 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeH2OVL-Mississippi Vision Language Models Technical Report
Oct 17, 2024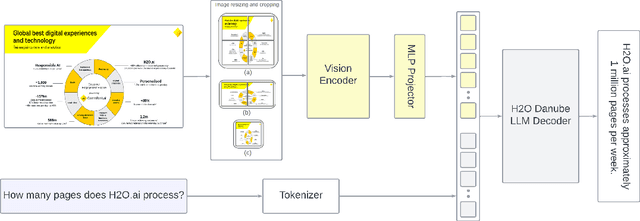
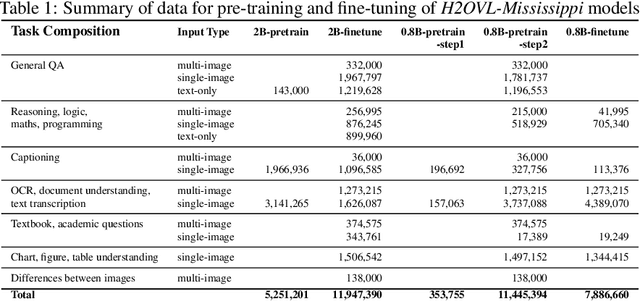
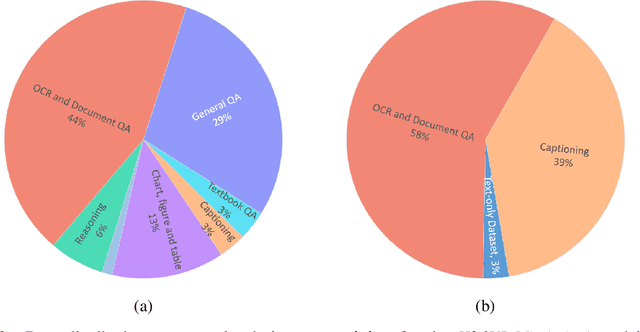
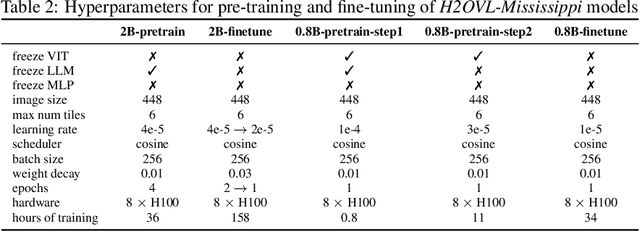
Smaller vision-language models (VLMs) are becoming increasingly important for privacy-focused, on-device applications due to their ability to run efficiently on consumer hardware for processing enterprise commercial documents and images. These models require strong language understanding and visual capabilities to enhance human-machine interaction. To address this need, we present H2OVL-Mississippi, a pair of small VLMs trained on 37 million image-text pairs using 240 hours of compute on 8 x H100 GPUs. H2OVL-Mississippi-0.8B is a tiny model with 0.8 billion parameters that specializes in text recognition, achieving state of the art performance on the Text Recognition portion of OCRBench and surpassing much larger models in this area. Additionally, we are releasing H2OVL-Mississippi-2B, a 2 billion parameter model for general use cases, exhibiting highly competitive metrics across various academic benchmarks. Both models build upon our prior work with H2O-Danube language models, extending their capabilities into the visual domain. We release them under the Apache 2.0 license, making VLMs accessible to everyone, democratizing document AI and visual LLMs.
Computer Aided Detection of Oral Lesions on CT Images
Nov 29, 2016Oral lesions are important findings on computed tomography (CT) images. In this study, a fully automatic method to detect oral lesions in mandibular region from dental CT images is proposed. Two methods were developed to recognize two types of lesions namely (1) Close border (CB) lesions and (2) Open border (OB) lesions, which cover most of the lesion types that can be found on CT images. For the detection of CB lesions, fifteen features were extracted from each initial lesion candidates and multi layer perceptron (MLP) neural network was used to classify suspicious regions. Moreover, OB lesions were detected using a rule based image processing method, where no feature extraction or classification algorithm were used. The results were validated using a CT dataset of 52 patients, where 22 patients had abnormalities and 30 patients were normal. Using non-training dataset, CB detection algorithm yielded 71% sensitivity with 0.31 false positives per patient. Furthermore, OB detection algorithm achieved 100% sensitivity with 0.13 false positives per patient. Results suggest that, the proposed framework, which consists of two methods, has the potential to be used in clinical context, and assist radiologists for better diagnosis.