 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeHigh-Rate Quantized Matrix Multiplication II
May 13, 2026This is the second part of the work investigating quantized matrix multiplication (MatMul). In part I we considered the case of calibration-free quantization, whereas here we discuss the setting where covariance matrix $Σ_X$ of the columns of the second factor is available. This setting arises in the ubiquitous task of weight-only post-training quantization of LLMs. Weight-only quantization is related to the problem of weighted mean squared error (WMSE) source coding, whose classical (reverse) waterfilling solution dictates how one should distribute rate between coordinates of the vector. We show how waterfilling can be used to improve practical LLM quantization algorithms (GPTQ), which at present allocate rate equally. A recent scheme (known as ``WaterSIC'') that only uses scalar INT quantizers is analyzed and its high-rate performance is shown to be (a) basis free (i.e., characterized by the determinant of $Σ_X$ and, thus, unlike existing schemes, is immune to applying random rotations); and (b) within a multiplicative factor of $\frac{2πe}{12}$ (or 0.25 bit/entry) of the information-theoretic distortion limit. GPTQ's performance, in turn, is affected by the choice of basis, but for a random rotation and actual $Σ_X$ from Llama-3-8B we find it to be within 0.1 bit (depending on the layer type) of WaterSIC, suggesting that GPTQ with random rotation is also near optimal, at least in the high-rate regime.
WaterSIC: information-theoretically (near) optimal linear layer quantization
Mar 05, 2026This paper considers the problem of converting a given dense linear layer to low precision. The tradeoff between compressed length and output discrepancy is analyzed information theoretically (IT). It is shown that a popular GPTQ algorithm may have an arbitrarily large gap to the IT limit. To alleviate this problem, a novel algorithm, termed ''WaterSIC'', is proposed and is shown to be within a rate gap of 0.255 bits to the IT limit, uniformly over all possible covariance matrices of input activations. The key innovation of WaterSIC's is to allocate different quantization rates to different columns (in-features) of the weight matrix, mimicking the classical IT solution known as ''waterfilling''. Applying WaterSIC to the Llama and Qwen family of LLMs establishes new state-of-the-art performance for all quantization rates from 1 to 4 bits.
Price of universality in vector quantization is at most 0.11 bit
Feb 05, 2026Fast computation of a matrix product $W^\top X$ is a workhorse of modern LLMs. To make their deployment more efficient, a popular approach is that of using a low-precision approximation $\widehat W$ in place of true $W$ ("weight-only quantization''). Information theory demonstrates that an optimal algorithm for reducing precision of $W$ depends on the (second order) statistics of $X$ and requires a careful alignment of vector quantization codebook with PCA directions of $X$ (a process known as "waterfilling allocation''). Dependence of the codebook on statistics of $X$, however, is highly impractical. This paper proves that there exist a universal codebook that is simultaneously near-optimal for all possible statistics of $X$, in the sense of being at least as good as an $X$-adapted waterfilling codebook with rate reduced by 0.11 bit per dimension. Such universal codebook would be an ideal candidate for the low-precision storage format, a topic of active modern research, but alas the existence proof is non-constructive. Equivalently, our result shows existence of a net in $\mathbb{R}^n$ that is a nearly-optimal covering of a sphere simultaneously with respect to all Hilbert norms.
High-Rate Quantized Matrix Multiplication: Theory and Practice
Jan 23, 2026This work investigates the problem of quantized matrix multiplication (MatMul), which has become crucial for the efficient deployment of large language models (LLMs). We consider two settings: 1) Generic MatMul, where both matrices must be quantized (weight+activation quantization); and 2) weight-only quantization, where the second matrix is only known through covariance matrix $Σ_X$ of its columns. For each setting, we first review the fundamental information-theoretic tradeoff between quantization rate and distortion (high-rate theory), and then analyze the performance of several popular quantization schemes, comparing them to these fundamental limits. Specifically, we discuss rate loss (compared to information theoretic optima) of absmax INT and floating-point (FP) quantization, for which we also derive remarkably accurate heuristic approximations. Weight-only quantization is related to the problem of weighted mean squared error (WMSE) source coding, whose classical (reverse) waterfilling solution dictates how one should distribute rate between coordinates of the vector. We show how waterfilling can be used to improve practical LLM quantization algorithms (GPTQ), which at present allocate rate equally. This new scheme (termed ``WaterSIC'') only uses scalar INT quantizers, but its high-rate performance is basis free (it depends only on the determinant of $Σ_X$ and, thus, unlike existing schemes, is immune to applying random rotations) and is within a multiplicative factor of $\frac{2πe}{12}$ (or 0.25 bit/entry) of the information-theoretic distortion limit (!). GPTQ's performance is affected by the choice of basis, but for a random rotation and actual $Σ_X$ from Llama-3-8B we find GPTQ to be within 0.1 bit (depending on the layer type) of WaterSIC, suggesting that GPTQ with random rotation is also near optimal (for high-rate quantization).
