 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeMeta-Learning with Variational Semantic Memory for Word Sense Disambiguation
Jun 05, 2021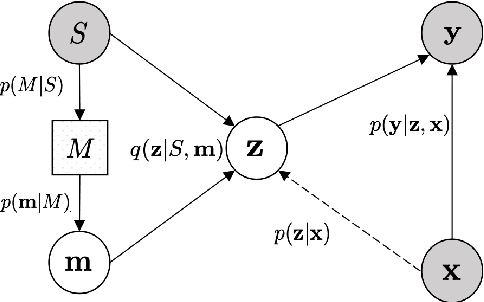
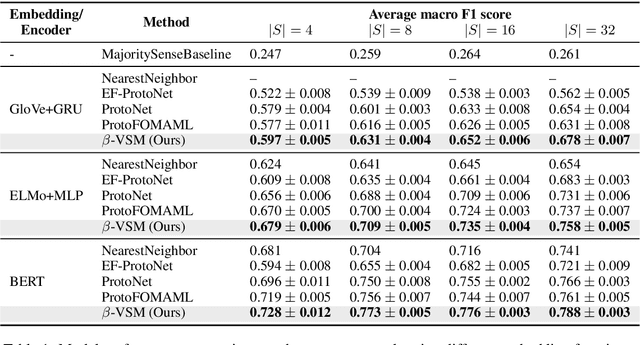
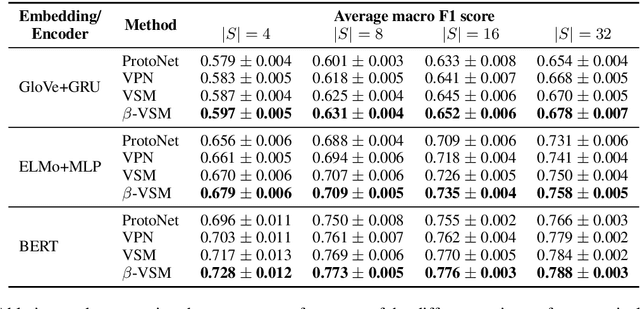
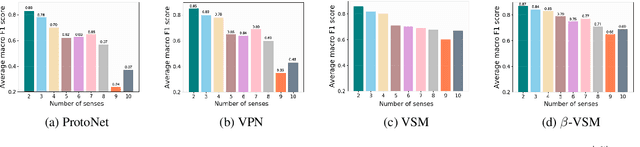
A critical challenge faced by supervised word sense disambiguation (WSD) is the lack of large annotated datasets with sufficient coverage of words in their diversity of senses. This inspired recent research on few-shot WSD using meta-learning. While such work has successfully applied meta-learning to learn new word senses from very few examples, its performance still lags behind its fully supervised counterpart. Aiming to further close this gap, we propose a model of semantic memory for WSD in a meta-learning setting. Semantic memory encapsulates prior experiences seen throughout the lifetime of the model, which aids better generalization in limited data settings. Our model is based on hierarchical variational inference and incorporates an adaptive memory update rule via a hypernetwork. We show our model advances the state of the art in few-shot WSD, supports effective learning in extremely data scarce (e.g. one-shot) scenarios and produces meaning prototypes that capture similar senses of distinct words.
