 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeCausal Pre-training Under the Fairness Lens: An Empirical Study of TabPFN
Jan 27, 2026Foundation models for tabular data, such as the Tabular Prior-data Fitted Network (TabPFN), are pre-trained on a massive number of synthetic datasets generated by structural causal models (SCM). They leverage in-context learning to offer high predictive accuracy in real-world tasks. However, the fairness properties of these foundational models, which incorporate ideas from causal reasoning during pre-training, remain underexplored. In this work, we conduct a comprehensive empirical evaluation of TabPFN and its fine-tuned variants, assessing predictive performance, fairness, and robustness across varying dataset sizes and distributional shifts. Our results reveal that while TabPFN achieves stronger predictive accuracy compared to baselines and exhibits robustness to spurious correlations, improvements in fairness are moderate and inconsistent, particularly under missing-not-at-random (MNAR) covariate shifts. These findings suggest that the causal pre-training in TabPFN is helpful but insufficient for algorithmic fairness, highlighting implications for deploying TabPFN (and similar) models in practice and the need for further fairness interventions.
Towards Privacy-Preserving Data-Driven Education: The Potential of Federated Learning
Mar 16, 2025

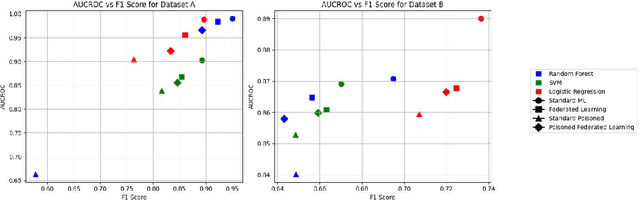

The increasing adoption of data-driven applications in education such as in learning analytics and AI in education has raised significant privacy and data protection concerns. While these challenges have been widely discussed in previous works, there are still limited practical solutions. Federated learning has recently been discoursed as a promising privacy-preserving technique, yet its application in education remains scarce. This paper presents an experimental evaluation of federated learning for educational data prediction, comparing its performance to traditional non-federated approaches. Our findings indicate that federated learning achieves comparable predictive accuracy. Furthermore, under adversarial attacks, federated learning demonstrates greater resilience compared to non-federated settings. We summarise that our results reinforce the value of federated learning as a potential approach for balancing predictive performance and privacy in educational contexts.
A Showdown of ChatGPT vs DeepSeek in Solving Programming Tasks
Mar 16, 2025The advancement of large language models (LLMs) has created a competitive landscape for AI-assisted programming tools. This study evaluates two leading models: ChatGPT 03-mini and DeepSeek-R1 on their ability to solve competitive programming tasks from Codeforces. Using 29 programming tasks of three levels of easy, medium, and hard difficulty, we assessed the outcome of both models by their accepted solutions, memory efficiency, and runtime performance. Our results indicate that while both models perform similarly on easy tasks, ChatGPT outperforms DeepSeek-R1 on medium-difficulty tasks, achieving a 54.5% success rate compared to DeepSeek 18.1%. Both models struggled with hard tasks, thus highlighting some ongoing challenges LLMs face in handling highly complex programming problems. These findings highlight key differences in both model capabilities and their computational power, offering valuable insights for developers and researchers working to advance AI-driven programming tools.
