 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeH2OVL-Mississippi Vision Language Models Technical Report
Oct 17, 2024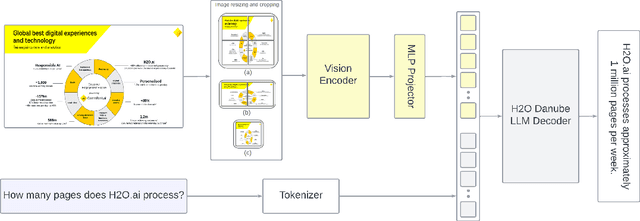
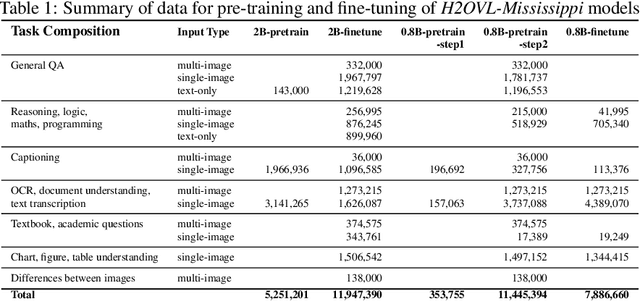
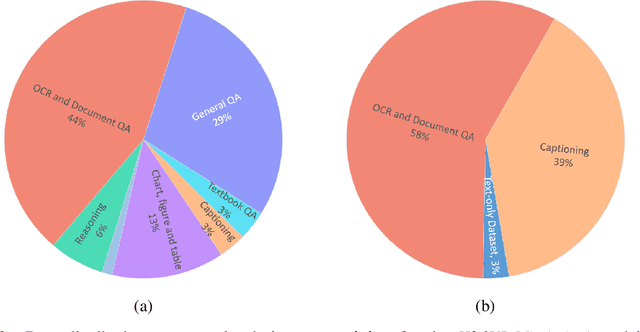
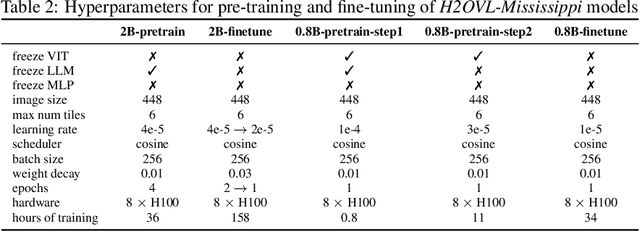
Smaller vision-language models (VLMs) are becoming increasingly important for privacy-focused, on-device applications due to their ability to run efficiently on consumer hardware for processing enterprise commercial documents and images. These models require strong language understanding and visual capabilities to enhance human-machine interaction. To address this need, we present H2OVL-Mississippi, a pair of small VLMs trained on 37 million image-text pairs using 240 hours of compute on 8 x H100 GPUs. H2OVL-Mississippi-0.8B is a tiny model with 0.8 billion parameters that specializes in text recognition, achieving state of the art performance on the Text Recognition portion of OCRBench and surpassing much larger models in this area. Additionally, we are releasing H2OVL-Mississippi-2B, a 2 billion parameter model for general use cases, exhibiting highly competitive metrics across various academic benchmarks. Both models build upon our prior work with H2O-Danube language models, extending their capabilities into the visual domain. We release them under the Apache 2.0 license, making VLMs accessible to everyone, democratizing document AI and visual LLMs.
H2O-Danube3 Technical Report
Jul 12, 2024



We present H2O-Danube3, a series of small language models consisting of H2O-Danube3-4B, trained on 6T tokens and H2O-Danube3-500M, trained on 4T tokens. Our models are pre-trained on high quality Web data consisting of primarily English tokens in three stages with different data mixes before final supervised tuning for chat version. The models exhibit highly competitive metrics across a multitude of academic, chat, and fine-tuning benchmarks. Thanks to its compact architecture, H2O-Danube3 can be efficiently run on a modern smartphone, enabling local inference and rapid processing capabilities even on mobile devices. We make all models openly available under Apache 2.0 license further democratizing LLMs to a wider audience economically.
H2O-Danube-1.8B Technical Report
Jan 30, 2024We present H2O-Danube-1.8B, a 1.8B language model trained on 1T tokens following the core principles of LLama 2 and Mistral. We leverage and refine various techniques for pre-training large language models. Although our model is trained on significantly fewer total tokens compared to reference models of similar size, it exhibits highly competitive metrics across a multitude of benchmarks. We additionally release a chat model trained with supervised fine-tuning followed by direct preference optimization. We make H2O-Danube-1.8B openly available under Apache 2.0 license further democratizing LLMs to a wider audience economically.