* 15 pages, 5 figures
A Multimodal Framework for the Detection of Hateful Memes
Dec 24, 2020
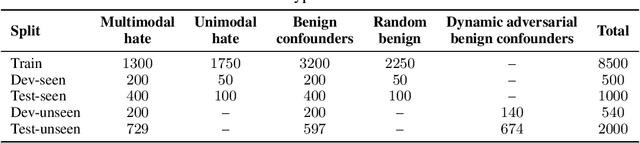
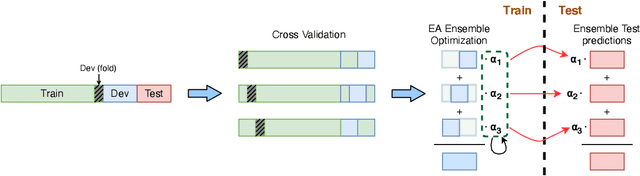
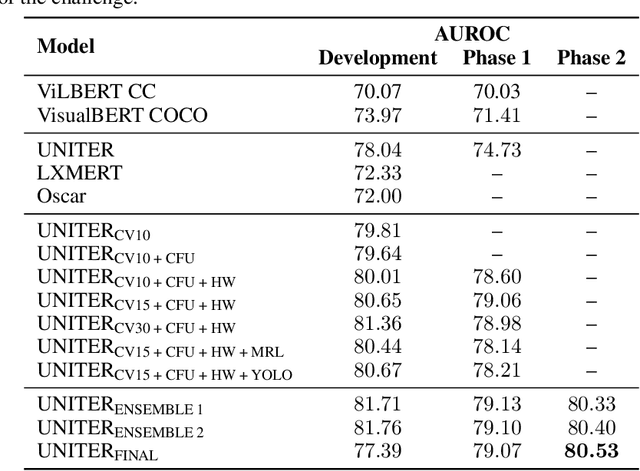
An increasingly common expression of online hate speech is multimodal in nature and comes in the form of memes. Designing systems to automatically detect hateful content is of paramount importance if we are to mitigate its undesirable effects on the society at large. The detection of multimodal hate speech is an intrinsically difficult and open problem: memes convey a message using both images and text and, hence, require multimodal reasoning and joint visual and language understanding. In this work, we seek to advance this line of research and develop a multimodal framework for the detection of hateful memes. We improve the performance of existing multimodal approaches beyond simple fine-tuning and, among others, show the effectiveness of upsampling of contrastive examples to encourage multimodality and ensemble learning based on cross-validation to improve robustness. We furthermore analyze model misclassifications and discuss a number of hypothesis-driven augmentations and their effects on performance, presenting important implications for future research in the field. Our best approach comprises an ensemble of UNITER-based models and achieves an AUROC score of 80.53, placing us 4th on phase 2 of the 2020 Hateful Memes Challenge organized by Facebook.
Meta-Learning with Sparse Experience Replay for Lifelong Language Learning
Sep 10, 2020
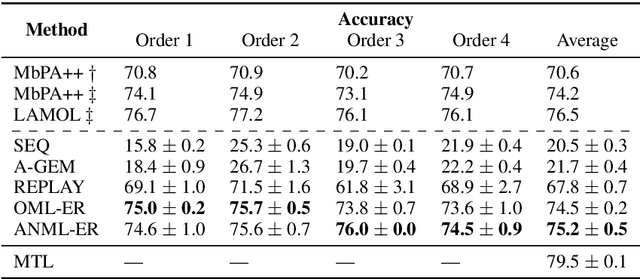
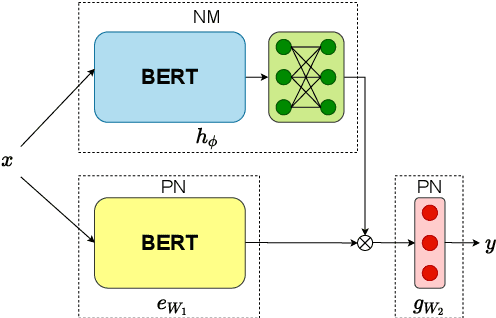
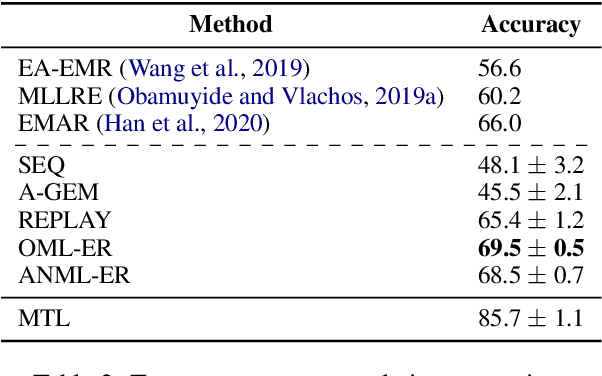
Lifelong learning requires models that can continuously learn from sequential streams of data without suffering catastrophic forgetting due to shifts in data distributions. Deep learning models have thrived in the non-sequential learning paradigm; however, when used to learn a sequence of tasks, they fail to retain past knowledge and learn incrementally. We propose a novel approach to lifelong learning of language tasks based on meta-learning with sparse experience replay that directly optimizes to prevent forgetting. We show that under the realistic setting of performing a single pass on a stream of tasks and without any task identifiers, our method obtains state-of-the-art results on lifelong text classification and relation extraction. We analyze the effectiveness of our approach and further demonstrate its low computational and space complexity.
