 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeCorrelation-based Discovery of Disease Patterns for Syndromic Surveillance
Oct 18, 2021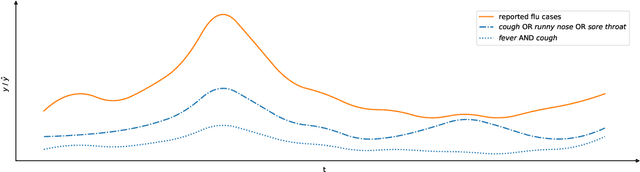
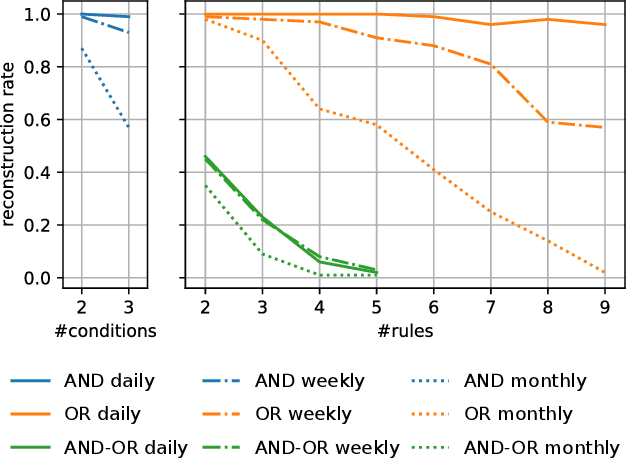
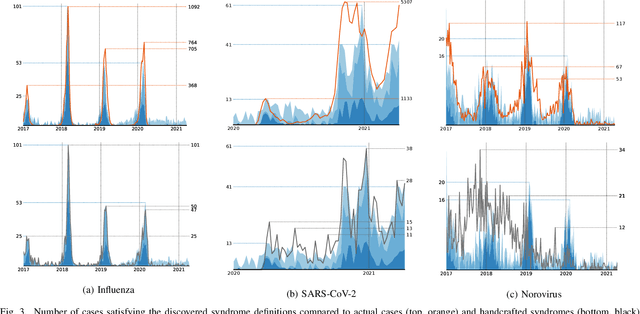
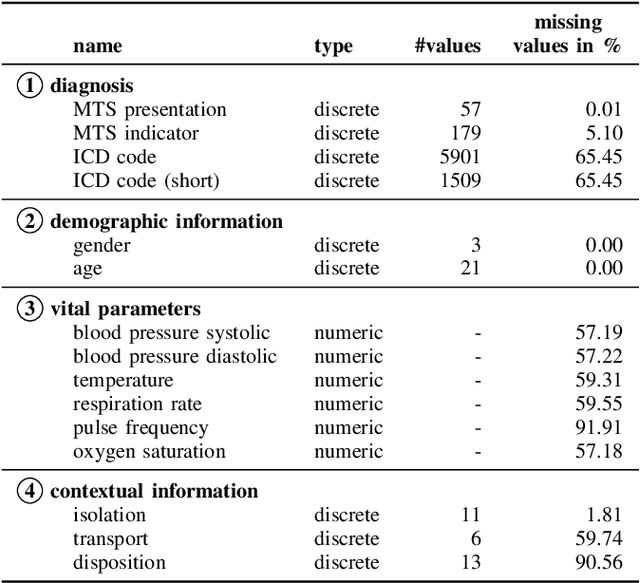
Early outbreak detection is a key aspect in the containment of infectious diseases, as it enables the identification and isolation of infected individuals before the disease can spread to a larger population. Instead of detecting unexpected increases of infections by monitoring confirmed cases, syndromic surveillance aims at the detection of cases with early symptoms, which allows a more timely disclosure of outbreaks. However, the definition of these disease patterns is often challenging, as early symptoms are usually shared among many diseases and a particular disease can have several clinical pictures in the early phase of an infection. To support epidemiologists in the process of defining reliable disease patterns, we present a novel, data-driven approach to discover such patterns in historic data. The key idea is to take into account the correlation between indicators in a health-related data source and the reported number of infections in the respective geographic region. In an experimental evaluation, we use data from several emergency departments to discover disease patterns for three infectious diseases. Our results suggest that the proposed approach is able to find patterns that correlate with the reported infections and often identifies indicators that are related to the respective diseases.