Can Synthetic Data be Fair and Private? A Comparative Study of Synthetic Data Generation and Fairness Algorithms
Jan 03, 2025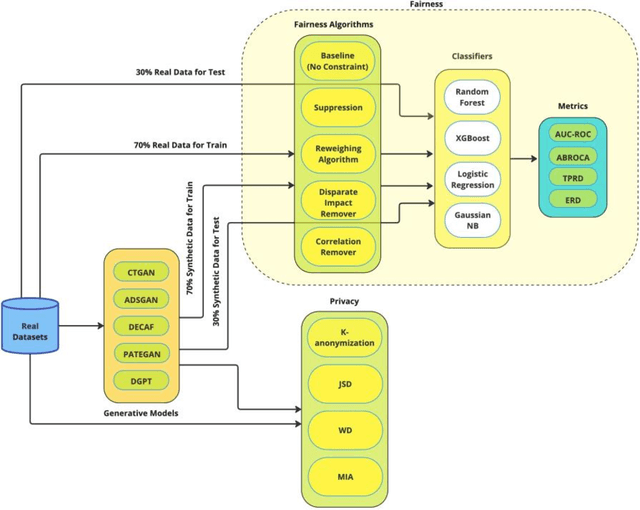
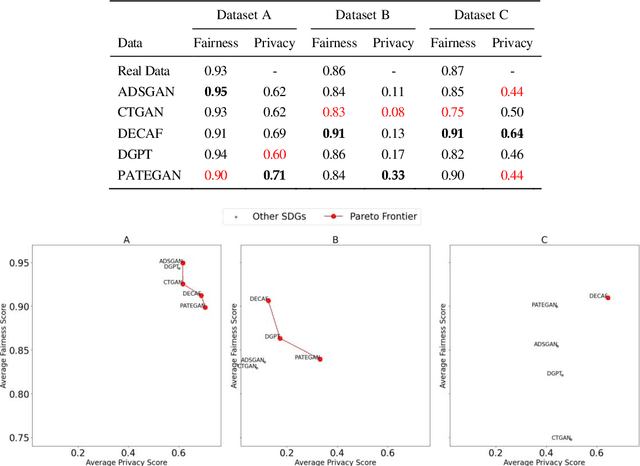
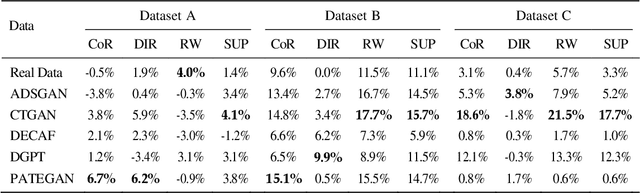
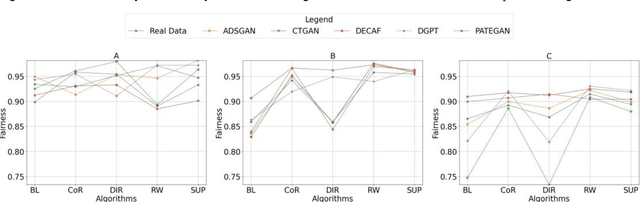
The increasing use of machine learning in learning analytics (LA) has raised significant concerns around algorithmic fairness and privacy. Synthetic data has emerged as a dual-purpose tool, enhancing privacy and improving fairness in LA models. However, prior research suggests an inverse relationship between fairness and privacy, making it challenging to optimize both. This study investigates which synthetic data generators can best balance privacy and fairness, and whether pre-processing fairness algorithms, typically applied to real datasets, are effective on synthetic data. Our results highlight that the DEbiasing CAusal Fairness (DECAF) algorithm achieves the best balance between privacy and fairness. However, DECAF suffers in utility, as reflected in its predictive accuracy. Notably, we found that applying pre-processing fairness algorithms to synthetic data improves fairness even more than when applied to real data. These findings suggest that combining synthetic data generation with fairness pre-processing offers a promising approach to creating fairer LA models.
Creating Artificial Students that Never Existed: Leveraging Large Language Models and CTGANs for Synthetic Data Generation
Jan 03, 2025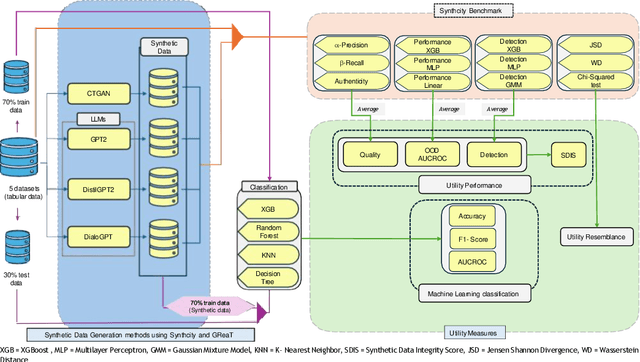

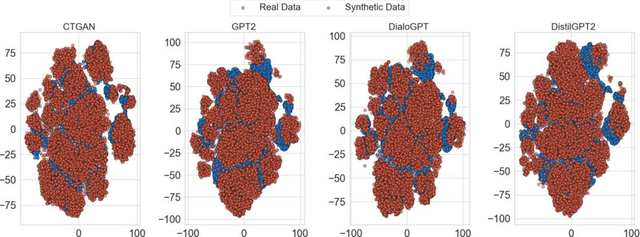
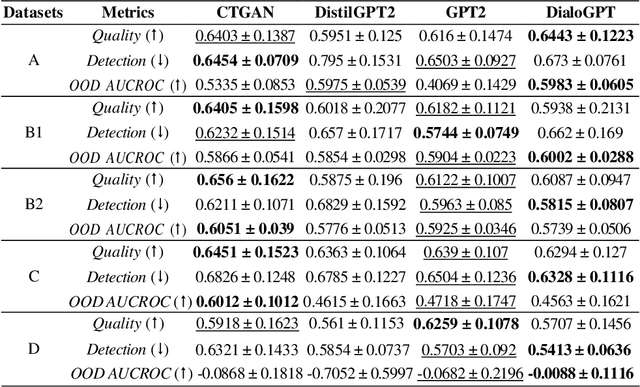
In this study, we explore the growing potential of AI and deep learning technologies, particularly Generative Adversarial Networks (GANs) and Large Language Models (LLMs), for generating synthetic tabular data. Access to quality students data is critical for advancing learning analytics, but privacy concerns and stricter data protection regulations worldwide limit their availability and usage. Synthetic data offers a promising alternative. We investigate whether synthetic data can be leveraged to create artificial students for serving learning analytics models. Using the popular GAN model CTGAN and three LLMs- GPT2, DistilGPT2, and DialoGPT, we generate synthetic tabular student data. Our results demonstrate the strong potential of these methods to produce high-quality synthetic datasets that resemble real students data. To validate our findings, we apply a comprehensive set of utility evaluation metrics