 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeUnderstanding and Analyzing Model Robustness and Knowledge-Transfer in Multilingual Neural Machine Translation using TX-Ray
Dec 18, 2024Neural networks have demonstrated significant advancements in Neural Machine Translation (NMT) compared to conventional phrase-based approaches. However, Multilingual Neural Machine Translation (MNMT) in extremely low-resource settings remains underexplored. This research investigates how knowledge transfer across languages can enhance MNMT in such scenarios. Using the Tatoeba translation challenge dataset from Helsinki NLP, we perform English-German, English-French, and English-Spanish translations, leveraging minimal parallel data to establish cross-lingual mappings. Unlike conventional methods relying on extensive pre-training for specific language pairs, we pre-train our model on English-English translations, setting English as the source language for all tasks. The model is fine-tuned on target language pairs using joint multi-task and sequential transfer learning strategies. Our work addresses three key questions: (1) How can knowledge transfer across languages improve MNMT in extremely low-resource scenarios? (2) How does pruning neuron knowledge affect model generalization, robustness, and catastrophic forgetting? (3) How can TX-Ray interpret and quantify knowledge transfer in trained models? Evaluation using BLEU-4 scores demonstrates that sequential transfer learning outperforms baselines on a 40k parallel sentence corpus, showcasing its efficacy. However, pruning neuron knowledge degrades performance, increases catastrophic forgetting, and fails to improve robustness or generalization. Our findings provide valuable insights into the potential and limitations of knowledge transfer and pruning in MNMT for extremely low-resource settings.
VendorLink: An NLP approach for Identifying & Linking Vendor Migrants & Potential Aliases on Darknet Markets
May 04, 2023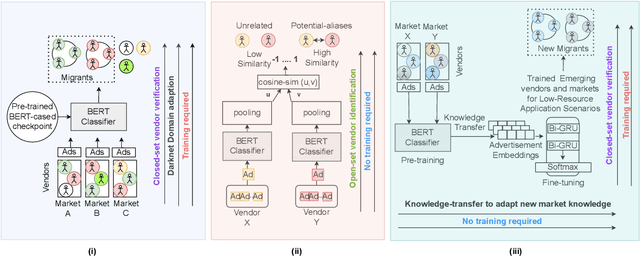
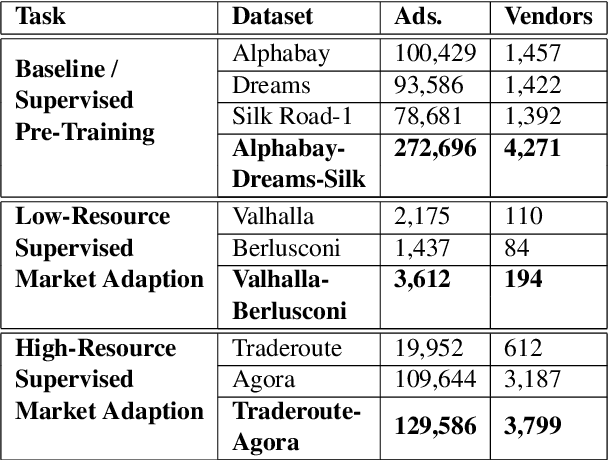
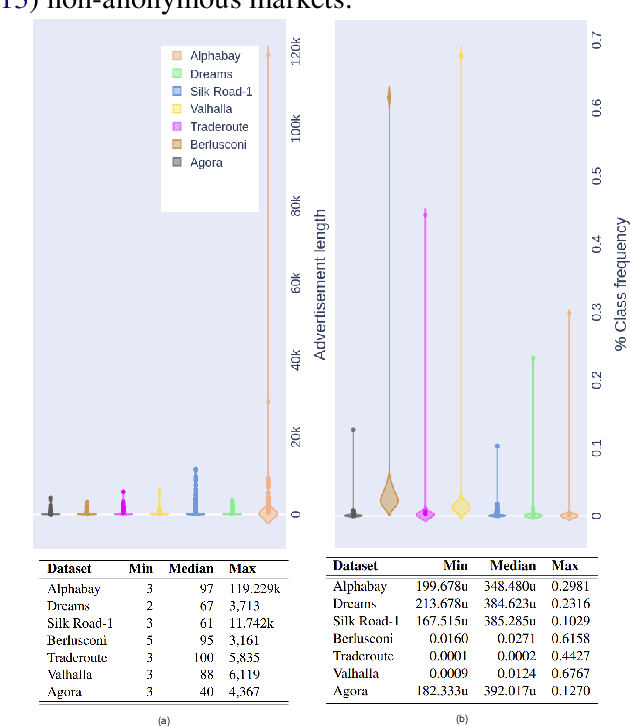
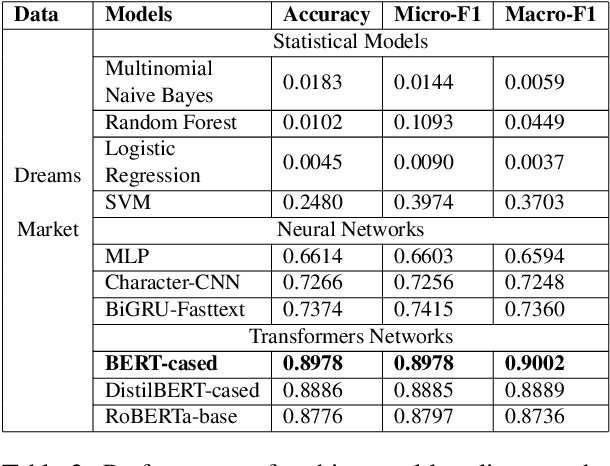
