 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeCausal Pre-training Under the Fairness Lens: An Empirical Study of TabPFN
Jan 27, 2026Foundation models for tabular data, such as the Tabular Prior-data Fitted Network (TabPFN), are pre-trained on a massive number of synthetic datasets generated by structural causal models (SCM). They leverage in-context learning to offer high predictive accuracy in real-world tasks. However, the fairness properties of these foundational models, which incorporate ideas from causal reasoning during pre-training, remain underexplored. In this work, we conduct a comprehensive empirical evaluation of TabPFN and its fine-tuned variants, assessing predictive performance, fairness, and robustness across varying dataset sizes and distributional shifts. Our results reveal that while TabPFN achieves stronger predictive accuracy compared to baselines and exhibits robustness to spurious correlations, improvements in fairness are moderate and inconsistent, particularly under missing-not-at-random (MNAR) covariate shifts. These findings suggest that the causal pre-training in TabPFN is helpful but insufficient for algorithmic fairness, highlighting implications for deploying TabPFN (and similar) models in practice and the need for further fairness interventions.
Towards Privacy-Preserving Data-Driven Education: The Potential of Federated Learning
Mar 16, 2025

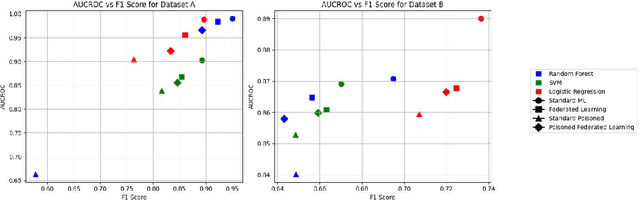

The increasing adoption of data-driven applications in education such as in learning analytics and AI in education has raised significant privacy and data protection concerns. While these challenges have been widely discussed in previous works, there are still limited practical solutions. Federated learning has recently been discoursed as a promising privacy-preserving technique, yet its application in education remains scarce. This paper presents an experimental evaluation of federated learning for educational data prediction, comparing its performance to traditional non-federated approaches. Our findings indicate that federated learning achieves comparable predictive accuracy. Furthermore, under adversarial attacks, federated learning demonstrates greater resilience compared to non-federated settings. We summarise that our results reinforce the value of federated learning as a potential approach for balancing predictive performance and privacy in educational contexts.
Creating Artificial Students that Never Existed: Leveraging Large Language Models and CTGANs for Synthetic Data Generation
Jan 03, 2025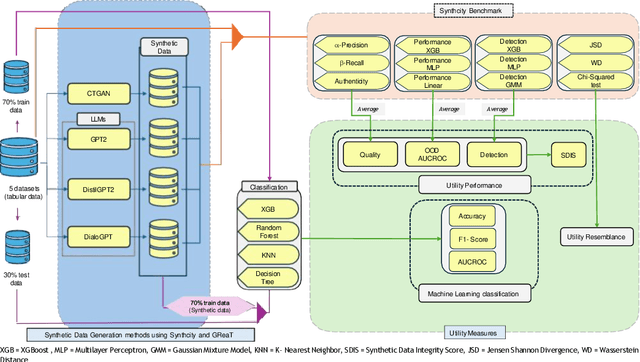

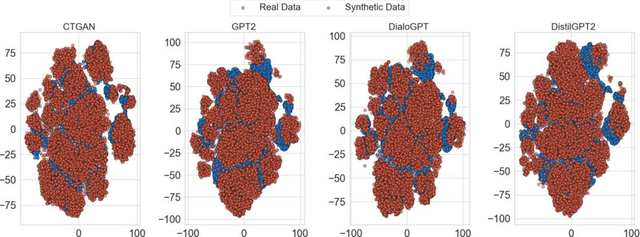
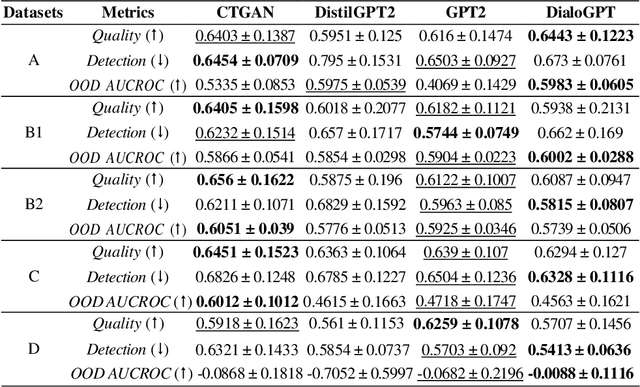
In this study, we explore the growing potential of AI and deep learning technologies, particularly Generative Adversarial Networks (GANs) and Large Language Models (LLMs), for generating synthetic tabular data. Access to quality students data is critical for advancing learning analytics, but privacy concerns and stricter data protection regulations worldwide limit their availability and usage. Synthetic data offers a promising alternative. We investigate whether synthetic data can be leveraged to create artificial students for serving learning analytics models. Using the popular GAN model CTGAN and three LLMs- GPT2, DistilGPT2, and DialoGPT, we generate synthetic tabular student data. Our results demonstrate the strong potential of these methods to produce high-quality synthetic datasets that resemble real students data. To validate our findings, we apply a comprehensive set of utility evaluation metrics to assess the statistical and predictive performance of the synthetic data and compare the different generator models used, specially the performance of LLMs. Our study aims to provide the learning analytics community with valuable insights into the use of synthetic data, laying the groundwork for expanding the field methodological toolbox with new innovative approaches for learning analytics data generation.