Gradient-based Label Binning in Multi-label Classification
Jun 22, 2021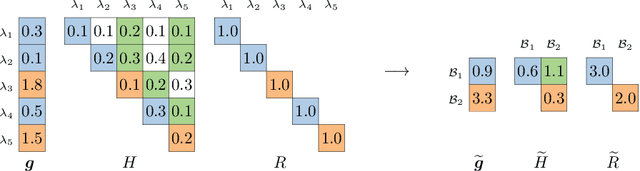
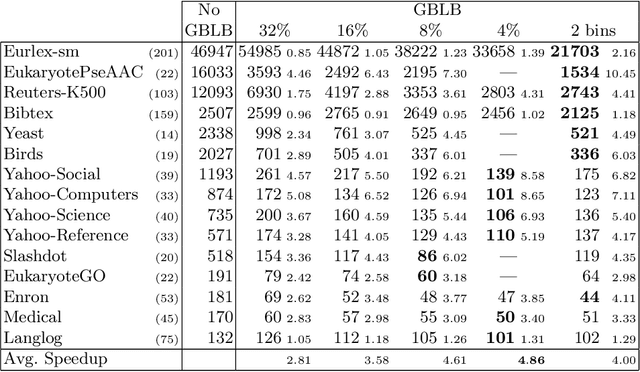
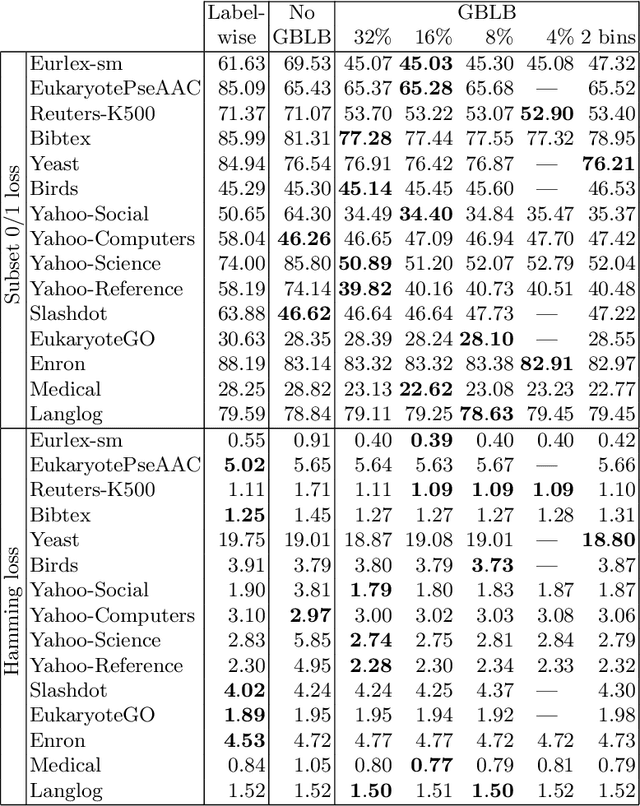
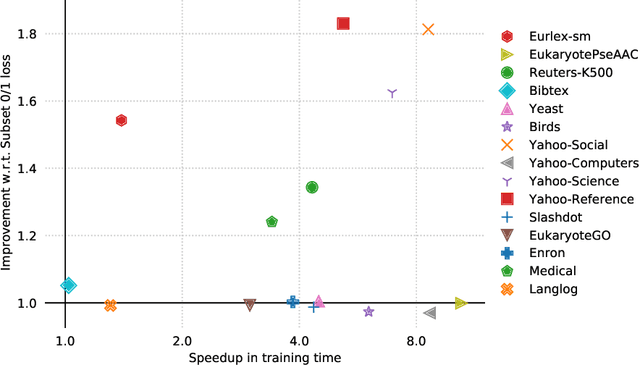
In multi-label classification, where a single example may be associated with several class labels at the same time, the ability to model dependencies between labels is considered crucial to effectively optimize non-decomposable evaluation measures, such as the Subset 0/1 loss. The gradient boosting framework provides a well-studied foundation for learning models that are specifically tailored to such a loss function and recent research attests the ability to achieve high predictive accuracy in the multi-label setting. The utilization of second-order derivatives, as used by many recent boosting approaches, helps to guide the minimization of non-decomposable losses, due to the information about pairs of labels it incorporates into the optimization process. On the downside, this comes with high computational costs, even if the number of labels is small. In this work, we address the computational bottleneck of such approach -- the need to solve a system of linear equations -- by integrating a novel approximation technique into the boosting procedure. Based on the derivatives computed during training, we dynamically group the labels into a predefined number of bins to impose an upper bound on the dimensionality of the linear system. Our experiments, using an existing rule-based algorithm, suggest that this may boost the speed of training, without any significant loss in predictive performance.
