 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeLong-Tail Zero and Few-Shot Learning via Contrastive Pretraining on and for Small Data
Paper and Code
Oct 21, 2020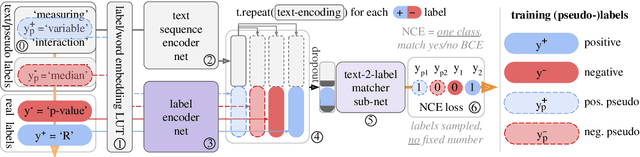

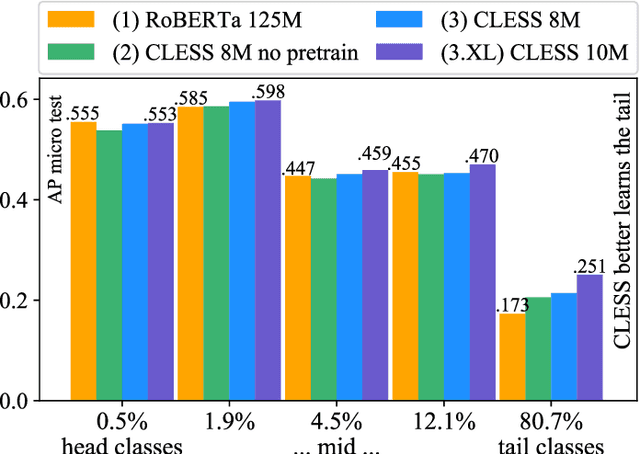
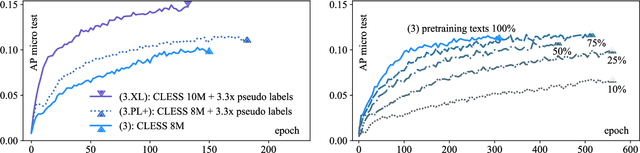
For natural language processing (NLP) tasks such as sentiment or topic classification, currently prevailing approaches heavily rely on pretraining large self-supervised models on massive external data resources. However, this methodology is being critiqued for: exceptional compute and pretraining data requirements; diminishing returns on both large and small datasets; and importantly, favourable evaluation settings that overestimate performance differences. The core belief behind current methodology, coined `the bitter lesson' by R. Sutton, is that `compute scale-up beats data and compute-efficient algorithms', neglecting that progress in compute hardware scale-up is based almost entirely on the miniaturisation of resource consumption. We thus approach pretraining from a miniaturisation perspective, such as not to require massive external data sources and models, or learned translations from continuous input embeddings to discrete labels. To minimise overly favourable evaluation, we examine learning on a long-tailed, low-resource, multi-label text classification dataset with noisy, highly sparse labels and many rare concepts. To this end, we propose a novel `dataset-internal' contrastive autoencoding approach to self-supervised pretraining and demonstrate marked improvements in zero-shot, few-shot and solely supervised learning performance; even under an unfavorable low-resource scenario, and without defaulting to large-scale external datasets for self-supervision. We also find empirical evidence that zero and few-shot learning markedly benefit from adding more `dataset-internal', self-supervised training signals, which is of practical importance when retrieving or computing on large external sources of such signals is infeasible.