The anonymity on the Darknet allows vendors to stay undetected by using multiple vendor aliases or frequently migrating between markets. Consequently, illegal markets and their connections are challenging to uncover on the Darknet. To identify relationships between illegal markets and their vendors, we propose VendorLink, an NLP-based approach that examines writing patterns to verify, identify, and link unique vendor accounts across text advertisements (ads) on seven public Darknet markets. In contrast to existing literature, VendorLink utilizes the strength of supervised pre-training to perform closed-set vendor verification, open-set vendor identification, and low-resource market adaption tasks. Through VendorLink, we uncover (i) 15 migrants and 71 potential aliases in the Alphabay-Dreams-Silk dataset, (ii) 17 migrants and 3 potential aliases in the Valhalla-Berlusconi dataset, and (iii) 75 migrants and 10 potential aliases in the Traderoute-Agora dataset. Altogether, our approach can help Law Enforcement Agencies (LEA) make more informed decisions by verifying and identifying migrating vendors and their potential aliases on existing and Low-Resource (LR) emerging Darknet markets.
Neighborhood Contrastive Learning for Scientific Document Representations with Citation Embeddings
Feb 14, 2022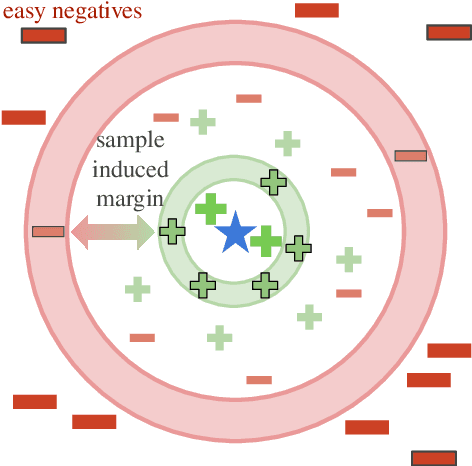
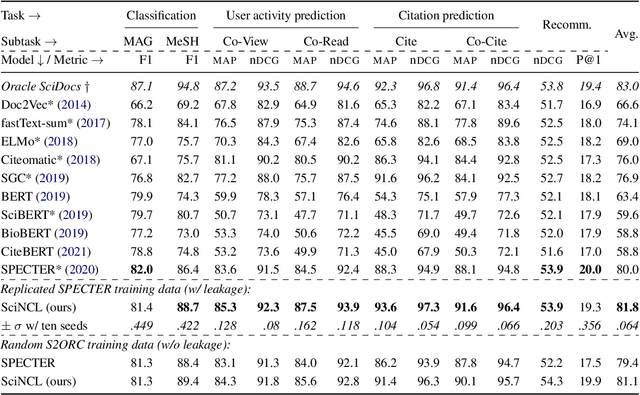
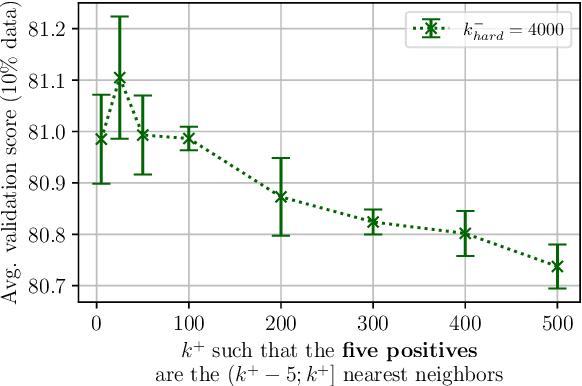
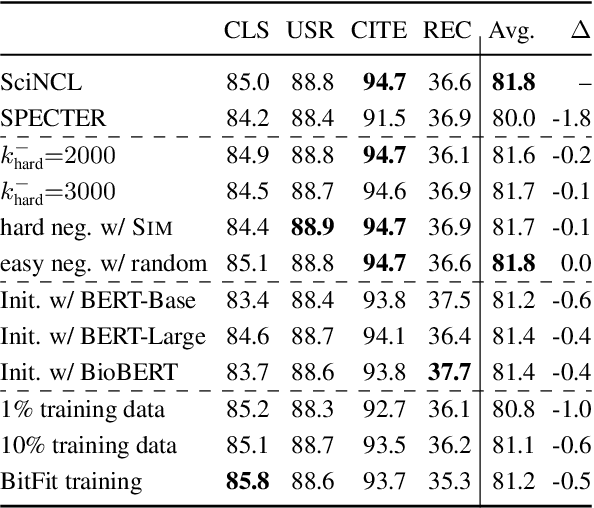
Learning scientific document representations can be substantially improved through contrastive learning objectives, where the challenge lies in creating positive and negative training samples that encode the desired similarity semantics. Prior work relies on discrete citation relations to generate contrast samples. However, discrete citations enforce a hard cut-off to similarity. This is counter-intuitive to similarity-based learning, and ignores that scientific papers can be very similar despite lacking a direct citation - a core problem of finding related research. Instead, we use controlled nearest neighbor sampling over citation graph embeddings for contrastive