Learning Structured Declarative Rule Sets -- A Challenge for Deep Discrete Learning
Dec 08, 2020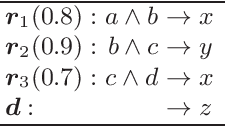
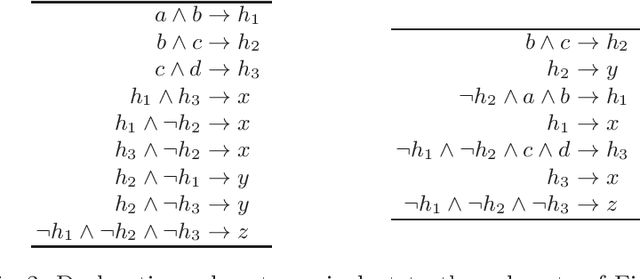
Arguably the key reason for the success of deep neural networks is their ability to autonomously form non-linear combinations of the input features, which can be used in subsequent layers of the network. The analogon to this capability in inductive rule learning is to learn a structured rule base, where the inputs are combined to learn new auxiliary concepts, which can then be used as inputs by subsequent rules. Yet, research on rule learning algorithms that have such capabilities is still in their infancy, which is - we would argue - one of the key impediments to substantial progress in this field. In this position paper, we want to draw attention to this unsolved problem, with a particular focus on previous work in predicate invention and multi-label rule learning
A Flexible Class of Dependence-aware Multi-Label Loss Functions
Nov 02, 2020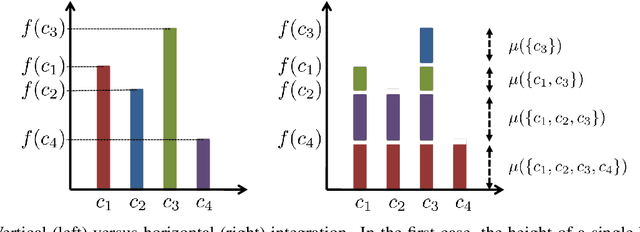
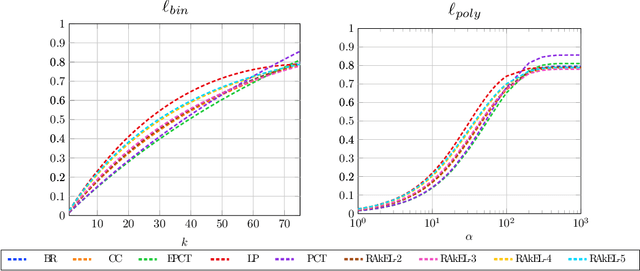
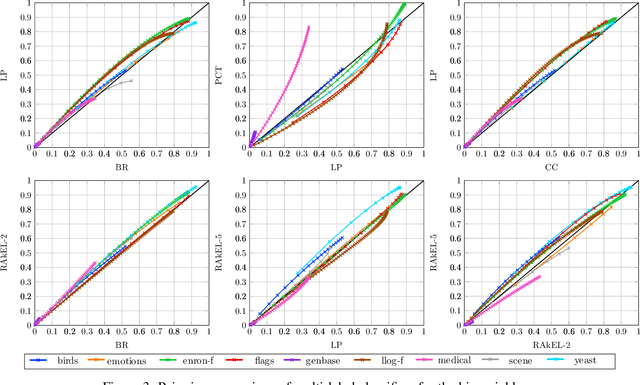
Multi-label classification is the task of assigning a subset of labels to a given query instance. For evaluating such predictions, the set of predicted labels needs to be compared to the ground-truth label set associated with that instance, and various loss functions have been proposed for this purpose. In addition to assessing predictive accuracy, a key concern in this regard is to foster and to analyze a learner's ability to capture label dependencies. In this paper, we introduce a new class of loss functions for multi-label classification, which overcome disadvantages of commonly used losses such as Hamming and subset 0/1. To this end, we leverage the mathematical framework of non-additive measures and