to assess the statistical and predictive performance of the synthetic data and compare the different generator models used, specially the performance of LLMs. Our study aims to provide the learning analytics community with valuable insights into the use of synthetic data, laying the groundwork for expanding the field methodological toolbox with new innovative approaches for learning analytics data generation.
Probabilistic transfer learning methodology to expedite high fidelity simulation of reactive flows
May 17, 2024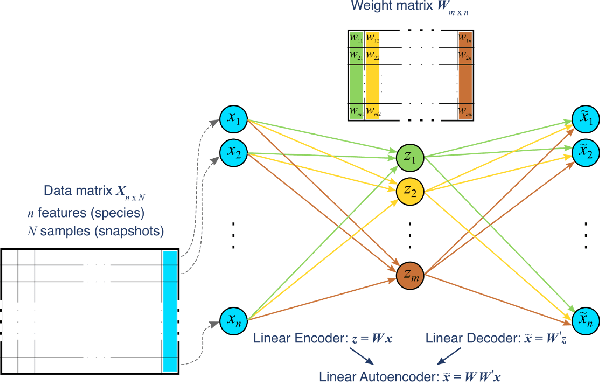
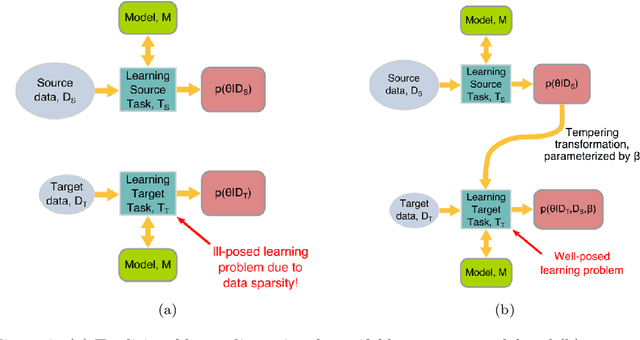
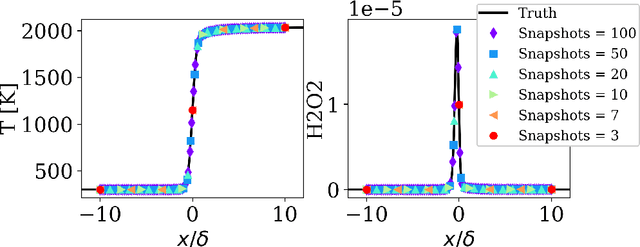
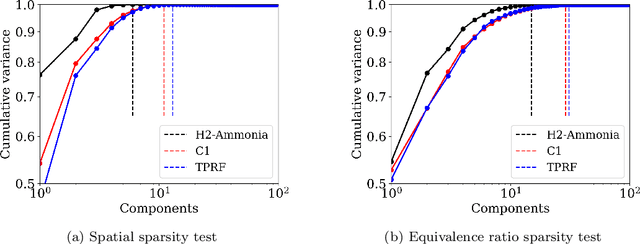
Reduced order models based on the transport of a lower dimensional manifold representation of the thermochemical state, such as Principal Component (PC) transport and Machine Learning (ML) techniques, have been developed to reduce the computational cost associated with the Direct Numerical Simulations (DNS) of reactive flows. Both PC transport and ML normally require an abundance of data to exhibit sufficient predictive accuracy, which might not be available due to the prohibitive cost of DNS or experimental data acquisition. To alleviate such difficulties, similar data from an existing dataset or domain (source domain) can be used to train ML models, potentially resulting in adequate predictions in the domain of interest (target domain). This study presents a novel probabilistic transfer learning (TL) framework to enhance the trust in ML models in correctly predicting the thermochemical state in a lower dimensional manifold and a sparse data setting. The framework uses Bayesian neural networks, and autoencoders, to reduce the dimensionality of the state space and diffuse the knowledge from the source to the target domain. The new framework is applied to one-dimensional freely-propagating flame solutions under different data sparsity scenarios. The results reveal that there is an optimal amount of knowledge to be transferred, which depends on the amount of data available in the target domain and the similarity between the domains. TL can reduce the reconstruction error by one order of magnitude for cases with large sparsity. The new framework required 10 times less data for the target domain to reproduce the same error as in the abundant data scenario. Furthermore, comparisons with a state-of-the-art deterministic TL strategy show that the probabilistic method can require four times less data to achieve the same reconstruction error.
