 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeMONAI: An open-source framework for deep learning in healthcare
Nov 04, 2022



Artificial Intelligence (AI) is having a tremendous impact across most areas of science. Applications of AI in healthcare have the potential to improve our ability to detect, diagnose, prognose, and intervene on human disease. For AI models to be used clinically, they need to be made safe, reproducible and robust, and the underlying software framework must be aware of the particularities (e.g. geometry, physiology, physics) of medical data being processed. This work introduces MONAI, a freely available, community-supported, and consortium-led PyTorch-based framework for deep learning in healthcare. MONAI extends PyTorch to support medical data, with a particular focus on imaging, and provide purpose-specific AI model architectures, transformations and utilities that streamline the development and deployment of medical AI models. MONAI follows best practices for software-development, providing an easy-to-use, robust, well-documented, and well-tested software framework. MONAI preserves the simple, additive, and compositional approach of its underlying PyTorch libraries. MONAI is being used by and receiving contributions from research, clinical and industrial teams from around the world, who are pursuing applications spanning nearly every aspect of healthcare.
Test-Time Training Can Close the Natural Distribution Shift Performance Gap in Deep Learning Based Compressed Sensing
Apr 14, 2022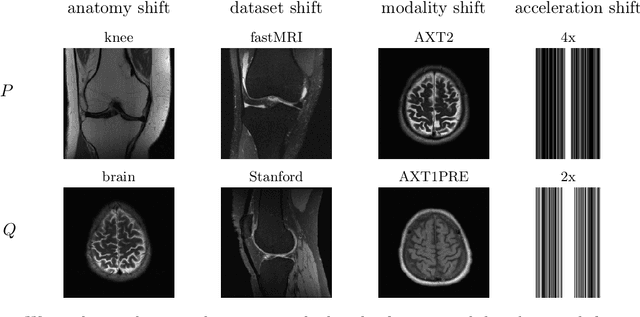
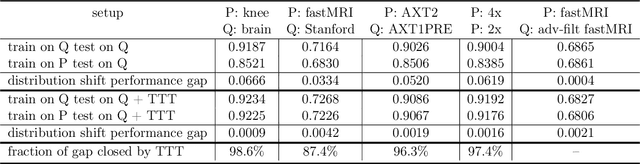