Can Synthetic Data be Fair and Private? A Comparative Study of Synthetic Data Generation and Fairness Algorithms
Jan 03, 2025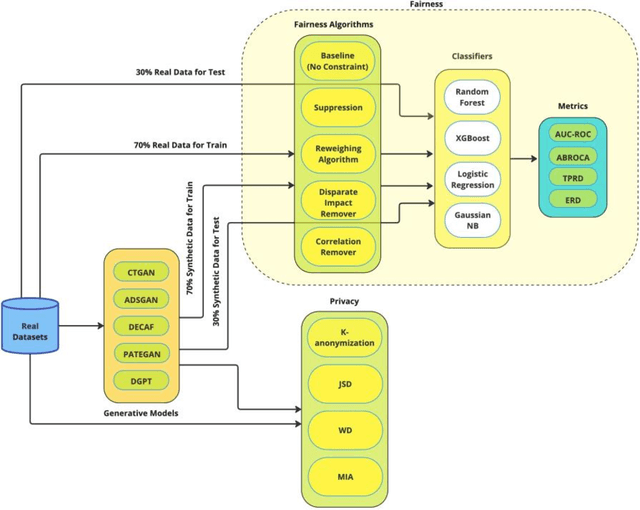
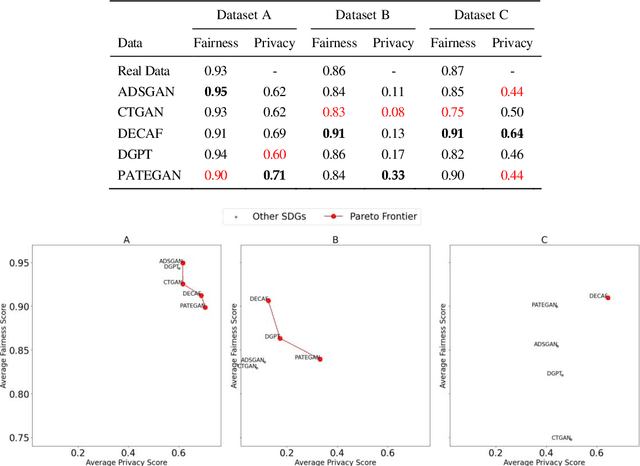
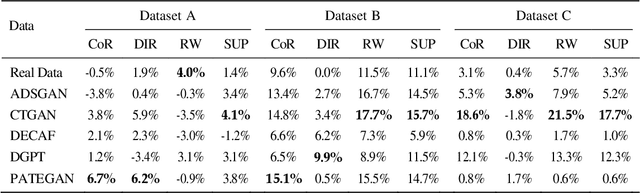
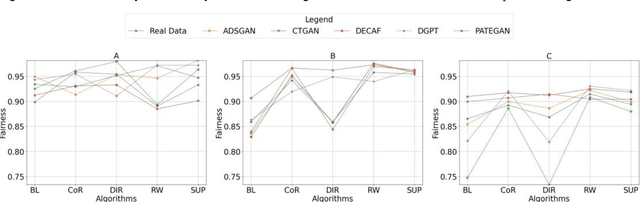
The increasing use of machine learning in learning analytics (LA) has raised significant concerns around algorithmic fairness and privacy. Synthetic data has emerged as a dual-purpose tool, enhancing privacy and improving fairness in LA models. However, prior research suggests an inverse relationship between fairness and privacy, making it challenging to optimize both. This study investigates which synthetic data generators can best balance privacy and fairness, and whether pre-processing fairness algorithms, typically applied to real datasets, are effective on synthetic data. Our results highlight that the DEbiasing CAusal Fairness (DECAF) algorithm achieves the best balance between privacy and fairness. However, DECAF suffers in utility, as reflected in its predictive accuracy. Notably, we found that applying pre-processing fairness algorithms to synthetic data improves fairness even more than when applied to real data. These findings suggest that combining synthetic data generation with fairness pre-processing offers a promising approach to creating fairer LA models.
