 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeAIBench: An Industry Standard AI Benchmark Suite from Internet Services
Apr 30, 2020
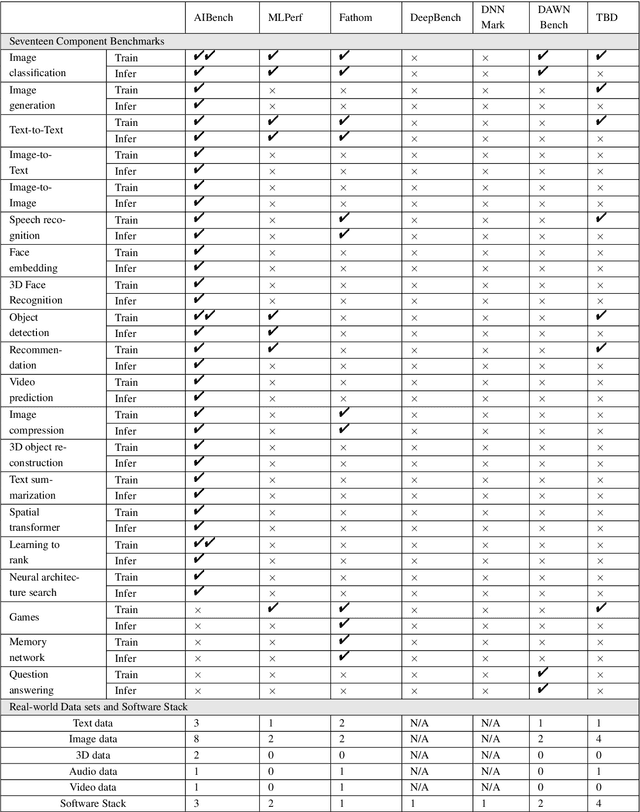
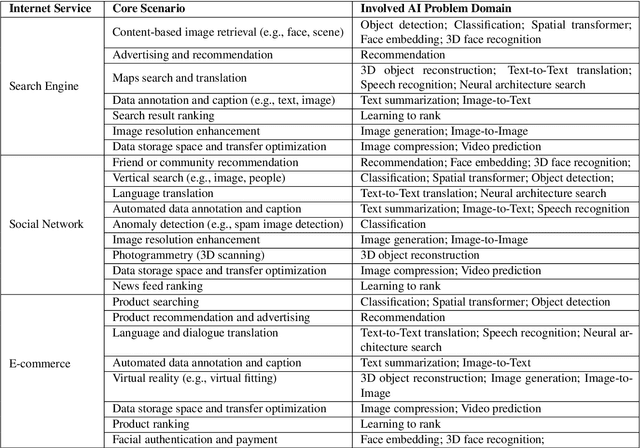
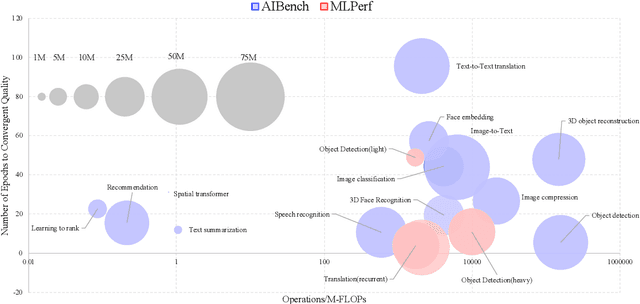
The booming successes of machine learning in different domains boost industry-scale deployments of innovative AI algorithms, systems, and architectures, and thus the importance of benchmarking grows. However, the confidential nature of the workloads, the paramount importance of the representativeness and diversity of benchmarks, and the prohibitive cost of training a state-of-the-art model mutually aggravate the AI benchmarking challenges. In this paper, we present a balanced AI benchmarking methodology for meeting the subtly different requirements of different stages in developing a new system/architecture and ranking/purchasing commercial off-the-shelf ones. Performing an exhaustive survey on the most important AI domain-Internet services with seventeen industry partners, we identify and include seventeen representative AI tasks to guarantee the representativeness and diversity of the benchmarks. Meanwhile, for reducing the benchmarking cost, we select a benchmark subset to a minimum-three tasks-according to the criteria: diversity of model complexity, computational cost, and convergence rate, repeatability, and having widely-accepted metrics or not. We contribute by far the most comprehensive AI benchmark suite-AIBench. The evaluations show AIBench outperforms MLPerf in terms of the diversity and representativeness of model complexity, computational cost, convergent rate, computation and memory access patterns, and hotspot functions. With respect to the AIBench full benchmarks, its subset shortens the benchmarking cost by 41%, while maintaining the primary workload characteristics. The specifications, source code, and performance numbers are publicly available from the web site http://www.benchcouncil.org/AIBench/index.html.