Optimal Online Bookmaking for Binary Games
Jan 12, 2025In online betting, the bookmaker can update the payoffs it offers on a particular event many times before the event takes place, and the updated payoffs may depend on the bets accumulated thus far. We study the problem of bookmaking with the goal of maximizing the return in the worst-case, with respect to the gamblers' behavior and the event's outcome. We formalize this problem as the \emph{Optimal Online Bookmaking game}, and provide the exact solution for the binary case. To this end, we develop the optimal bookmaking strategy, which relies on a new technique called bi-balancing trees, that assures that the house loss is the same for all \emph{decisive} betting sequences, where the gambler bets all its money on a single outcome in each round.
Optimal Quantization for Matrix Multiplication
Oct 17, 2024Recent work in machine learning community proposed multiple methods for performing lossy compression (quantization) of large matrices. This quantization is important for accelerating matrix multiplication (main component of large language models), which is often bottlenecked by the speed of loading these matrices from memory. Unlike classical vector quantization and rate-distortion theory, the goal of these new compression algorithms is to be able to approximate not the matrices themselves, but their matrix product. Specifically, given a pair of real matrices $A,B$ an encoder (compressor) is applied to each of them independently producing descriptions with $R$ bits per entry. These representations subsequently are used by the decoder to estimate matrix product $A^\top B$. In this work, we provide a non-asymptotic lower bound on the mean squared error of this approximation (as a function of rate $R$) for the case of matrices $A,B$ with iid Gaussian entries. Algorithmically, we construct a universal quantizer based on nested lattices with an explicit guarantee of approximation error for any (non-random) pair of matrices $A$, $B$ in terms of only Frobenius norms $\|A\|_F, \|B\|_F$ and $\|A^\top B\|_F$. For iid Gaussian matrices our quantizer achieves the lower bound and is, thus, asymptotically optimal. A practical low-complexity version of our quantizer achieves performance quite close to optimal. In information-theoretic terms we derive rate-distortion function for matrix multiplication of iid Gaussian matrices.
Statistical Inference with Limited Memory: A Survey
Dec 23, 2023The problem of statistical inference in its various forms has been the subject of decades-long extensive research. Most of the effort has been focused on characterizing the behavior as a function of the number of available samples, with far less attention given to the effect of memory limitations on performance. Recently, this latter topic has drawn much interest in the engineering and computer science literature. In this survey paper, we attempt to review the state-of-the-art of statistical inference under memory constraints in several canonical problems, including hypothesis testing, parameter estimation, and distribution property testing/estimation. We discuss the main results in this developing field, and by identifying recurrent themes, we extract some fundamental building blocks for algorithmic construction, as well as useful techniques for lower bound derivations.
On the Role of Channel Capacity in Learning Gaussian Mixture Models
Feb 15, 2022This paper studies the sample complexity of learning the $k$ unknown centers of a balanced Gaussian mixture model (GMM) in $\mathbb{R}^d$ with spherical covariance matrix $\sigma^2\mathbf{I}$. In particular, we are interested in the following question: what is the maximal noise level $\sigma^2$, for which the sample complexity is essentially the same as when estimating the centers from labeled measurements? To that end, we restrict attention to a Bayesian formulation of the problem, where the centers are uniformly distributed on the sphere $\sqrt{d}\mathcal{S}^{d-1}$. Our main results characterize the exact noise threshold $\sigma^2$ below which the GMM learning problem, in the large system limit $d,k\to\infty$, is as easy as learning from labeled observations, and above which it is substantially harder. The threshold occurs at $\frac{\log k}{d} = \frac12\log\left( 1+\frac{1}{\sigma^2} \right)$, which is the capacity of the additive white Gaussian noise (AWGN) channel. Thinking of the set of $k$ centers as a code, this noise threshold can be interpreted as the largest noise level for which the error probability of the code over the AWGN channel is small. Previous works on the GMM learning problem have identified the minimum distance between the centers as a key parameter in determining the statistical difficulty of learning the corresponding GMM. While our results are only proved for GMMs whose centers are uniformly distributed over the sphere, they hint that perhaps it is the decoding error probability associated with the center constellation as a channel code that determines the statistical difficulty of learning the corresponding GMM, rather than just the minimum distance.
