Get our free extension to see links to code for papers anywhere online!Free add-on: code for papers everywhere!Free add-on: See code for papers anywhere!
 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeSimplifying Random Forests: On the Trade-off between Interpretability and Accuracy
Paper and Code
Nov 11, 2019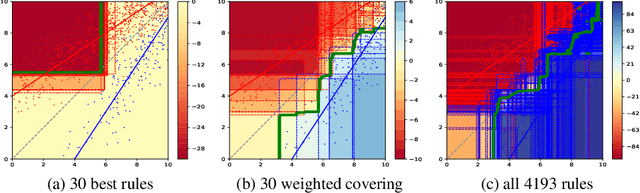
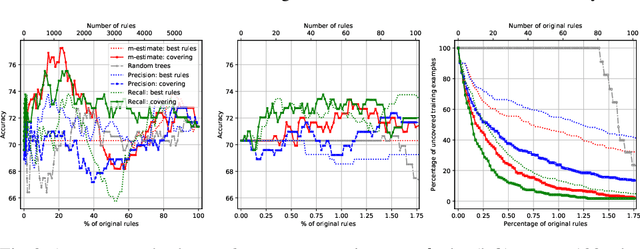
We analyze the trade-off between model complexity and accuracy for random forests by breaking the trees up into individual classification rules and selecting a subset of them. We show experimentally that already a few rules are sufficient to achieve an acceptable accuracy close to that of the original model. Moreover, our results indicate that in many cases, this can lead to simpler models that clearly outperform the original ones.
View paper on