integrals. Roughly speaking, a non-additive measure allows for modeling the importance of correct predictions of label subsets (instead of single labels), and thereby their impact on the overall evaluation, in a flexible way - by giving full importance to single labels and the entire label set, respectively, Hamming and subset 0/1 are rather extreme in this regard. We present concrete instantiations of this class, which comprise Hamming and subset 0/1 as special cases, and which appear to be especially appealing from a modeling perspective. The assessment of multi-label classifiers in terms of these losses is illustrated in an empirical study.
Learning Gradient Boosted Multi-label Classification Rules
Jun 23, 2020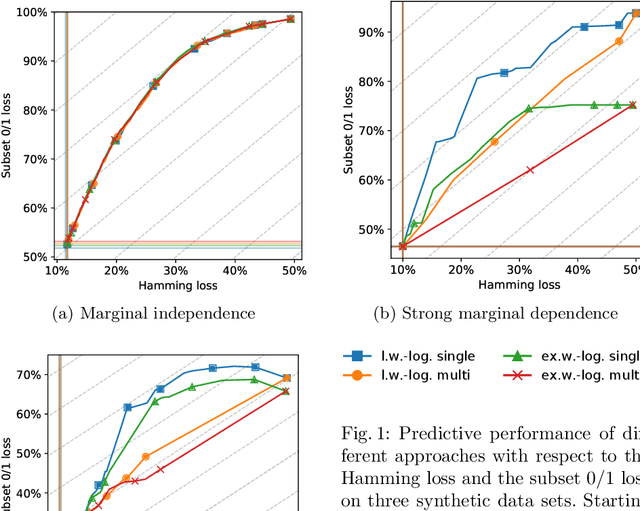
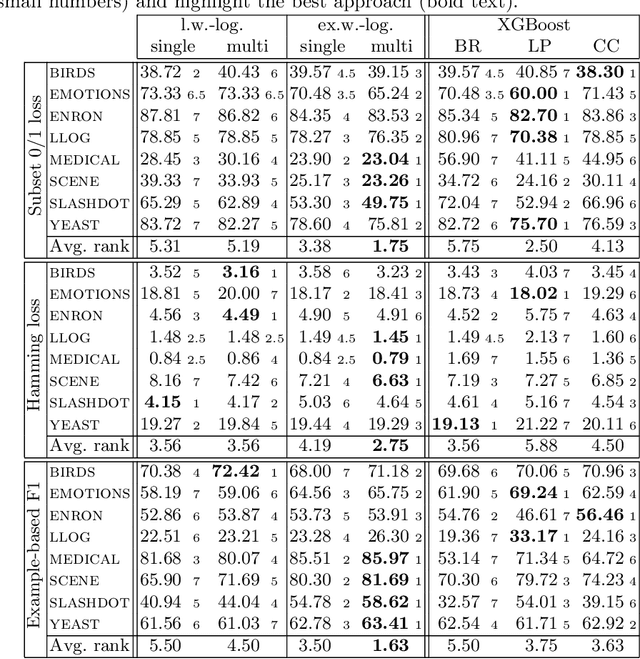
In multi-label classification, where the evaluation of predictions is less straightforward than in single-label classification, various meaningful, though different, loss functions have been proposed. Ideally, the learning algorithm should be customizable towards a specific choice of the performance measure. Modern implementations of boosting, most prominently gradient boosted decision trees, appear to be appealing from this point of view. However, they are mostly limited to single-label classification, and hence not amenable to multi-label losses unless these are label-wise decomposable. In this work, we develop a generalization of the gradient boosting framework to multi-output problems and propose an algorithm for learning multi-label classification rules that is able to minimize decomposable as well as non-decomposable loss functions. Using the well-known Hamming loss and subset 0/1 loss as representatives, we analyze the abilities and limitations of our approach on synthetic data and evaluate its predictive performance on multi-label benchmarks.
