 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeAdaptive Wireless Image Semantic Transmission and Over-The-Air Testing
Paper and Code
May 22, 2024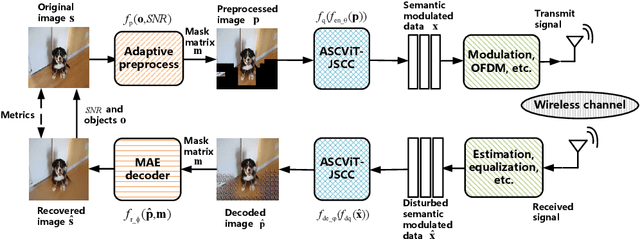



Semantic communication has undergone considerable evolution due to the recent rapid development of artificial intelligence (AI), significantly enhancing both communication robustness and efficiency. Despite these advancements, most current semantic communication methods for image transmission pay little attention to the differing importance of objects and backgrounds in images. To address this issue, we propose a novel scheme named ASCViT-JSCC, which utilizes vision transformers (ViTs) integrated with an orthogonal frequency division multiplexing (OFDM) system. This scheme adaptively allocates bandwidth for objects and backgrounds in images according to the importance order of different parts determined by object detection of you only look once version 5 (YOLOv5) and feature points detection of scale invariant feature transform (SIFT). Furthermore, the proposed scheme adheres to digital modulation standards by incorporating quantization modules. We validate this approach through an over-the-air (OTA) testbed named intelligent communication prototype validation platform (ICP) based on a software-defined radio (SDR) and NVIDIA embedded kits. Our findings from both simulations and practical measurements show that ASCViT-JSCC significantly preserves objects in images and enhances reconstruction quality compared to existing methods.