 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeNemotron ColEmbed V2: Top-Performing Late Interaction embedding models for Visual Document Retrieval
Feb 03, 2026Retrieval-Augmented Generation (RAG) systems have been popular for generative applications, powering language models by injecting external knowledge. Companies have been trying to leverage their large catalog of documents (e.g. PDFs, presentation slides) in such RAG pipelines, whose first step is the retrieval component. Dense retrieval has been a popular approach, where embedding models are used to generate a dense representation of the user query that is closer to relevant content embeddings. More recently, VLM-based embedding models have become popular for visual document retrieval, as they preserve visual information and simplify the indexing pipeline compared to OCR text extraction. Motivated by the growing demand for visual document retrieval, we introduce Nemotron ColEmbed V2, a family of models that achieve state-of-the-art performance on the ViDoRe benchmarks. We release three variants - with 3B, 4B, and 8B parameters - based on pre-trained VLMs: NVIDIA Eagle 2 with Llama 3.2 3B backbone, Qwen3-VL-4B-Instruct and Qwen3-VL-8B-Instruct, respectively. The 8B model ranks first on the ViDoRe V3 leaderboard as of February 03, 2026, achieving an average NDCG@10 of 63.42. We describe the main techniques used across data processing, training, and post-training - such as cluster-based sampling, hard-negative mining, bidirectional attention, late interaction, and model merging - that helped us build our top-performing models. We also discuss compute and storage engineering challenges posed by the late interaction mechanism and present experiments on how to balance accuracy and storage with lower dimension embeddings.
H2OVL-Mississippi Vision Language Models Technical Report
Oct 17, 2024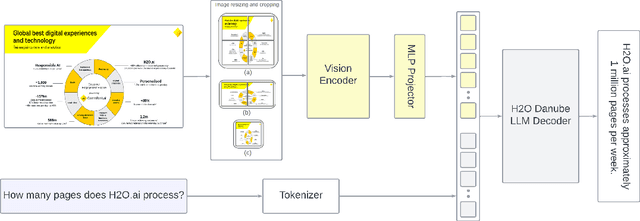
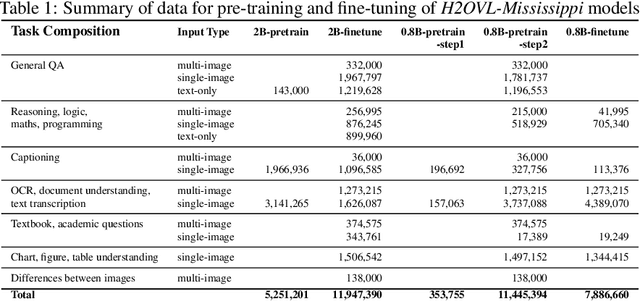
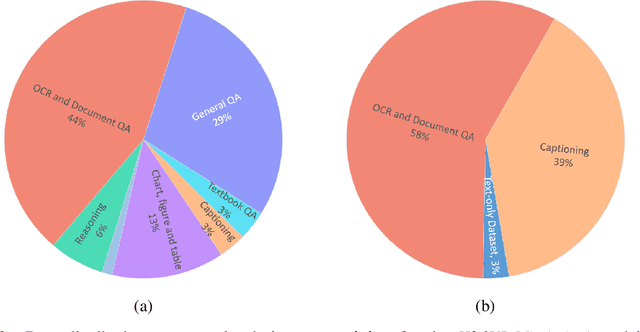
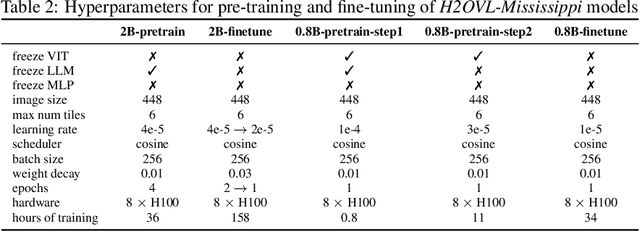
Smaller vision-language models (VLMs) are becoming increasingly important for privacy-focused, on-device applications due to their ability to run efficiently on consumer hardware for processing enterprise commercial documents and images. These models require strong language understanding and visual capabilities to enhance human-machine interaction. To address this need, we present H2OVL-Mississippi, a pair of small VLMs trained on 37 million image-text pairs using 240 hours of compute on 8 x H100 GPUs. H2OVL-Mississippi-0.8B is a tiny model with 0.8 billion parameters that specializes in text recognition, achieving state of the art performance on the Text Recognition portion of OCRBench and surpassing much larger models in this area. Additionally, we are releasing H2OVL-Mississippi-2B, a 2 billion parameter model for general use cases, exhibiting highly competitive metrics across various academic benchmarks. Both models build upon our prior work with H2O-Danube language models, extending their capabilities into the visual domain. We release them under the Apache 2.0 license, making VLMs accessible to everyone, democratizing document AI and visual LLMs.
h2oGPT: Democratizing Large Language Models
Jun 16, 2023


Applications built on top of Large Language Models (LLMs) such as GPT-4 represent a revolution in AI due to their human-level capabilities in natural language processing. However, they also pose many significant risks such as the presence of biased, private, or harmful text, and the unauthorized inclusion of copyrighted material. We introduce h2oGPT, a suite of open-source code repositories for the creation and use of LLMs based on Generative Pretrained Transformers (GPTs). The goal of this project is to create the world's best truly open-source alternative to closed-source approaches. In collaboration with and as part of the incredible and unstoppable open-source community, we open-source several fine-tuned h2oGPT models from 7 to 40 Billion parameters, ready for commercial use under fully permissive Apache 2.0 licenses. Included in our release is 100\% private document search using natural language. Open-source language models help boost AI development and make it more accessible and trustworthy. They lower entry hurdles, allowing people and groups to tailor these models to their needs. This openness increases innovation, transparency, and fairness. An open-source strategy is needed to share AI benefits fairly, and H2O.ai will continue to democratize AI and LLMs.