H2O Open Ecosystem for State-of-the-art Large Language Models
Oct 23, 2023
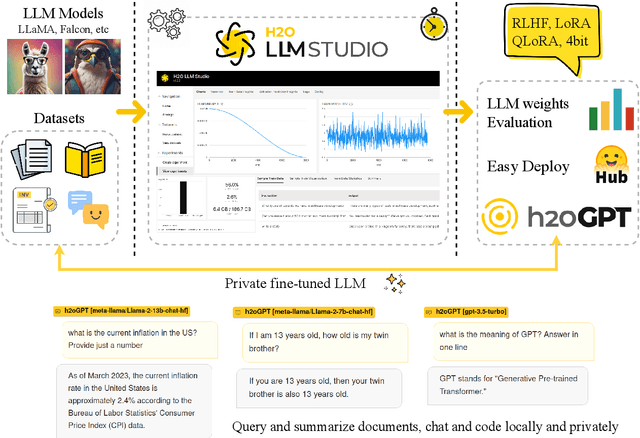
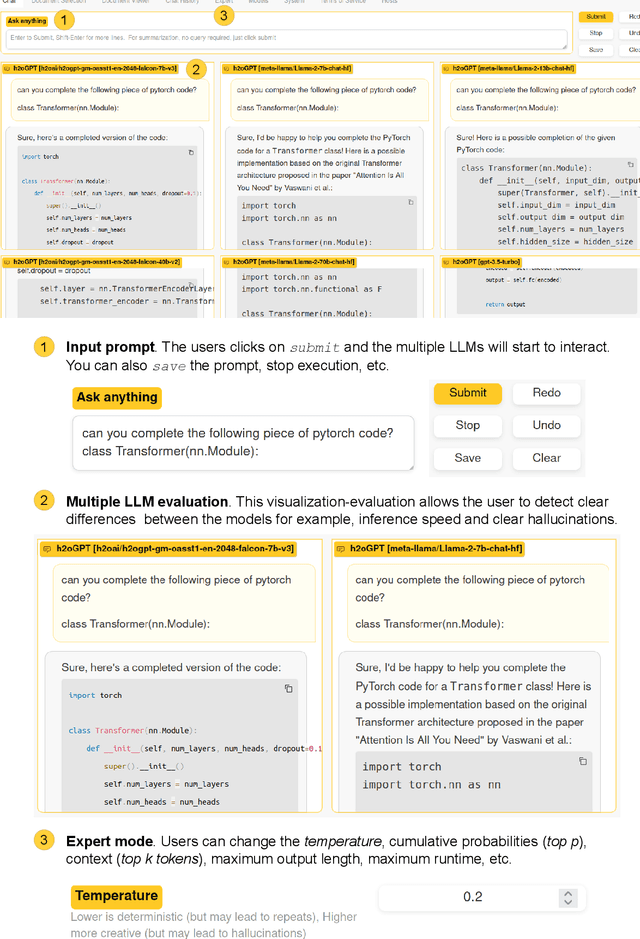
Large Language Models (LLMs) represent a revolution in AI. However, they also pose many significant risks, such as the presence of biased, private, copyrighted or harmful text. For this reason we need open, transparent and safe solutions. We introduce a complete open-source ecosystem for developing and testing LLMs. The goal of this project is to boost open alternatives to closed-source approaches. We release h2oGPT, a family of fine-tuned LLMs of diverse sizes. We also introduce H2O LLM Studio, a framework and no-code GUI designed for efficient fine-tuning, evaluation, and deployment of LLMs using the most recent state-of-the-art techniques. Our code and models are fully open-source. We believe this work helps to boost AI development and make it more accessible, efficient and trustworthy. The demo is available at: https://gpt.h2o.ai/
h2oGPT: Democratizing Large Language Models
Jun 16, 2023


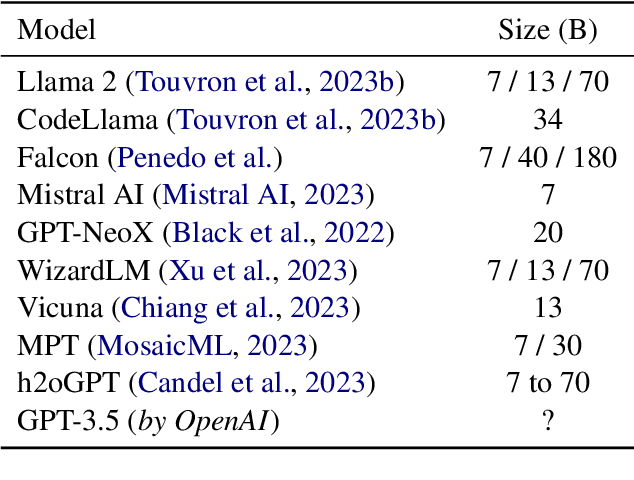
Applications built on top of Large Language Models (LLMs) such as GPT-4 represent a revolution in AI due to their human-level capabilities in natural language processing. However, they also pose many significant risks such as the presence of biased, private, or harmful text, and the unauthorized inclusion of copyrighted material. We introduce h2oGPT, a suite of open-source code repositories for the creation and use of LLMs based on Generative Pretrained Transformers (GPTs). The goal of this project is to create the world's best truly open-source alternative to closed-source approaches. In collaboration with and as part of the incredible and unstoppable open-source community, we open-source several fine-tuned h2oGPT models from 7 to 40 Billion parameters, ready for commercial use under fully permissive Apache 2.0 licenses. Included in our release is 100\% private document search using natural language. Open-source language models help boost AI development and make it more accessible and trustworthy. They lower entry hurdles, allowing people and groups to tailor these models to their needs. This openness increases innovation, transparency, and fairness. An open-source strategy is needed to share AI benefits fairly, and H2O.ai will continue to democratize AI and LLMs.