On Aggregation in Ensembles of Multilabel Classifiers
Jun 21, 2020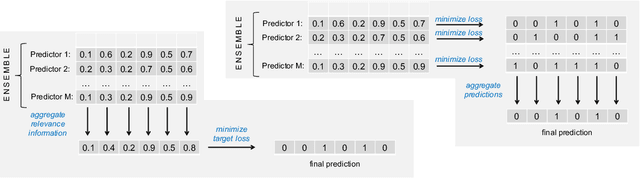
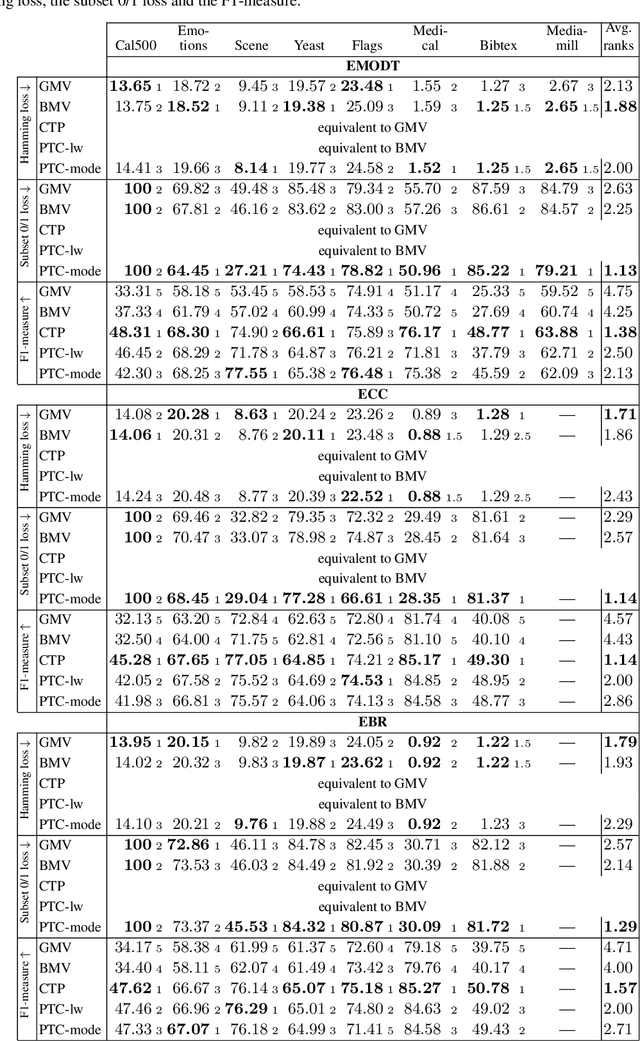
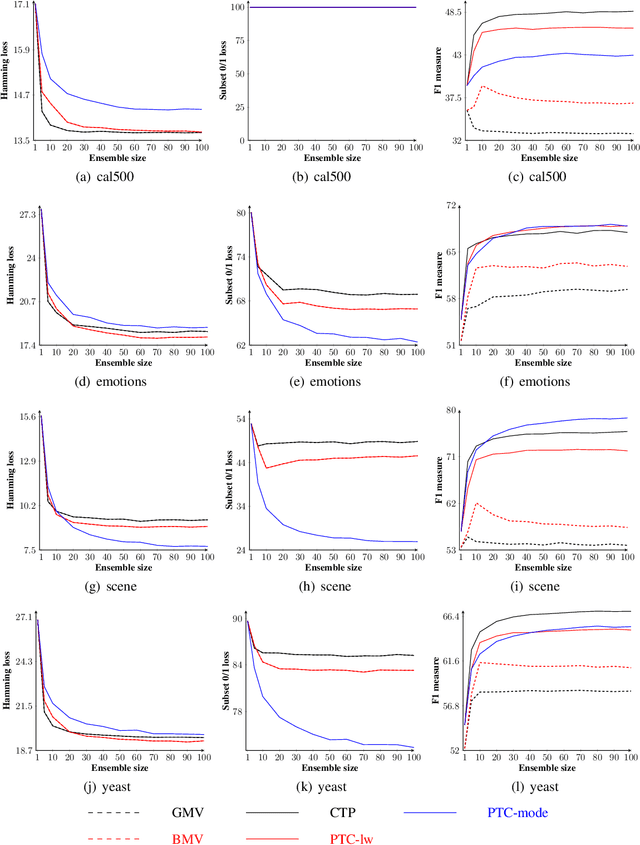
While a variety of ensemble methods for multilabel classification have been proposed in the literature, the question of how to aggregate the predictions of the individual members of the ensemble has received little attention so far. In this paper, we introduce a formal framework of ensemble multilabel classification, in which we distinguish two principal approaches: "predict then combine" (PTC), where the ensemble members first make loss minimizing predictions which are subsequently combined, and "combine then predict" (CTP), which first aggregates information such as marginal label probabilities from the individual ensemble members, and then derives a prediction from this aggregation. While both approaches generalize voting techniques commonly used for multilabel ensembles, they allow to explicitly take the