 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeScaling While Privacy Preserving: A Comprehensive Synthetic Tabular Data Generation and Evaluation in Learning Analytics
Jan 12, 2024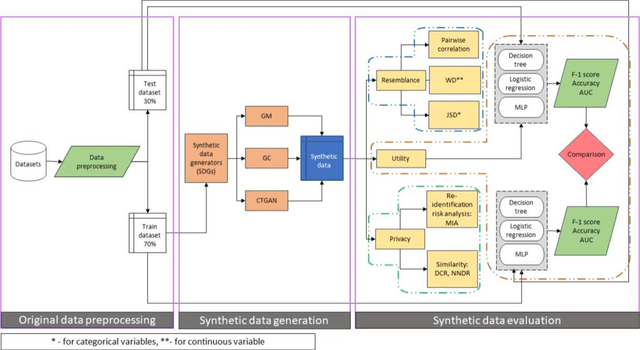
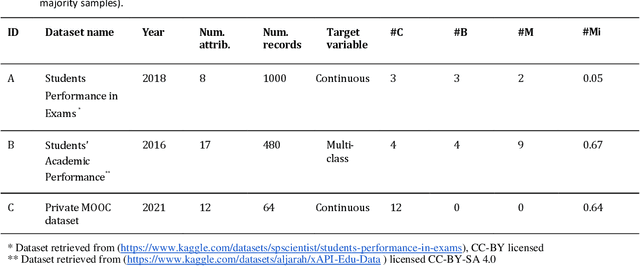
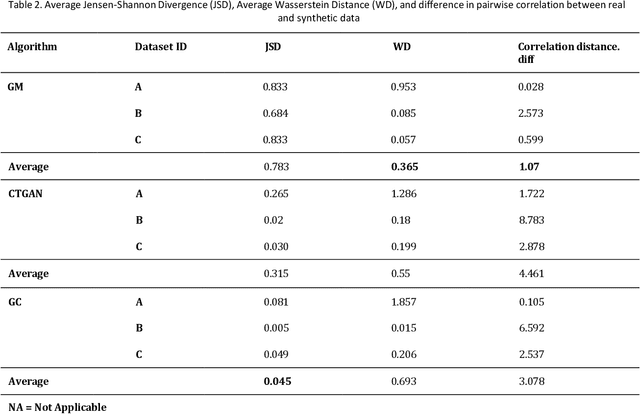
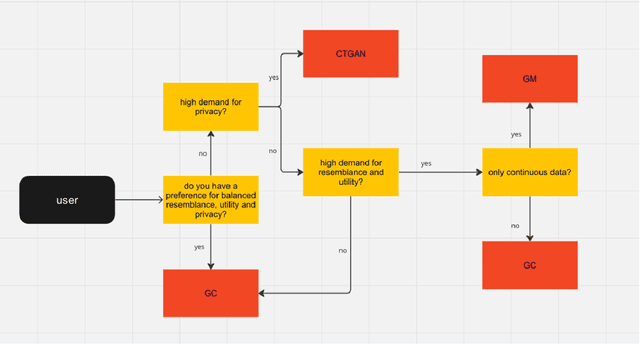
Privacy poses a significant obstacle to the progress of learning analytics (LA), presenting challenges like inadequate anonymization and data misuse that current solutions struggle to address. Synthetic data emerges as a potential remedy, offering robust privacy protection. However, prior LA research on synthetic data lacks thorough evaluation, essential for assessing the delicate balance between privacy and data utility. Synthetic data must not only enhance privacy but also remain practical for data analytics. Moreover, diverse LA scenarios come with varying privacy and utility needs, making the selection of an appropriate synthetic data approach a pressing challenge. To address these gaps, we propose a comprehensive evaluation of synthetic data, which encompasses three dimensions of synthetic data quality, namely resemblance, utility, and privacy. We apply this evaluation to three distinct LA datasets, using three different synthetic data generation methods. Our results show that synthetic data can maintain similar utility (i.e., predictive performance) as real data, while preserving privacy. Furthermore, considering different privacy and data utility requirements in different LA scenarios, we make customized recommendations for synthetic data generation. This paper not only presents a comprehensive evaluation of synthetic data but also illustrates its potential in mitigating privacy concerns within the field of LA, thus contributing to a wider application of synthetic data in LA and promoting a better practice for open science.
Reviewer assignment problem: A scoping review
May 13, 2023



Peer review is an integral component of scientific research. The quality of peer review, and consequently the published research, depends to a large extent on the ability to recruit adequate reviewers for submitted papers. However, finding such reviewers is an increasingly difficult task due to several factors, such as the continuous increase both in the production of scientific papers and the workload of scholars. To mitigate these challenges, solutions for automated association of papers with "well matching" reviewers - the task often referred to as reviewer assignment problem (RAP) - have been the subject of research for thirty years now. Even though numerous solutions have been suggested, to our knowledge, a recent systematic synthesis of the RAP-related literature is missing. To fill this gap and support further RAP-related research, in this paper, we present a scoping review of computational approaches for addressing RAP. Following the latest methodological guidance for scoping reviews, we have collected recent literature on RAP from three databases (Scopus, Google Scholar, DBLP) and, after applying the eligibility criteria, retained 26 studies for extracting and synthesising data on several aspects of RAP research including: i) the overall framing of and approach to RAP; ii) the criteria for reviewer selection; iii) the modelling of candidate reviewers and submissions; iv) the computational methods for matching reviewers and submissions; and v) the methods for evaluating the performance of the proposed solutions. The paper summarises and discusses the findings for each of the aforementioned aspects of RAP research and suggests future research directions.