Recognizing bird species in diverse soundscapes under weak supervision
Jul 16, 2021
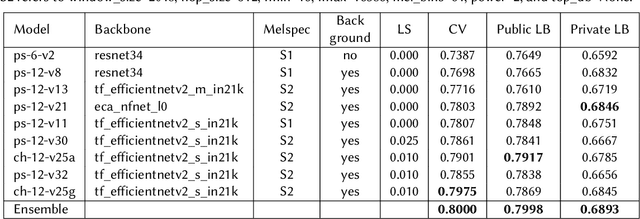
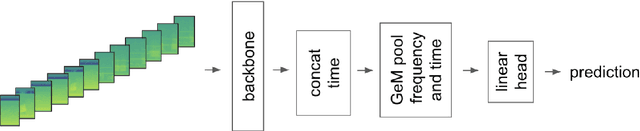
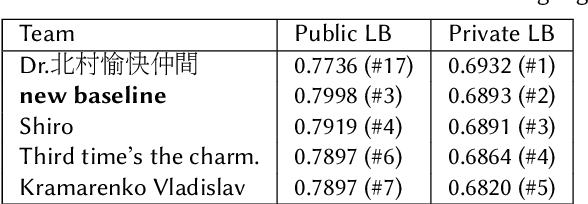
We present a robust classification approach for avian vocalization in complex and diverse soundscapes, achieving second place in the BirdCLEF2021 challenge. We illustrate how to make full use of pre-trained convolutional neural networks, by using an efficient modeling and training routine supplemented by novel augmentation methods. Thereby, we improve the generalization of weakly labeled crowd-sourced data to productive data collected by autonomous recording units. As such, we illustrate how to progress towards an accurate automated assessment of avian population which would enable global biodiversity monitoring at scale, impossible by manual annotation.
Corridor for new mobility Aachen-Düsseldorf: Methods and concepts of the research project ACCorD
Jul 13, 2021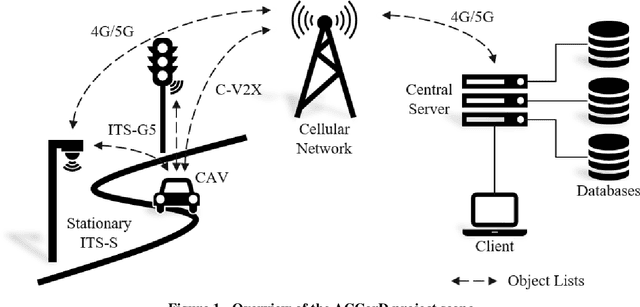
With the Corridor for New Mobility Aachen - D\"usseldorf, an integrated development environment is created, incorporating existing test capabilities, to systematically test and validate automated vehicles in interaction with connected Intelligent Transport Systems Stations (ITS-Ss). This is achieved through a time- and cost-efficient toolchain and methodology, in which simulation, closed test sites as well as test fields in public transport are linked in the best possible way. By implementing a digital twin, the recorded traffic events can be visualized in real-time and driving functions can be tested in the simulation based on real data. In order to represent diverse traffic scenarios, the corridor contains a highway section, a rural area, and urban areas. First, this paper outlines the project goals before describing the individual project contents in more detail. These include the concepts of traffic detection, driving function development, digital twin development, and public involvement.