 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeTemporal Interpolation Is All You Need for Dynamic Neural Radiance Fields
Feb 18, 2023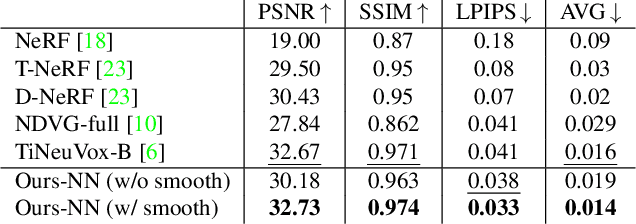
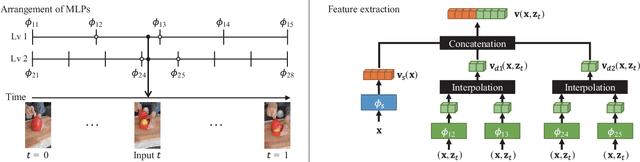
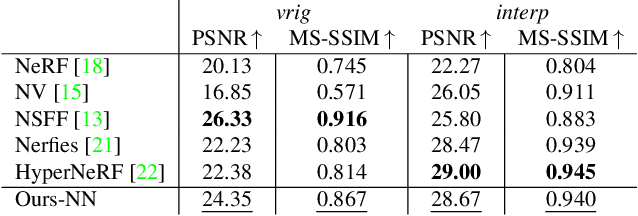
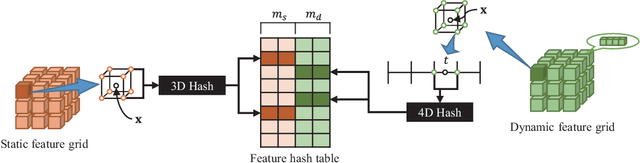
Temporal interpolation often plays a crucial role to learn meaningful representations in dynamic scenes. In this paper, we propose a novel method to train four-dimensional spatiotemporal neural radiance fields of dynamic scenes based on temporal interpolation of feature vectors. Two feature interpolation methods are suggested depending on underlying representations, neural or grid representation. In neural representation, we extract features from space-time inputs via multiple neural network modules and interpolate them based on time frames. The proposed multi-level feature interpolation network effectively captures features of both short-term and long-term time ranges. In grid representation, space-time features are learned via four-dimensional hash grids. The grid representation remarkably reduces training time, which is more than 100$\times$ faster compared to the neural network models, while maintaining the rendering quality of trained models. Concatenation of static and dynamic features and addition of simple smoothness term further improves the performance of the proposed models. Despite the simplicity of its network architecture, we demonstrate that the proposed method shows superior performance to previous works in neural representation and shows the fastest training speed in grid representation.
PANeRF: Pseudo-view Augmentation for Improved Neural Radiance Fields Based on Few-shot Inputs
Nov 23, 2022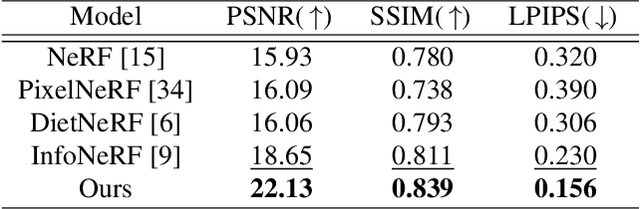
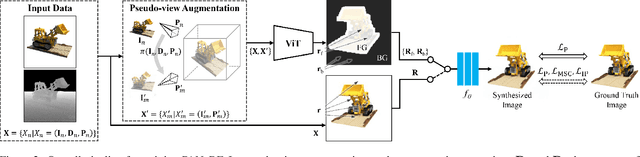

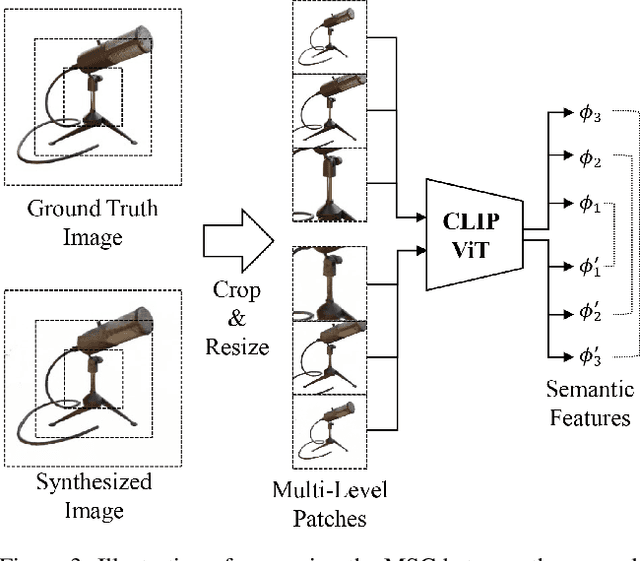
The method of neural radiance fields (NeRF) has been developed in recent years, and this technology has promising applications for synthesizing novel views of complex scenes. However, NeRF requires dense input views, typically numbering in the hundreds, for generating high-quality images. With a decrease in the number of input views, the rendering quality of NeRF for unseen viewpoints tends to degenerate drastically. To overcome this challenge, we propose pseudo-view augmentation of NeRF, a scheme that expands a sufficient amount of data by considering the geometry of few-shot inputs. We first initialized the NeRF network by leveraging the expanded pseudo-views, which efficiently minimizes uncertainty when rendering unseen views. Subsequently, we fine-tuned the network by utilizing sparse-view inputs containing precise geometry and color information. Through experiments under various settings, we verified that our model faithfully synthesizes novel-view images of superior quality and outperforms existing methods for multi-view datasets.