 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeA Multimodal Framework for the Detection of Hateful Memes
Dec 24, 2020
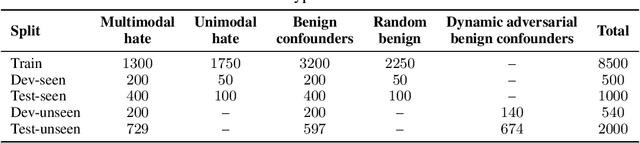
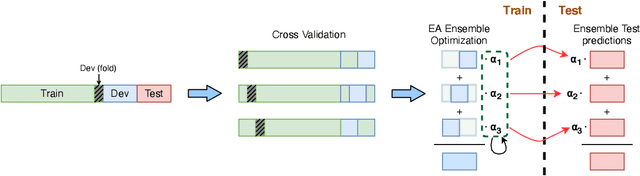
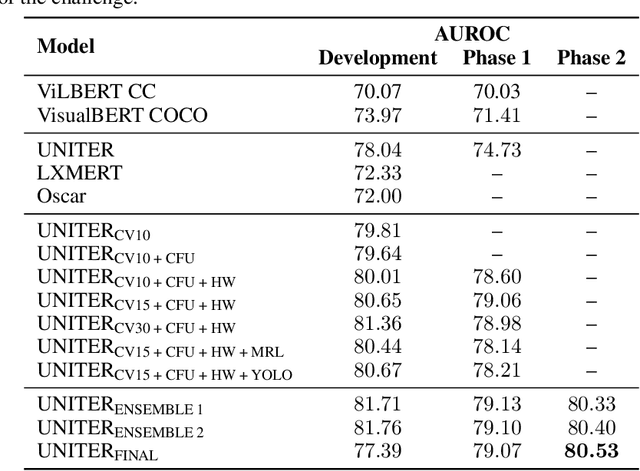
An increasingly common expression of online hate speech is multimodal in nature and comes in the form of memes. Designing systems to automatically detect hateful content is of paramount importance if we are to mitigate its undesirable effects on the society at large. The detection of multimodal hate speech is an intrinsically difficult and open problem: memes convey a message using both images and text and, hence, require multimodal reasoning and joint visual and language understanding. In this work, we seek to advance this line of research and develop a multimodal framework for the detection of hateful memes. We improve the performance of existing multimodal approaches beyond simple fine-tuning and, among others, show the effectiveness of upsampling of contrastive examples to encourage multimodality and ensemble learning based on cross-validation to improve robustness. We furthermore analyze model misclassifications and discuss a number of hypothesis-driven augmentations and their effects on performance, presenting important implications for future research in the field. Our best approach comprises an ensemble of UNITER-based models and achieves an AUROC score of 80.53, placing us 4th on phase 2 of the 2020 Hateful Memes Challenge organized by Facebook.