 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeTemporal Interpolation Is All You Need for Dynamic Neural Radiance Fields
Feb 18, 2023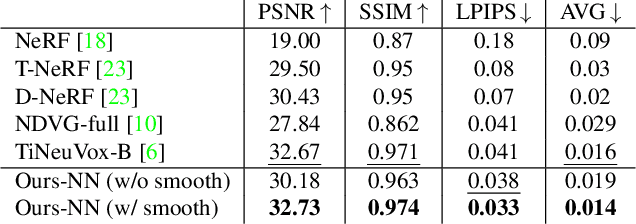
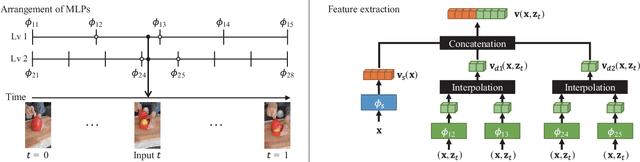
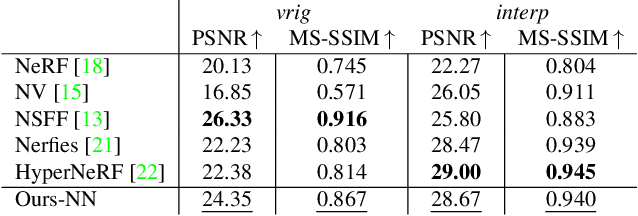
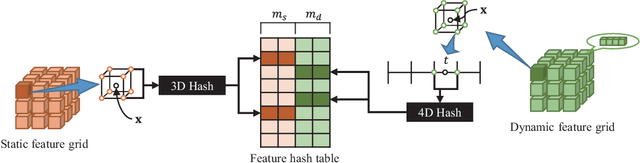
Temporal interpolation often plays a crucial role to learn meaningful representations in dynamic scenes. In this paper, we propose a novel method to train four-dimensional spatiotemporal neural radiance fields of dynamic scenes based on temporal interpolation of feature vectors. Two feature interpolation methods are suggested depending on underlying representations, neural or grid representation. In neural representation, we extract features from space-time inputs via multiple neural network modules and interpolate them based on time frames. The proposed multi-level feature interpolation network effectively captures features of both short-term and long-term time ranges. In grid representation, space-time features are learned via four-dimensional hash grids. The grid representation remarkably reduces training time, which is more than 100$\times$ faster compared to the neural network models, while maintaining the rendering quality of trained models. Concatenation of static and dynamic features and addition of simple smoothness term further improves the performance of the proposed models. Despite the simplicity of its network architecture, we demonstrate that the proposed method shows superior performance to previous works in neural representation and shows the fastest training speed in grid representation.
SinGRAF: Learning a 3D Generative Radiance Field for a Single Scene
Nov 30, 2022Generative models have shown great promise in synthesizing photorealistic 3D objects, but they require large amounts of training data. We introduce SinGRAF, a 3D-aware generative model that is trained with a few input images of a single scene. Once trained, SinGRAF generates different realizations of this 3D scene that preserve the appearance of the input while varying scene layout. For this purpose, we build on recent progress in 3D GAN architectures and introduce a novel progressive-scale patch discrimination approach during training. With several experiments, we demonstrate that the results produced by SinGRAF outperform the closest related works in both quality and diversity by a large margin.