target performance measure into account. Therefore, concrete instantiations of CTP and PTC can be tailored to concrete loss functions. Experimentally, we show that standard voting techniques are indeed outperformed by suitable instantiations of CTP and PTC, and provide some evidence that CTP performs well for decomposable loss functions, whereas PTC is the better choice for non-decomposable losses.
Simplifying Random Forests: On the Trade-off between Interpretability and Accuracy
Nov 11, 2019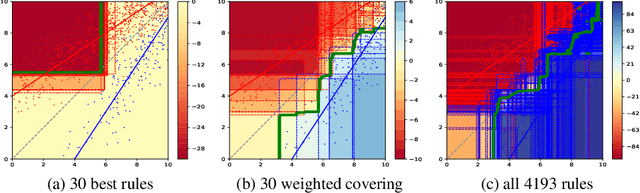
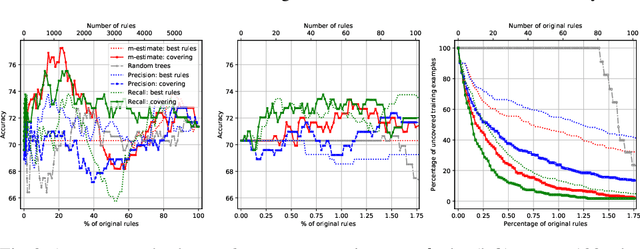
We analyze the trade-off between model complexity and accuracy for random forests by breaking the trees up into individual classification rules and selecting a subset of them. We show experimentally that already a few rules are sufficient to achieve an acceptable accuracy close to that of the original model. Moreover, our results indicate that in many cases, this can lead to simpler models that clearly outperform the original ones.