learning. This control allows us to learn continuous similarity, to sample hard-to-learn negatives and positives, and also to avoid collisions between negative and positive samples by controlling the sampling margin between them. The resulting method SciNCL outperforms the state-of-the-art on the SciDocs benchmark. Furthermore, we demonstrate that it can train (or tune) models sample-efficiently, and that it can be combined with recent training-efficient methods. Perhaps surprisingly, even training a general-domain language model this way outperforms baselines pretrained in-domain.
A Primer on Contrastive Pretraining in Language Processing: Methods, Lessons Learned and Perspectives
Feb 25, 2021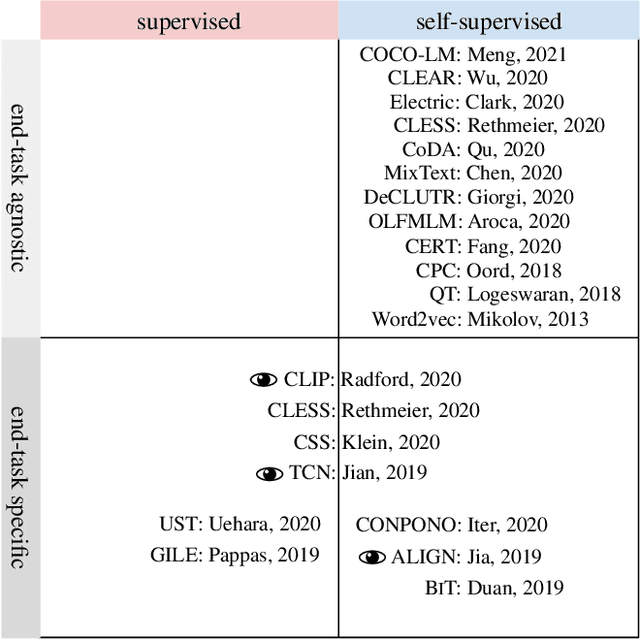
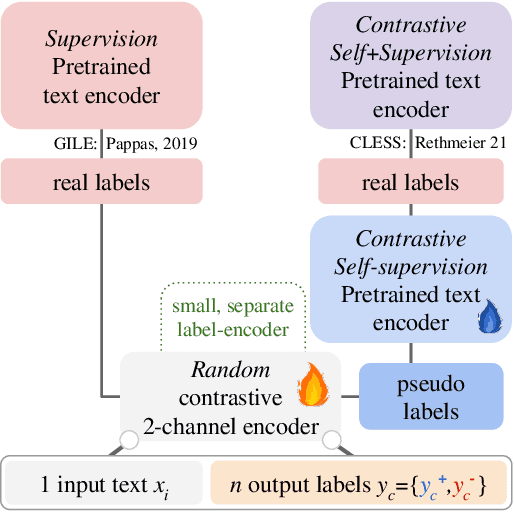
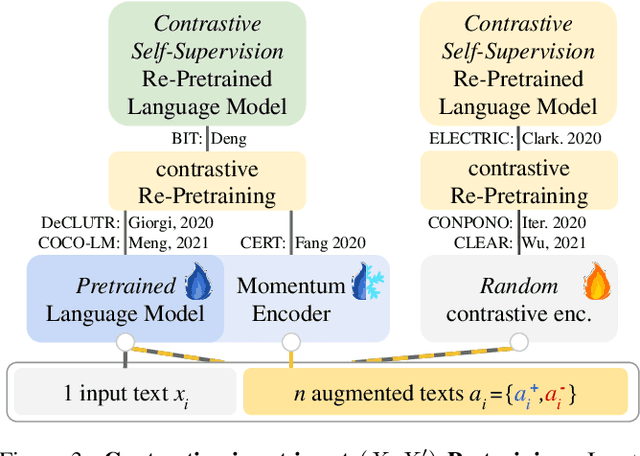
Modern natural language processing (NLP) methods employ self-supervised pretraining objectives such as masked language modeling to boost the performance of various application tasks. These pretraining methods are frequently extended with recurrence, adversarial or linguistic property masking, and more recently with contrastive learning objectives. Contrastive self-supervised training objectives enabled recent successes in image representation pretraining by learning to contrast input-input pairs of augmented images as either similar or dissimilar. However, in NLP, automated creation of text input augmentations is still very challenging because a single token can invert the meaning of a sentence. For this reason, some contrastive NLP pretraining methods contrast over input-label pairs, rather than over input-input pairs, using methods from Metric Learning and Energy Based Models. In this survey, we summarize recent self-supervised and supervised contrastive NLP pretraining methods and describe where they are used to improve language modeling, few or zero-shot learning, pretraining data-efficiency and specific NLP end-tasks. We introduce key contrastive learning concepts with lessons learned from prior research and structure works by applications and cross-field relations. Finally, we point to open challenges and future directions for contrastive NLP to encourage bringing contrastive NLP pretraining closer to recent successes in image representation pretraining.
