptively protects semantic components according to their task importance. Furthermore, a task specific knowledge base is incorporated as long term semantic memory to support recurring tasks and further reduce bandwidth consumption with minimal performance degradation. Experimental results and ablation studies demonstrate that the proposed framework achieves nearly 50% bandwidth reduction with negligible loss in task completion performance compared to conventional transmission schemes.
Semantic Satellite Communications for Synchronized Audiovisual Reconstruction
Mar 11, 2026Satellite communications face severe bottlenecks in supporting high-fidelity synchronized audiovisual services, as conventional schemes struggle with cross-modal coherence under fluctuating channel conditions, limited bandwidth, and long propagation delays. To address these limitations, this paper proposes an adaptive multimodal semantic transmission system tailored for satellite scenarios, aiming for high-quality synchronized audiovisual reconstruction under bandwidth constraints. Unlike static schemes with fixed modal priorities, our framework features a dual-stream generative architecture that flexibly switches between video-driven audio generation and audio-driven video generation. This allows the system to dynamically decouple semantics, transmitting only the most important modality while employing cross-modal generation to recover the other. To balance reconstruction quality and transmission overhead, a dynamic keyframe update mechanism adaptively maintains the shared knowledge base according to wireless scenarios and user requirements. Furthermore, a large language model based decision module is introduced to enhance system adaptability. By integrating satellite-specific knowledge, this module jointly considers task requirements and channel factors such as weather-induced fading to proactively adjust transmission paths and generation workflows. Simulation results demonstrate that the proposed system significantly reduces bandwidth consumption while achieving high-fidelity audiovisual synchronization, improving transmission efficiency and robustness in challenging satellite scenarios.
Bures-Wasserstein Importance-Weighted Evidence Lower Bound: Exposition and Applications
Feb 04, 2026The Importance-Weighted Evidence Lower Bound (IW-ELBO) has emerged as an effective objective for variational inference (VI), tightening the standard ELBO and mitigating the mode-seeking behaviour. However, optimizing the IW-ELBO in Euclidean space is often inefficient, as its gradient estimators suffer from a vanishing signal-to-noise ratio (SNR). This paper formulates the optimisation of the IW-ELBO in Bures-Wasserstein space, a manifold of Gaussian distributions equipped with the 2-Wasserstein metric. We derive the Wasserstein gradient of the IW-ELBO and project it onto the Bures-Wasserstein space to yield a tractable algorithm for Gaussian VI. A pivotal contribution of our analysis concerns the stability of the gradient estimator. While the SNR of the standard Euclidean gradient estimator is known to vanish as the number of importance samples $K$ increases, we prove that the SNR of the Wasserstein gradient scales favourably as $Ω(\sqrt{K})$, ensuring optimisation efficiency even for large $K$. We further extend this geometric analysis to the Variational Rényi Importance-Weighted Autoencoder bound, establishing analogous stability guarantees. Experiments demonstrate that the proposed framework achieves superior approximation performance compared to other baselines.
