 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeH2OVL-Mississippi Vision Language Models Technical Report
Oct 17, 2024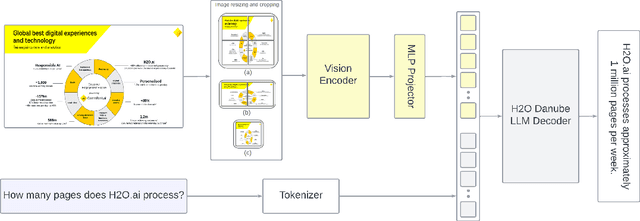
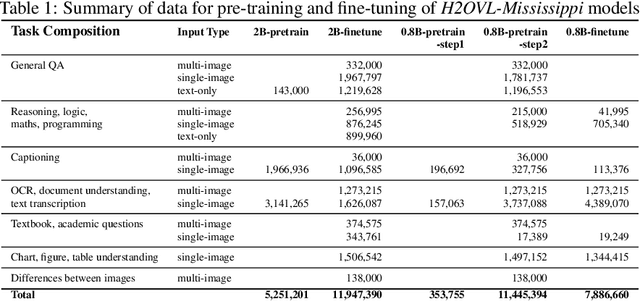
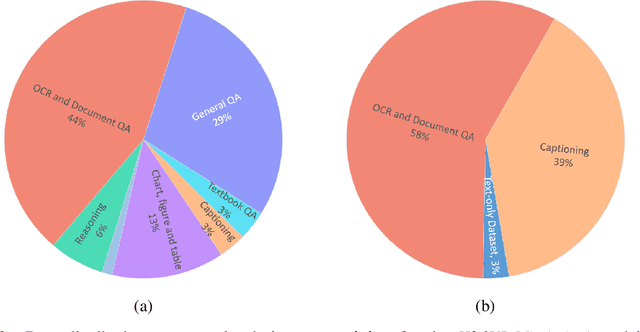
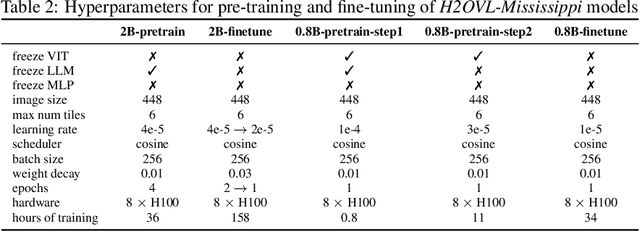
Smaller vision-language models (VLMs) are becoming increasingly important for privacy-focused, on-device applications due to their ability to run efficiently on consumer hardware for processing enterprise commercial documents and images. These models require strong language understanding and visual capabilities to enhance human-machine interaction. To address this need, we present H2OVL-Mississippi, a pair of small VLMs trained on 37 million image-text pairs using 240 hours of compute on 8 x H100 GPUs. H2OVL-Mississippi-0.8B is a tiny model with 0.8 billion parameters that specializes in text recognition, achieving state of the art performance on the Text Recognition portion of OCRBench and surpassing much larger models in this area. Additionally, we are releasing H2OVL-Mississippi-2B, a 2 billion parameter model for general use cases, exhibiting highly competitive metrics across various academic benchmarks. Both models build upon our prior work with H2O-Danube language models, extending their capabilities into the visual domain. We release them under the Apache 2.0 license, making VLMs accessible to everyone, democratizing document AI and visual LLMs.