Learning to Learn to Disambiguate: Meta-Learning for Few-Shot Word Sense Disambiguation
Apr 29, 2020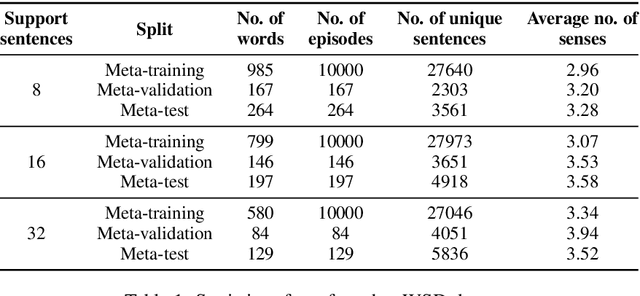
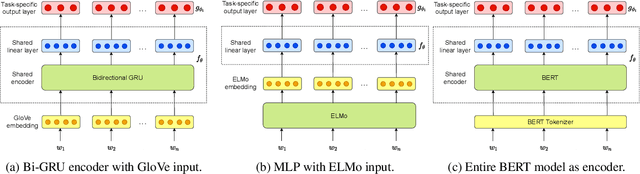
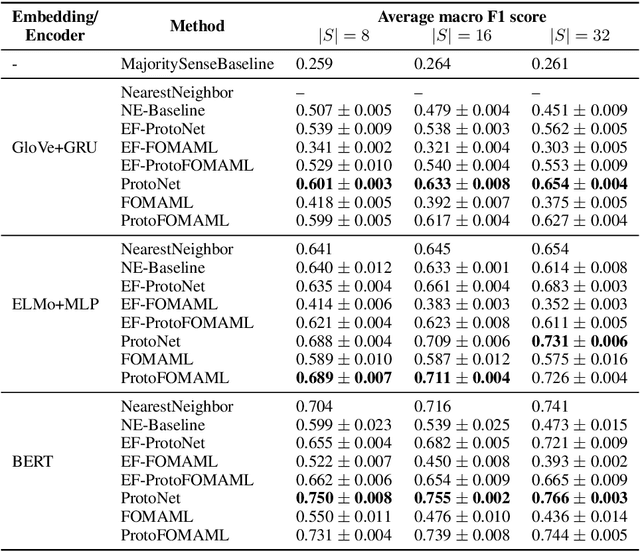
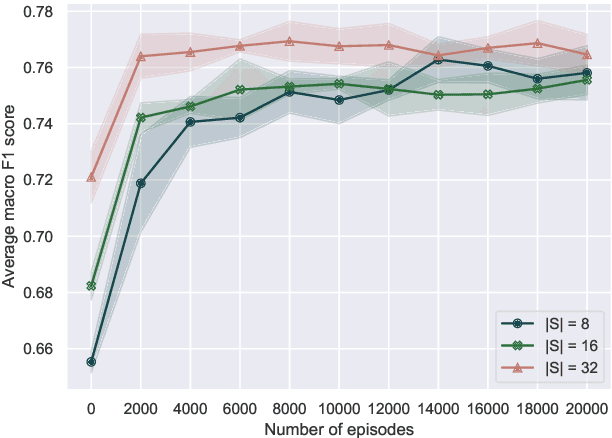
Deep learning methods typically rely on large amounts of annotated data and do not generalize well to few-shot learning problems where labeled data is scarce. In contrast to human intelligence, such approaches lack versatility and struggle to learn and adapt quickly to new tasks. Meta-learning addresses this problem by training on a large number of related tasks such that new tasks can be learned quickly using a small number of examples. We propose a meta-learning framework for few-shot word sense disambiguation (WSD), where the goal is to disambiguate unseen words from only a few labeled instances. Meta-learning approaches have so far been typically tested in an $N$-way, $K$-shot classification setting where each task has $N$ classes with $K$ examples per class. Owing to its nature, WSD deviates from this controlled setup and requires the models to handle a large number of highly unbalanced classes. We extend several popular meta-learning approaches to this scenario, and analyze their strengths and weaknesses in this new challenging setting.