Scaling While Privacy Preserving: A Comprehensive Synthetic Tabular Data Generation and Evaluation in Learning Analytics
Jan 12, 2024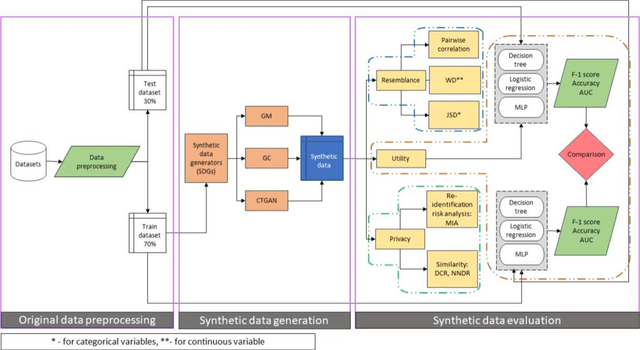
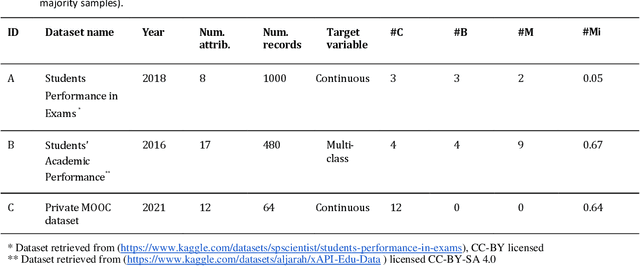
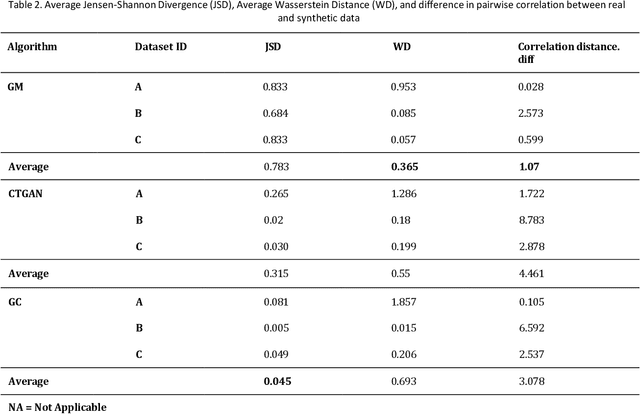
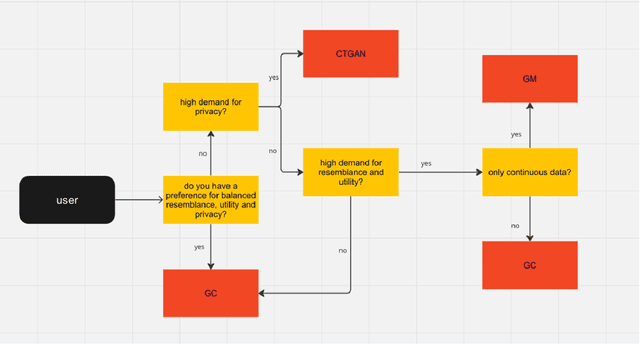
Privacy poses a significant obstacle to the progress of learning analytics (LA), presenting challenges like inadequate anonymization and data misuse that current solutions struggle to address. Synthetic data emerges as a potential remedy, offering robust privacy protection. However, prior LA research on synthetic data lacks thorough evaluation, essential for assessing the delicate balance between privacy and data utility. Synthetic data must not only enhance privacy but also remain practical for data analytics. Moreover, diverse LA scenarios come with varying privacy and utility needs, making the selection of an appropriate synthetic data approach a pressing challenge. To address these gaps, we propose a comprehensive evaluation of synthetic data, which encompasses three dimensions of synthetic data quality, namely resemblance, utility, and privacy. We apply this evaluation to three distinct LA datasets, using three different synthetic data generation methods. Our results show that synthetic data can maintain similar utility (i.e., predictive performance) as real data, while preserving privacy. Furthermore, considering different privacy and data utility requirements in different LA scenarios, we make customized recommendations for synthetic data generation. This paper not only presents a comprehensive evaluation of synthetic data but also illustrates its potential in mitigating privacy concerns within the field of LA, thus contributing to a wider application of synthetic data in LA and promoting a better practice for open science.