Blind Modulo Analog-to-Digital Conversion of Vector Processes
Oct 12, 2021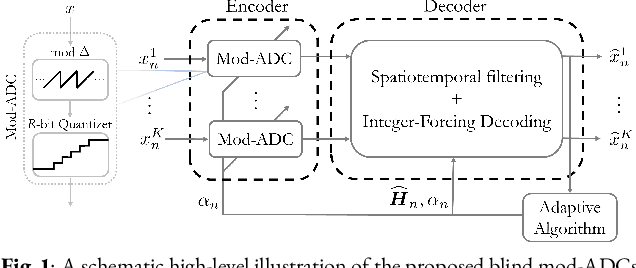
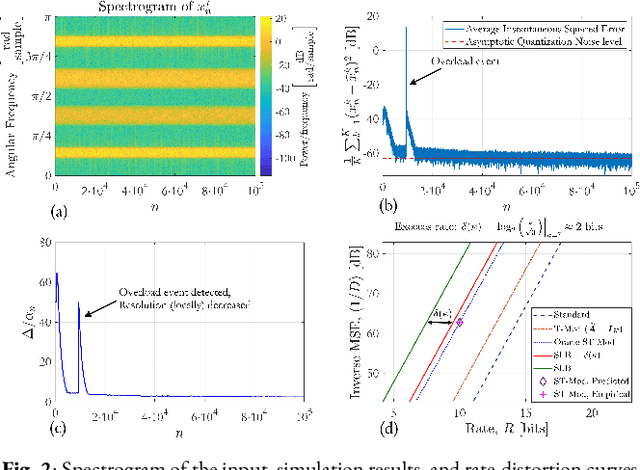
In a growing number of applications, there is a need to digitize a (possibly high) number of correlated signals whose spectral characteristics are challenging for traditional analog-to-digital converters (ADCs). Examples, among others, include multiple-input multiple-output systems where the ADCs must acquire at once several signals at a very wide but sparsely and dynamically occupied bandwidth supporting diverse services. In such scenarios, the resolution requirements can be prohibitively high. As an alternative, the recently proposed modulo-ADC architecture can in principle require dramatically fewer bits in the conversion to obtain the target fidelity, but requires that spatiotemporal information be known and explicitly taken into account by the analog and digital processing in the converter, which is frequently impractical. Building on our recent work, we address this limitation and develop a blind version of the architecture that requires no such knowledge in the converter. In particular, it features an automatic modulo-level adjustment and a fully adaptive modulo-decoding mechanism, allowing it to asymptotically match the characteristics of the unknown input signal. Simulation results demonstrate the successful operation of the proposed algorithm.
Spiked Covariance Estimation from Modulo-Reduced Measurements
Oct 10, 2021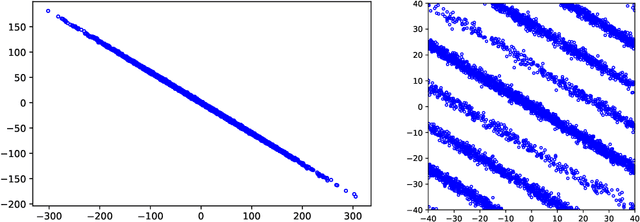
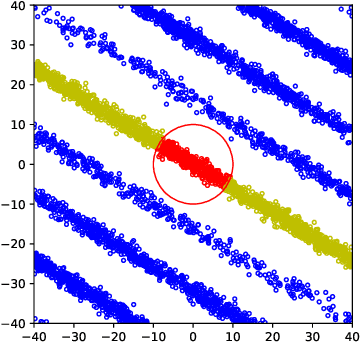

Consider the rank-1 spiked model: $\bf{X}=\sqrt{\nu}\xi \bf{u}+ \bf{Z}$, where $\nu$ is the spike intensity, $\bf{u}\in\mathbb{S}^{k-1}$ is an unknown direction and $\xi\sim \mathcal{N}(0,1),\bf{Z}\sim \mathcal{N}(\bf{0},\bf{I})$. Motivated by recent advances in analog-to-digital conversion, we study the problem of recovering $\bf{u}\in \mathbb{S}^{k-1}$ from $n$ i.i.d. modulo-reduced measurements $\bf{Y}=[\bf{X}]\mod \Delta$, focusing on the high-dimensional regime ($k\gg 1$). We develop and analyze an algorithm that, for most directions $\bf{u}$ and $\nu=\mathrm{poly}(k)$, estimates $\bf{u}$ to high accuracy using $n=\mathrm{poly}(k)$ measurements, provided that $\Delta\gtrsim \sqrt{\log k}$. Up to constants, our algorithm accurately estimates $\bf{u}$ at the smallest possible $\Delta$ that allows (in an information-theoretic sense) to recover $\bf{X}$ from $\bf{Y}$. A key step in our analysis involves estimating the probability that a line segment of length $\approx\sqrt{\nu}$ in a random direction $\bf{u}$ passes near a point in the lattice $\Delta \mathbb{Z}^k$. Numerical experiments show that the developed algorithm performs well even in a non-asymptotic setting.