AIBench: An Agile Domain-specific Benchmarking Methodology and an AI Benchmark Suite
Feb 17, 2020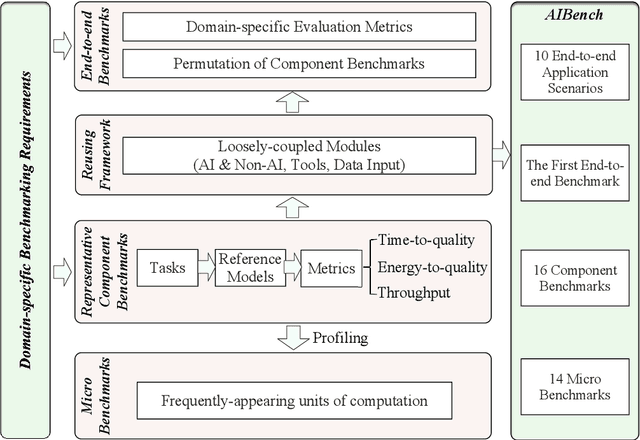
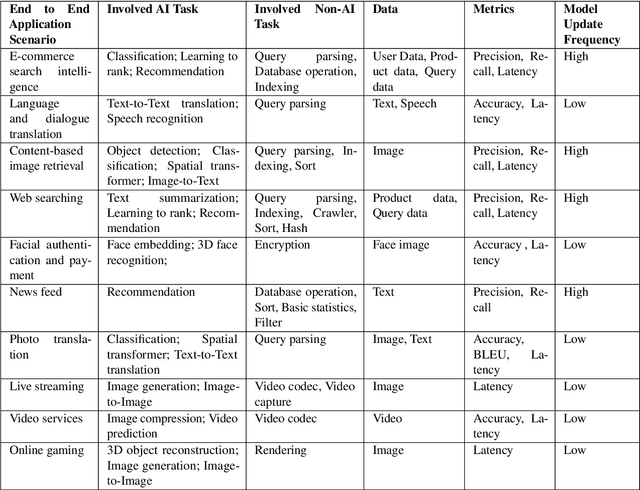

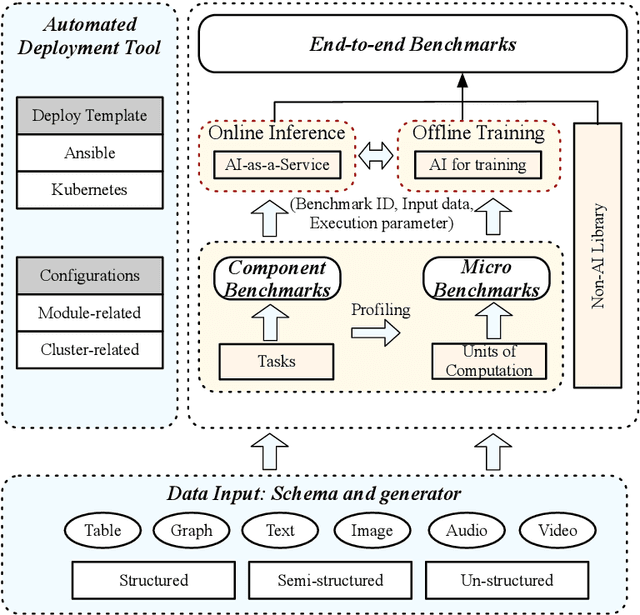
Domain-specific software and hardware co-design is encouraging as it is much easier to achieve efficiency for fewer tasks. Agile domain-specific benchmarking speeds up the process as it provides not only relevant design inputs but also relevant metrics, and tools. Unfortunately, modern workloads like Big data, AI, and Internet services dwarf the traditional one in terms of code size, deployment scale, and execution path, and hence raise serious benchmarking challenges. This paper proposes an agile domain-specific benchmarking methodology. Together with seventeen industry partners, we identify ten important end-to-end application scenarios, among which sixteen representative AI tasks are distilled as the AI component benchmarks. We propose the permutations of essential AI and non-AI component benchmarks as end-to-end benchmarks. An end-to-end benchmark is a distillation of the essential attributes of an industry-scale application. We design and implement a highly extensible, configurable, and flexible benchmark framework, on the basis of which, we propose the guideline for building end-to-end benchmarks, and present the first end-to-end Internet service AI benchmark. The preliminary evaluation shows the value of our benchmark suite---AIBench against MLPerf and TailBench for hardware and software designers, micro-architectural researchers, and code developers. The specifications, source code, testbed, and results are publicly available from the web site \url{http://www.benchcouncil.org/AIBench/index.html}.
A new direction to promote the implementation of artificial intelligence in natural clinical settings
May 08, 2019



Artificial intelligence (AI) researchers claim that they have made great `achievements' in clinical realms. However, clinicians point out the so-called `achievements' have no ability to implement into natural clinical settings. The root cause for this huge gap is that many essential features of natural clinical tasks are overlooked by AI system developers without medical background. In this paper, we propose that the clinical benchmark suite is a novel and promising direction to capture the essential features of the real-world clinical tasks, hence qualifies itself for guiding the development of AI systems, promoting the implementation of AI in real-world clinical practice.