Enhancing Polynomial Chaos Expansion Based Surrogate Modeling using a Novel Probabilistic Transfer Learning Strategy
Dec 07, 2023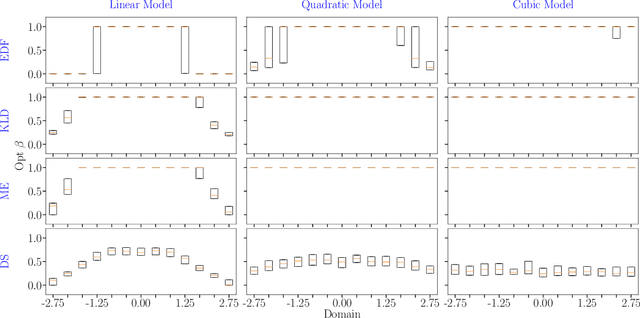
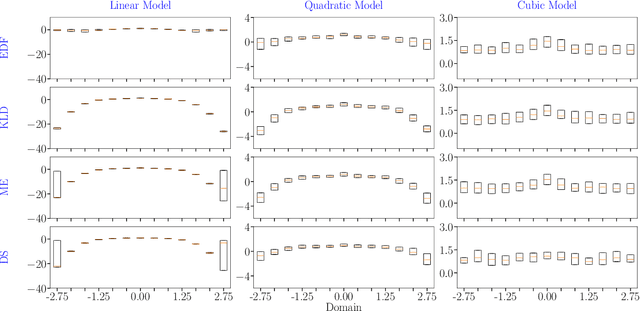
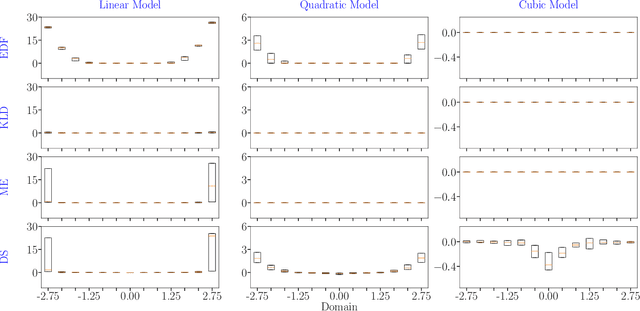
In the field of surrogate modeling, polynomial chaos expansion (PCE) allows practitioners to construct inexpensive yet accurate surrogates to be used in place of the expensive forward model simulations. For black-box simulations, non-intrusive PCE allows the construction of these surrogates using a set of simulation response evaluations. In this context, the PCE coefficients can be obtained using linear regression, which is also known as point collocation or stochastic response surfaces. Regression exhibits better scalability and can handle noisy function evaluations in contrast to other non-intrusive approaches, such as projection. However, since over-sampling is generally advisable for the linear regression approach, the simulation requirements become prohibitive for expensive forward models. We propose to leverage transfer learning whereby knowledge gained through similar PCE surrogate construction tasks (source domains) is transferred to a new surrogate-construction task (target domain) which has a limited number of forward model simulations (training data). The proposed transfer learning strategy determines how much, if any, information to transfer using new techniques inspired by Bayesian modeling and data assimilation. The strategy is scrutinized using numerical investigations and applied to an engineering problem from the oil and gas industry.