Efficient Discovery of Expressive Multi-label Rules using Relaxed Pruning
Aug 19, 2019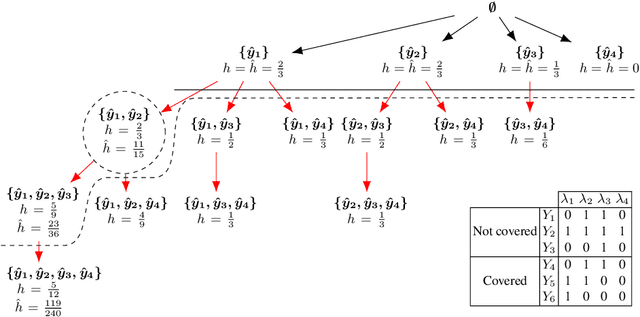
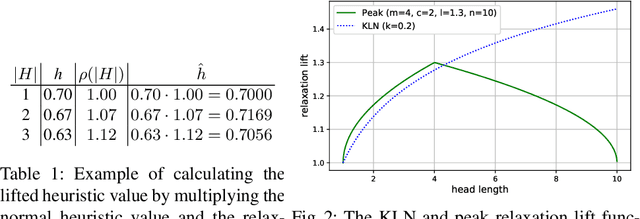
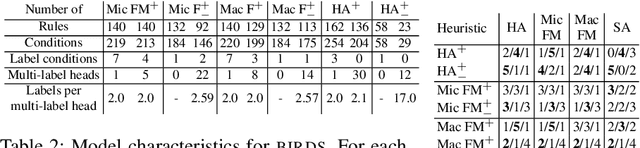
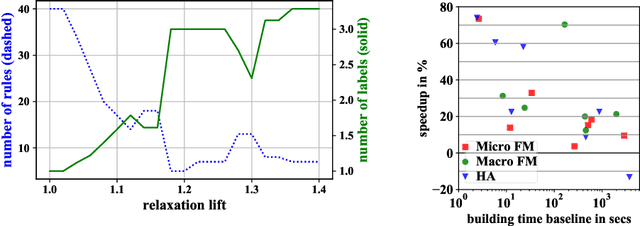
Being able to model correlations between labels is considered crucial in multi-label classification. Rule-based models enable to expose such dependencies, e.g., implications, subsumptions, or exclusions, in an interpretable and human-comprehensible manner. Albeit the number of possible label combinations increases exponentially with the number of available labels, it has been shown that rules with multiple labels in their heads, which are a natural form to model local label dependencies, can be induced efficiently by exploiting certain properties of rule evaluation measures and pruning the label search space accordingly. However, experiments have revealed that multi-label heads are unlikely to be learned by existing methods due to their restrictiveness. To overcome this limitation, we propose a plug-in approach that relaxes the search space pruning used by existing methods in order to introduce a bias towards larger multi-label heads resulting in more expressive rules. We further demonstrate the effectiveness of our approach empirically and show that it does not come with drawbacks in terms of training time or predictive performance.
On the Trade-off Between Consistency and Coverage in Multi-label Rule Learning Heuristics
Aug 08, 2019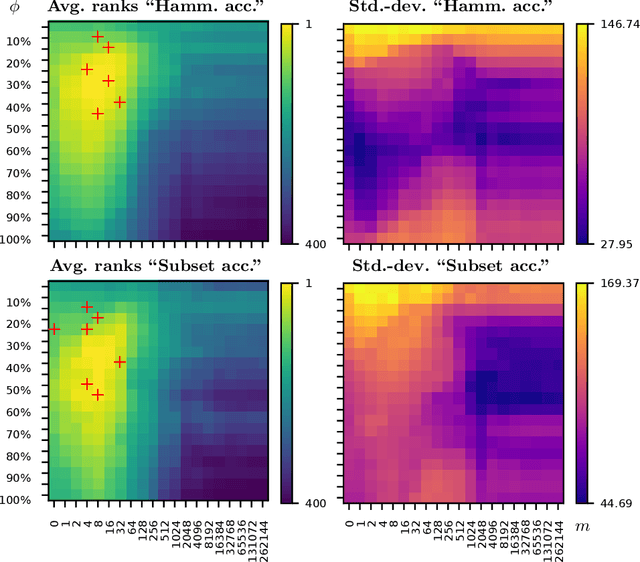
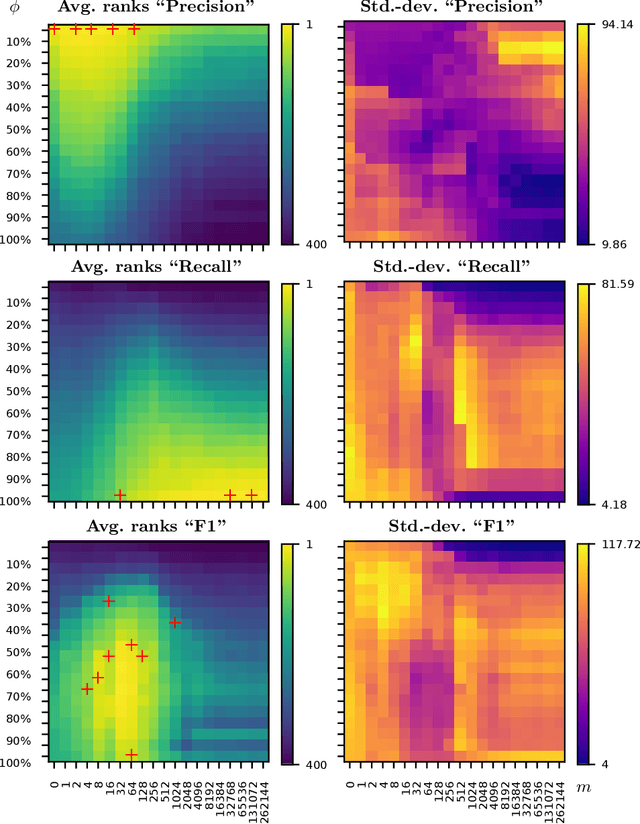
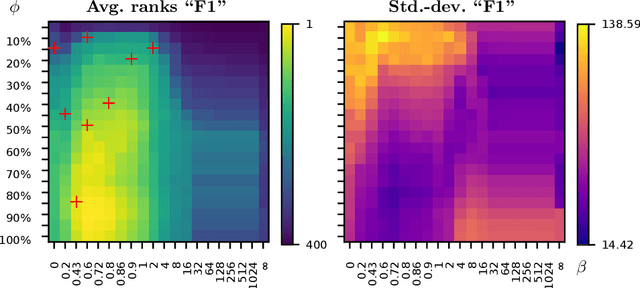

Recently, several authors have advocated the use of rule learning algorithms to model multi-label data, as rules are interpretable and can be comprehended, analyzed, or qualitatively evaluated by domain experts. Many rule learning algorithms employ a heuristic-guided search for rules that model regularities contained in the training data and it is commonly accepted that the choice of the