Long-Tail Zero and Few-Shot Learning via Contrastive Pretraining on and for Small Data
Oct 21, 2020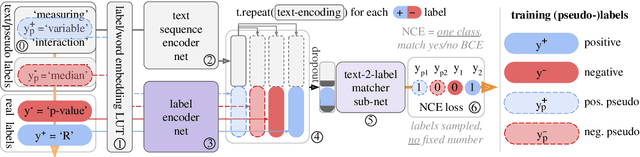

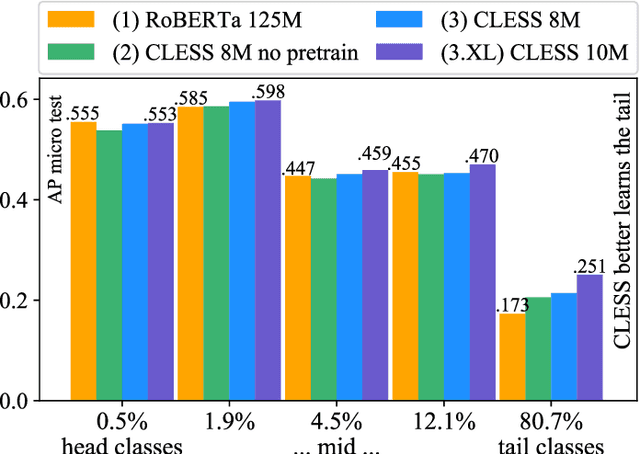
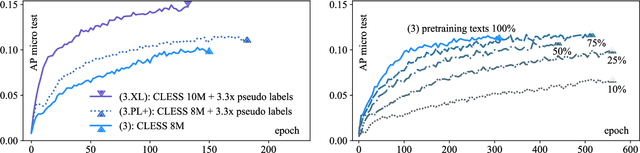
For natural language processing (NLP) tasks such as sentiment or topic classification, currently prevailing approaches heavily rely on pretraining large self-supervised models on massive external data resources. However, this methodology is being critiqued for: exceptional compute and pretraining data requirements; diminishing returns on both large and small datasets; and importantly, favourable evaluation settings that overestimate performance differences. The core belief behind current methodology, coined `the bitter lesson' by R. Sutton, is that `compute scale-up beats data and compute-efficient algorithms', neglecting that progress in compute hardware scale-up is based almost entirely on the miniaturisation of resource consumption. We thus approach pretraining from a miniaturisation perspective, such as not to require massive external data sources and models, or learned translations from continuous input embeddings to discrete labels. To minimise overly favourable evaluation, we examine learning on a long-tailed, low-resource, multi-label text classification dataset with noisy, highly sparse labels and many rare concepts. To this end, we propose a novel `dataset-internal' contrastive autoencoding approach to self-supervised pretraining and demonstrate marked improvements in zero-shot, few-shot and solely supervised learning performance; even under an unfavorable low-resource scenario, and without defaulting to large-scale external datasets for self-supervision. We also find empirical evidence that zero and few-shot learning markedly benefit from adding more `dataset-internal', self-supervised training signals, which is of practical importance when retrieving or computing on large external sources of such signals is infeasible.