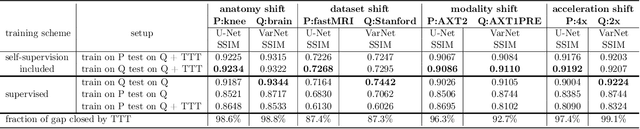
Deep learning based image reconstruction methods outperform traditional methods in accuracy and runtime. However, neural networks suffer from a performance drop when applied to images from a different distribution than the training images. For example, a model trained for reconstructing knees in accelerated magnetic resonance imaging (MRI) does not reconstruct brains well, even though the same network trained on brains reconstructs brains perfectly well. Thus there is a distribution shift performance gap for a given neural network, defined as the difference in performance when training on a distribution $P$ and training on another distribution $Q$, and evaluating both models on $Q$. In this work, we propose a domain adaptation method for deep learning based compressive sensing that relies on self-supervision during training paired with test-time training at inference. We show that for four natural distribution shifts, this method essentially closes the distribution shift performance gap for state-of-the-art architectures for accelerated MRI.
Measuring Robustness in Deep Learning Based Compressive Sensing
Feb 11, 2021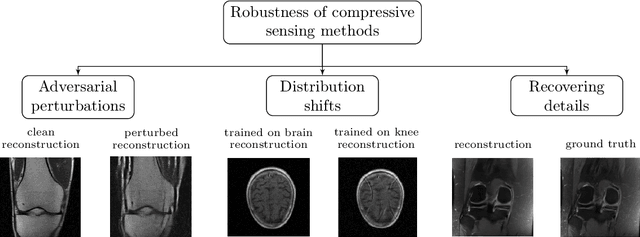
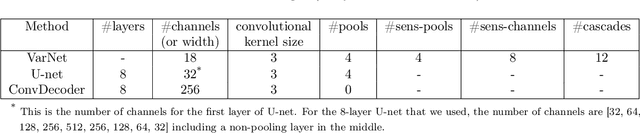
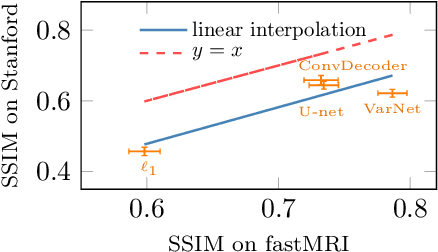
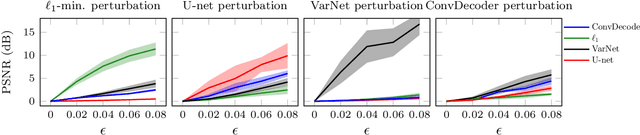
Deep neural networks give state-of-the-art performance for inverse problems such as reconstructing images from few and noisy measurements, a problem arising in accelerated magnetic resonance imaging (MRI). However, recent works have raised concerns that deep-learning-based image reconstruction methods are sensitive to perturbations and are less robust than traditional methods: Neural networks (i) may be sensitive to small, yet adversarially-selected perturbations, (ii) may perform poorly under distribution shifts, and (iii) may fail to recover small but important features in the image. In order to understand whether neural networks are sensitive to such perturbations, in this work, we measure the robustness of different approaches for image reconstruction including trained neural networks, un-trained networks, and traditional sparsity-based methods. We find, contrary to prior works, that both trained and un-trained methods are vulnerable to adversarial perturbations. Moreover, we find that both trained and un-trained methods tuned for a particular dataset suffer very similarly from distribution shifts. Finally, we demonstrate that an image reconstruction method that achieves higher reconstruction accuracy, also performs better in terms of accurately recovering fine details. Thus, the current state-of-the-art deep-learning-based image reconstruction methods enable a performance gain over traditional methods without compromising robustness.
Can Un-trained Neural Networks Compete with Trained Neural Networks at Image Reconstruction?
Jul 06, 2020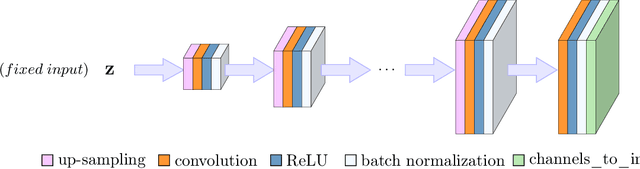
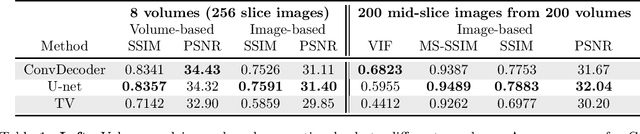

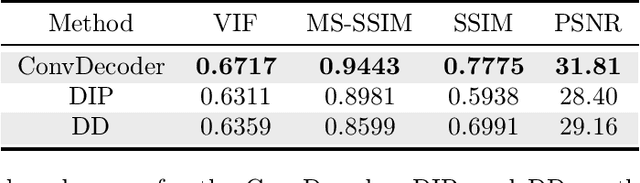
Convolutional Neural Networks (CNNs) are highly effective for image reconstruction problems. Typically, CNNs are trained on large amounts of training images. Recently, however, un-trained neural networks such as the Deep Image Prior and Deep Decoder have achieved excellent image reconstruction performance for standard image reconstruction problems such as image denoising and image inpainting, without using any training data. This success raises the question whether un-trained neural networks can compete with trained ones for practical imaging tasks. To address this question, we consider accelerated magnetic resonance imaging (MRI), an important medical imaging problem, which has received significant attention from the deep-learning community, and for which a dedicated training set exists. We study and optimize un-trained architectures, and as a result, propose a variation of the architectures of the deep image prior and deep decoder. We show that the resulting convolutional decoder out-performs other un-trained methods and---most importantly---achieves on-par performance with a standard trained baseline, the U-net, on the FastMRI dataset, a new dataset for benchmarking deep learning based reconstruction methods. Besides achieving on-par reconstruction performance relative to trained methods, we demonstrate that a key advantage over trained methods is robustness to out-of-distribution examples.