Position-Aided Semantic Communication for Efficient Image Transmission: Design, Implementation, and Experimental Results
Oct 24, 2024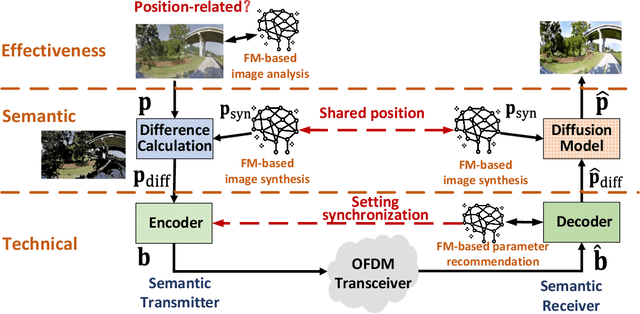
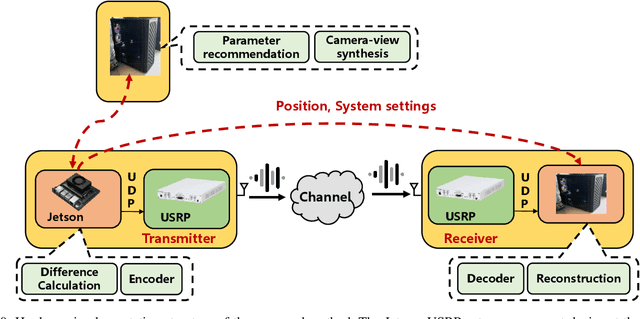
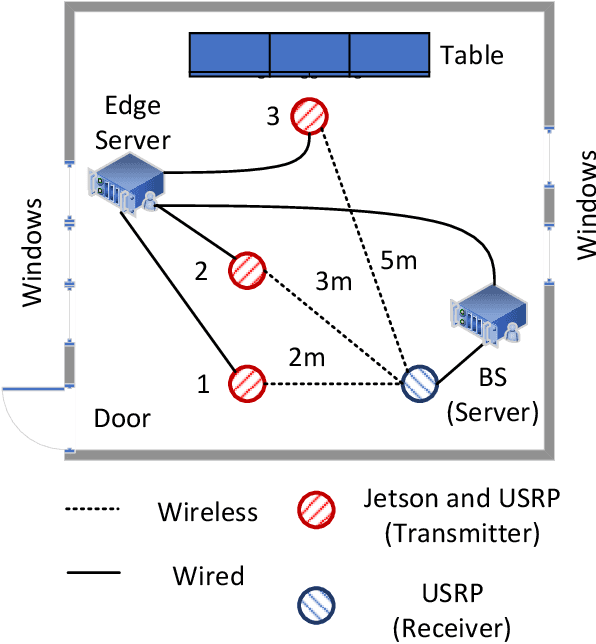

Semantic communication, augmented by knowledge bases (KBs), offers substantial reductions in transmission overhead and resilience to errors. However, existing methods predominantly rely on end-to-end training to construct KBs, often failing to fully capitalize on the rich information available at communication devices. Motivated by the growing convergence of sensing and communication, we introduce a novel Position-Aided Semantic Communication (PASC) framework, which integrates localization into semantic transmission. This framework is particularly designed for position-based image communication, such as real-time uploading of outdoor camera-view images. By utilizing the position, the framework retrieves corresponding maps, and then an advanced foundation model (FM)-driven view generator is employed to synthesize images closely resembling the target images. The PASC framework further leverages the FM to fuse the synthesized image with deviations from the real one, enhancing semantic reconstruction. Notably, the framework is highly flexible, capable of adapting to dynamic content and fluctuating channel conditions through a novel FM-based parameter optimization strategy. Additionally, the challenges of real-time deployment are addressed, with the development of a hardware testbed to validate the framework. Simulations and real-world tests demonstrate that the proposed PASC approach not only significantly boosts transmission efficiency, but also remains robust in diverse and evolving transmission scenarios.
Generative Diffusion Models for High Dimensional Channel Estimation
Aug 20, 2024



Along with the prosperity of generative artificial intelligence (AI), its potential for solving conventional challenges in wireless communications has also surfaced. Inspired by this trend, we investigate the application of the advanced diffusion models (DMs), a representative class of generative AI models, to high dimensional wireless channel estimation. By capturing the structure of multiple-input multiple-output (MIMO) wireless channels via a deep generative prior encoded by DMs, we develop a novel posterior inference method for channel reconstruction. We further adapt the proposed method to recover channel information from low-resolution quantized measurements. Additionally, to enhance the over-the-air viability, we integrate the DM with the unsupervised Stein's unbiased risk estimator to enable learning from noisy observations and circumvent the requirements for ground truth channel data that is hardly available in practice. Results reveal that the proposed estimator achieves high-fidelity channel recovery while reducing estimation latency by a factor of 10 compared to state-of-the-art schemes, facilitating real-time implementation. Moreover, our method outperforms existing estimators while reducing the pilot overhead by half, showcasing its scalability to ultra-massive antenna arrays.