NPRportrait 1.0: A Three-Level Benchmark for Non-Photorealistic Rendering of Portraits
Sep 01, 2020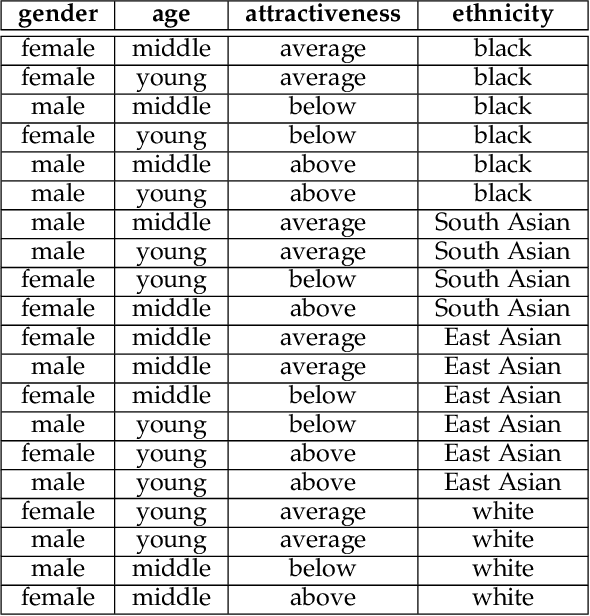

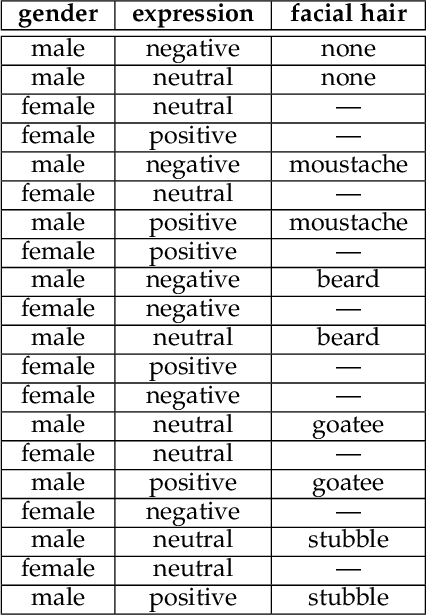
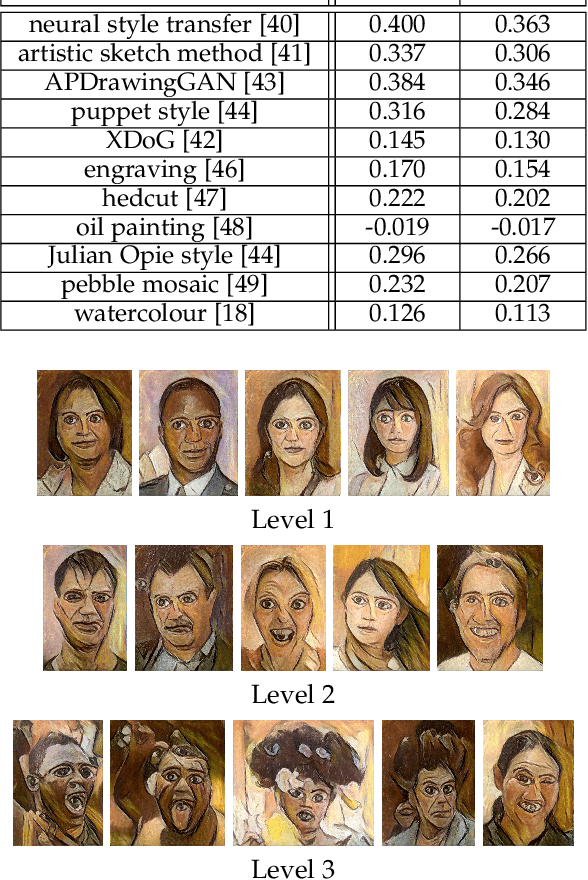
Despite the recent upsurge of activity in image-based non-photorealistic rendering (NPR), and in particular portrait image stylisation, due to the advent of neural style transfer, the state of performance evaluation in this field is limited, especially compared to the norms in the computer vision and machine learning communities. Unfortunately, the task of evaluating image stylisation is thus far not well defined, since it involves subjective, perceptual and aesthetic aspects. To make progress towards a solution, this paper proposes a new structured, three level, benchmark dataset for the evaluation of stylised portrait images. Rigorous criteria were used for its construction, and its consistency was validated by user studies. Moreover, a new methodology has been developed for evaluating portrait stylisation algorithms, which makes use of the different benchmark levels as well as annotations provided by user studies regarding the characteristics of the faces. We perform evaluation for a wide variety of image stylisation methods (both portrait-specific and general purpose, and also both traditional NPR approaches and neural style transfer) using the new benchmark dataset.