Transfer learning for predicting source terms of principal component transport in chemically reactive flow
Dec 01, 2023The objective of this study is to evaluate whether the number of requisite training samples can be reduced with the use of various transfer learning models for predicting, for example, the chemical source terms of the data-driven reduced-order model that represents the homogeneous ignition process of a hydrogen/air mixture. Principal component analysis is applied to reduce the dimensionality of the hydrogen/air mixture in composition space. Artificial neural networks (ANNs) are used to tabulate the reaction rates of principal components, and subsequently, a system of ordinary differential equations is solved. As the number of training samples decreases at the target task (i.e.,for T0 > 1000 K and various phi), the reduced-order model fails to predict the ignition evolution of a hydrogen/air mixture. Three transfer learning strategies are then applied to the training of the ANN model with a sparse dataset. The performance of the reduced-order model with a sparse dataset is found to be remarkably enhanced if the training of the ANN model is restricted by a regularization term that controls the degree of knowledge transfer from source to target tasks. To this end, a novel transfer learning method is introduced, parameter control via partial initialization and regularization (PaPIR), whereby the amount of knowledge transferred is systemically adjusted for the initialization and regularization of the ANN model in the target task. It is found that an additional performance gain can be achieved by changing the initialization scheme of the ANN model in the target task when the task similarity between source and target tasks is relatively low.
Robust scalable initialization for Bayesian variational inference with multi-modal Laplace approximations
Jul 12, 2023
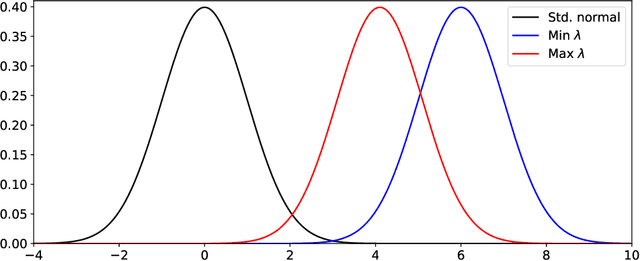

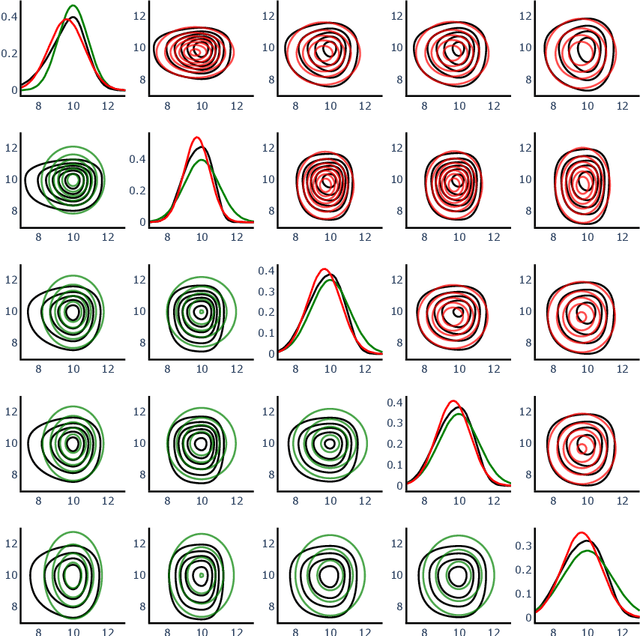
For predictive modeling relying on Bayesian inversion, fully independent, or ``mean-field'', Gaussian distributions are often used as approximate probability density functions in variational inference since the number of variational parameters is twice the number of unknown model parameters. The resulting diagonal covariance structure coupled with unimodal behavior can be too restrictive when dealing with highly non-Gaussian behavior, including multimodality. High-fidelity surrogate posteriors in the form of Gaussian mixtures can capture any distribution to an arbitrary degree of accuracy while maintaining some analytical tractability. Variational inference with Gaussian mixtures with full-covariance structures suffers from a quadratic growth in variational parameters with the number of model parameters. Coupled with the existence of multiple local minima due to nonconvex trends in the loss functions often associated with variational inference, these challenges motivate the need for robust initialization procedures to improve the performance and scalability of variational inference with mixture models. In this work, we propose a method for constructing an initial Gaussian mixture model approximation that can be used to warm-start the iterative solvers for variational inference. The procedure begins with an optimization stage in model parameter space in which local gradient-based optimization, globalized through multistart, is used to determine a set of local maxima, which we take to approximate the mixture component centers. Around each mode, a local Gaussian approximation is constructed via the Laplace method. Finally, the mixture weights are determined through constrained least squares regression. Robustness and scalability are demonstrated using synthetic tests. The methodology is applied to an inversion problem in structural dynamics involving unknown viscous damping coefficients.