TX-Ray: Quantifying and Explaining Model-Knowledge Transfer in (Un-)Supervised NLP
Dec 02, 2019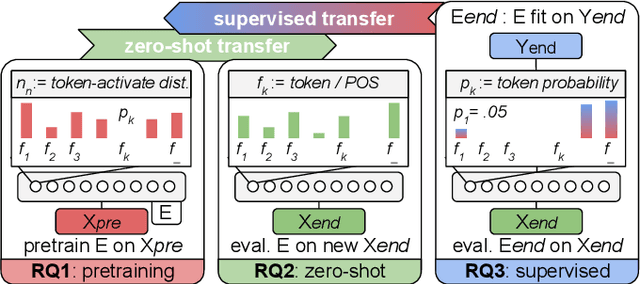

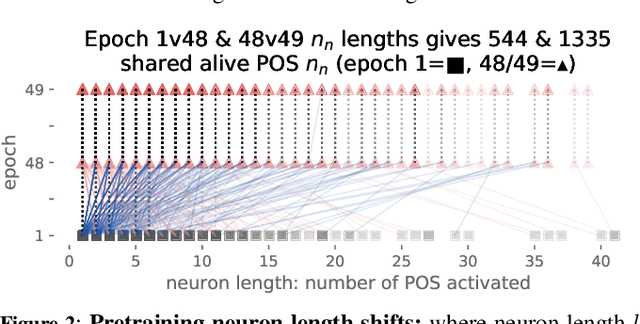
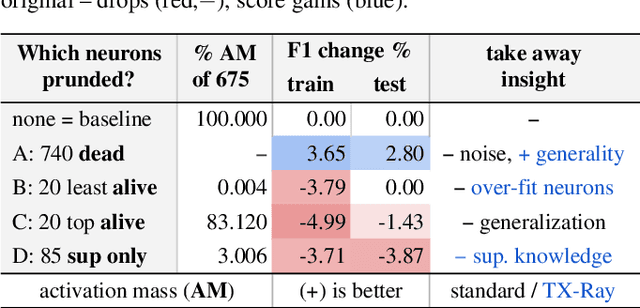
While state-of-the-art NLP explainability (XAI) methods focus on supervised, per-instance end or diagnostic probing task evaluation[4, 2, 10], this is insufficient to interpret and quantify model knowledge transfer during (un-) supervised training. By instead expressing each neuron as an interpretable token-activation distribution collected over many instances, one can quantify and guide visual exploration of neuron-knowledge change between model training stages to analyze transfer beyond probing tasks and the per-instance level. This allows one to analyze: (RQ1) how neurons abstract knowledge during unsupervised pretraining; (RQ2) how pretrained neurons zero-shot transfer knowledge to new domain data; and (RQ3) how supervised tasks reorder pretrained neuron knowledge abstractions. Since the meaningfulness of XAI methods is hard to quantify [11, 4], we analyze three example learning setups (RQ1-3) to empirically verify that our method (TX-Ray): identifies transfer (ir-)relevant neurons for pruning (RQ3), and that its transfer metrics coincide with traditional measures like perplexity (RQ1). We also find, that TX-Ray guided pruning of supervision (ir-)relevant neuron-knowledge (RQ3) can identify `lottery ticket'-like [9, 40] neurons that drive model performance and robustness. Upon inspecting pruned neurons, we find that task-relevant neuron-knowledge (`tickets'), appear (over-)fit, while task-irrelevant neurons lower overfitting, i.e. TX-Ray identifies neurons that generalize, transfer or specialize model-knowledge [25]. Finally, through RQ1-3, we find that TX-Ray helps to explore and quantify dynamics of (continual) knowledge transfer and that it can shed light on neuron-knowledge specialization and generalization, to complement (costly) supervised probing task procurement and established `summary' statistics like perplexity, ROC or F scores.