heuristic has a significant impact on the predictive performance of the learner. Whereas the properties of rule learning heuristics have been studied in the realm of single-label classification, there is no such work taking into account the particularities of multi-label classification. This is surprising, as the quality of multi-label predictions is usually assessed in terms of a variety of different, potentially competing, performance measures that cannot all be optimized by a single learner at the same time. In this work, we show empirically that it is crucial to trade off the consistency and coverage of rules differently, depending on which multi-label measure should be optimized by a model. Based on these findings, we emphasize the need for configurable learners that can flexibly use different heuristics. As our experiments reveal, the choice of the heuristic is not straight-forward, because a search for rules that optimize a measure locally does usually not result in a model that maximizes that measure globally.
Exploiting Anti-monotonicity of Multi-label Evaluation Measures for Inducing Multi-label Rules
Dec 14, 2018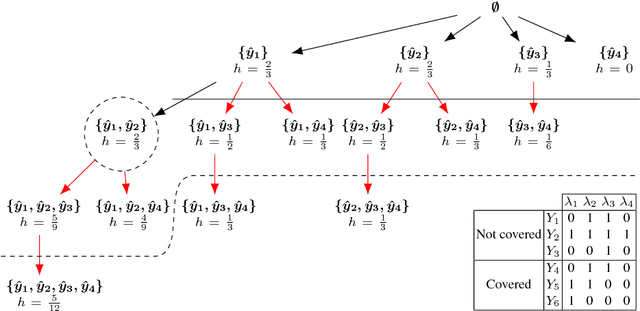

Exploiting dependencies between labels is considered to be crucial for multi-label classification. Rules are able to expose label dependencies such as implications, subsumptions or exclusions in a human-comprehensible and interpretable manner. However, the induction of rules with multiple labels in the head is particularly challenging, as the number of label combinations which must be taken into account for each rule grows exponentially with the number of available labels. To overcome this limitation, algorithms for exhaustive rule mining typically use properties such as anti-monotonicity or decomposability in order to prune the search space. In the present paper, we examine whether commonly used multi-label evaluation metrics satisfy these properties and therefore are suited to prune the search space for multi-label heads.