Adaptive Wireless Image Semantic Transmission and Over-The-Air Testing
May 22, 2024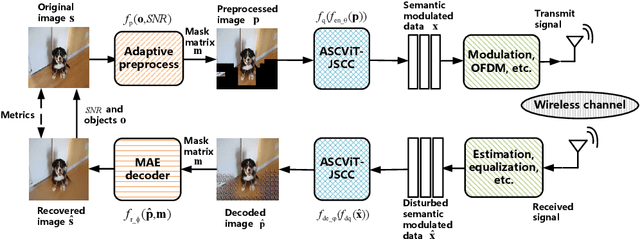



Semantic communication has undergone considerable evolution due to the recent rapid development of artificial intelligence (AI), significantly enhancing both communication robustness and efficiency. Despite these advancements, most current semantic communication methods for image transmission pay little attention to the differing importance of objects and backgrounds in images. To address this issue, we propose a novel scheme named ASCViT-JSCC, which utilizes vision transformers (ViTs) integrated with an orthogonal frequency division multiplexing (OFDM) system. This scheme adaptively allocates bandwidth for objects and backgrounds in images according to the importance order of different parts determined by object detection of you only look once version 5 (YOLOv5) and feature points detection of scale invariant feature transform (SIFT). Furthermore, the proposed scheme adheres to digital modulation standards by incorporating quantization modules. We validate this approach through an over-the-air (OTA) testbed named intelligent communication prototype validation platform (ICP) based on a software-defined radio (SDR) and NVIDIA embedded kits. Our findings from both simulations and practical measurements show that ASCViT-JSCC significantly preserves objects in images and enhances reconstruction quality compared to existing methods.
Semantic Satellite Communications Based on Generative Foundation Model
Apr 18, 2024


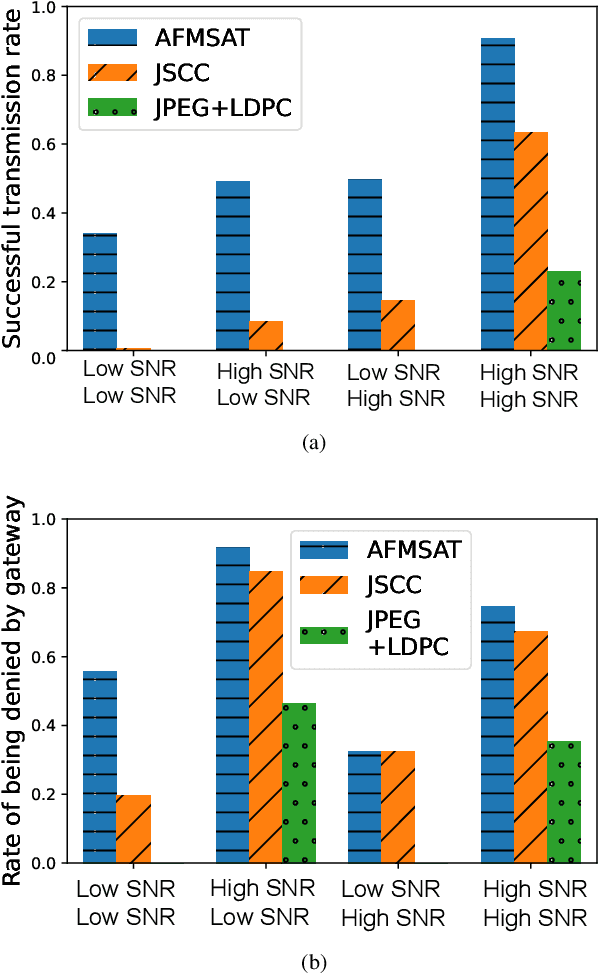
Satellite communications can provide massive connections and seamless coverage, but they also face several challenges, such as rain attenuation, long propagation delays, and co-channel interference. To improve transmission efficiency and address severe scenarios, semantic communication has become a popular choice, particularly when equipped with foundation models (FMs). In this study, we introduce an FM-based semantic satellite communication framework, termed FMSAT. This framework leverages FM-based segmentation and reconstruction to significantly reduce bandwidth requirements and accurately recover semantic features under high noise and interference. Considering the high speed of satellites, an adaptive encoder-decoder is proposed to protect important features and avoid frequent retransmissions. Meanwhile, a well-received image can provide a reference for repairing damaged images under sudden attenuation. Since acknowledgment feedback is subject to long propagation delays when retransmission is unavoidable, a novel error detection method is proposed to roughly detect semantic errors at the regenerative satellite. With the proposed detectors at both the satellite and the gateway, the quality of the received images can be ensured. The simulation results demonstrate that the proposed method can significantly reduce bandwidth requirements, adapt to complex satellite scenarios, and protect semantic information with an acceptable transmission delay.
