 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeTX-Ray: Quantifying and Explaining Model-Knowledge Transfer in (Un-)Supervised NLP
Paper and Code
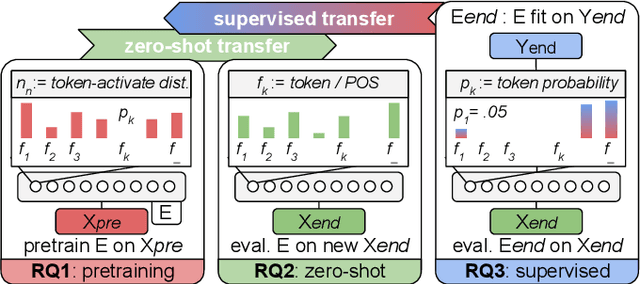

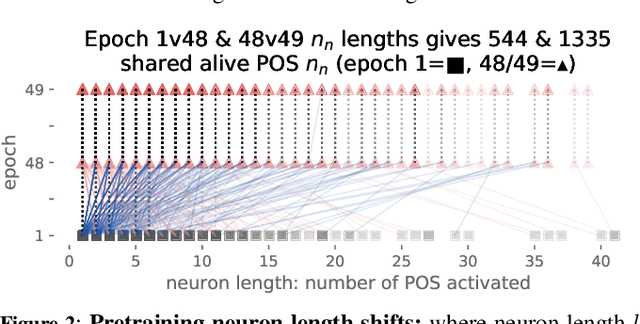
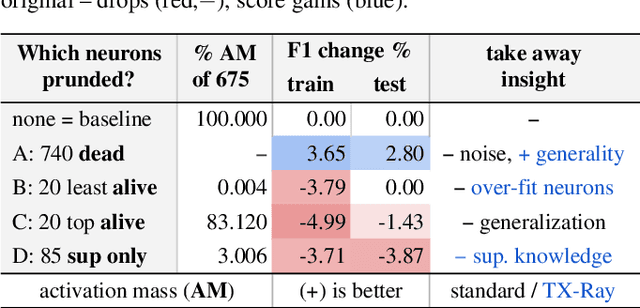
While state-of-the-art NLP explainability (XAI) methods focus on supervised, per-instance end or diagnostic probing task evaluation[4, 2, 10], this is insufficient to interpret and quantify model knowledge transfer during (un-) supervised training. By instead expressing each neuron as an interpretable token-activation distribution collected over many instances, one can quantify and guide visual exploration of neuron-knowledge change between model training stages to analyze transfer beyond probing tasks and the per-instance level. This allows one to analyze: (RQ1) how neurons abstract knowledge during unsupervised pretraining; (RQ2) how pretrained neurons zero-shot transfer knowledge to new domain data; and (RQ3) how supervised tasks reorder pretrained neuron knowledge abstractions. Since the meaningfulness of XAI methods is hard to quantify [11, 4], we analyze three example learning setups (RQ1-3) to empirically verify that our method (TX-Ray): identifies transfer (ir-)relevant neurons for pruning (RQ3), and that its transfer metrics coincide with traditional measures like perplexity (RQ1). We also find, that TX-Ray guided pruning of supervision (ir-)relevant neuron-knowledge (RQ3) can identify `lottery ticket'-like [9, 40] neurons that drive model performance and robustness. Upon inspecting pruned neurons, we find that task-relevant neuron-knowledge (`tickets'), appear (over-)fit, while task-irrelevant neurons lower overfitting, i.e. TX-Ray identifies neurons that generalize, transfer or specialize model-knowledge [25]. Finally, through RQ1-3, we find that TX-Ray helps to explore and quantify dynamics of (continual) knowledge transfer and that it can shed light on neuron-knowledge specialization and generalization, to complement (costly) supervised probing task procurement and established `summary' statistics like perplexity, ROC or F scores.