Scaling While Privacy Preserving: A Comprehensive Synthetic Tabular Data Generation and Evaluation in Learning Analytics
Jan 12, 2024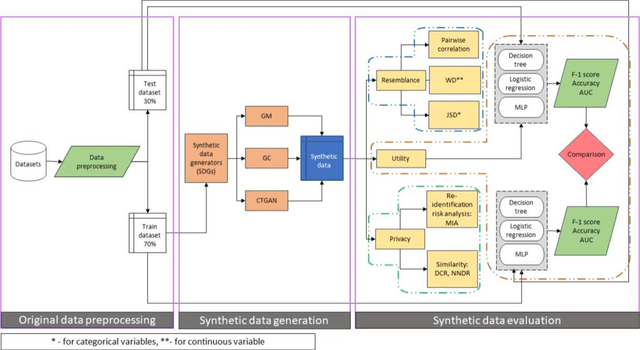
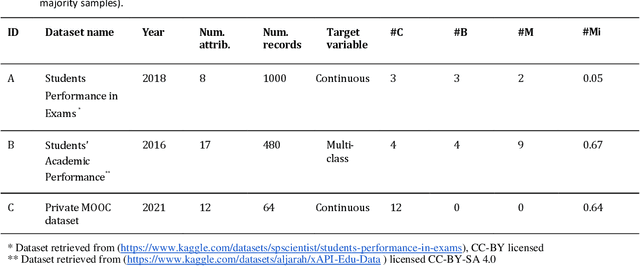
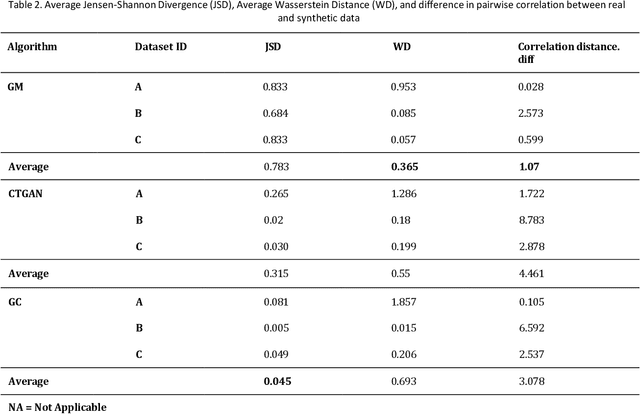
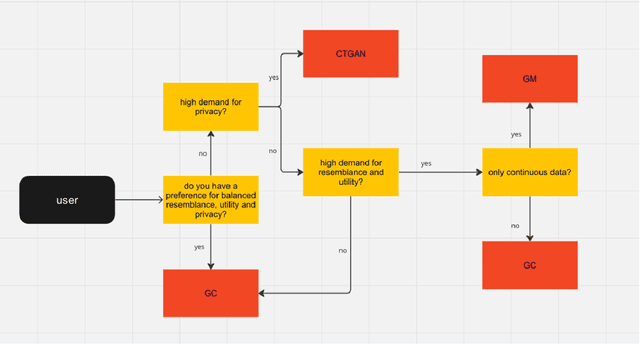
Privacy poses a significant obstacle to the progress of learning analytics (LA), presenting challenges like inadequate anonymization and data misuse that current solutions struggle to address. Synthetic data emerges as a potential remedy, offering robust privacy protection. However, prior LA research on synthetic data lacks thorough evaluation, essential for assessing the delicate balance between privacy and data utility. Synthetic data must not only enhance privacy but also remain practical for data analytics. Moreover, diverse LA scenarios come with varying privacy and utility needs, making the selection of an appropriate synthetic data approach a pressing challenge. To address these gaps, we propose a comprehensive evaluation of synthetic data, which encompasses three dimensions of synthetic data quality, namely resemblance, utility, and privacy. We apply this evaluation to three distinct LA datasets, using three different synthetic data generation methods. Our results show that synthetic data can maintain similar utility (i.e., predictive performance) as real data, while preserving privacy. Furthermore, considering different privacy and data utility requirements in different LA scenarios, we make customized recommendations for synthetic data generation. This paper not only presents a comprehensive evaluation of synthetic data but also illustrates its potential in mitigating privacy concerns within the field of LA, thus contributing to a wider application of synthetic data in LA and promoting a better practice for open science.