Semantic Communications using Foundation Models: Design Approaches and Open Issues
Sep 23, 2023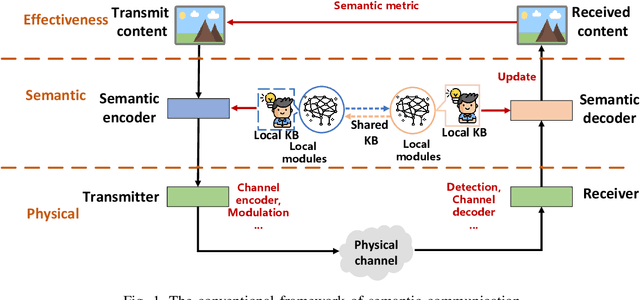
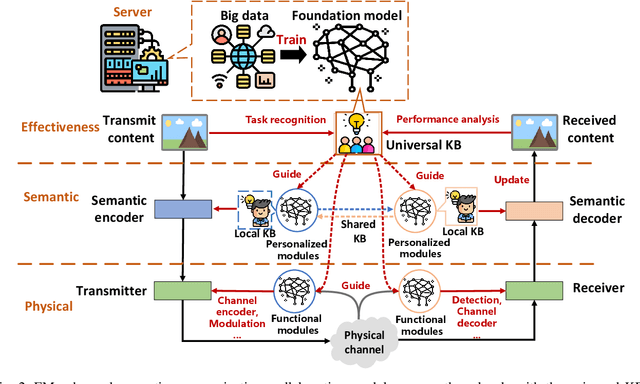
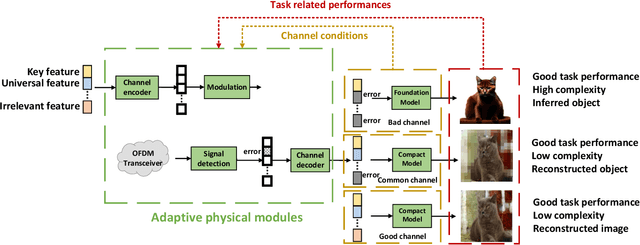
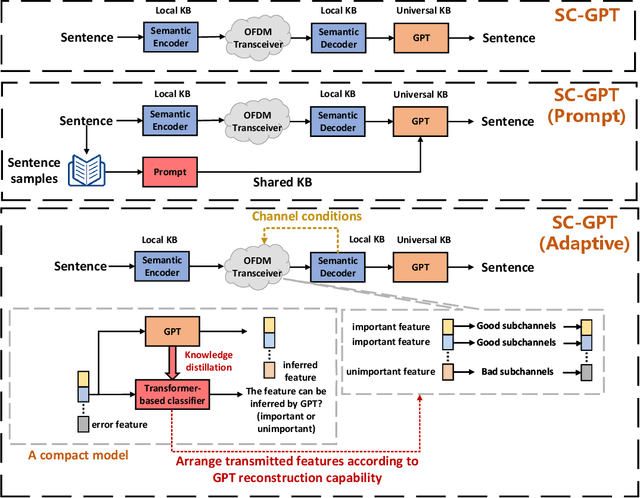
Foundation models (FMs), including large language models, have become increasingly popular due to their wide-ranging applicability and ability to understand human-like semantics. While previous research has explored the use of FMs in semantic communications to improve semantic extraction and reconstruction, the impact of these models on different system levels, considering computation and memory complexity, requires further analysis. This study focuses on integrating FMs at the effectiveness, semantic, and physical levels, using universal knowledge to profoundly transform system design. Additionally, it examines the use of compact models to balance performance and complexity, comparing three separate approaches that employ FMs. Ultimately, the study highlights unresolved issues in the field that need addressing.